This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Whether it’s customer transactions, IoT sensor readings, or just an endless stream of social media hot takes, you need a reliable way to get that data from point A to point B while doing something clever with it along the way. That’s where datapipeline design patterns come in. Data Mesh Pattern 8.
It sounds great, but how do you prove the data is correct at each layer? How do you ensure data quality in every layer ? Bronze, Silver, and Gold – The Data Architecture Olympics? The Bronze layer is the initial landing zone for all incoming rawdata, capturing it in its unprocessed, original form.
Datapipelines are the backbone of your business’s data architecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. We’ll answer the question, “What are datapipelines?” Table of Contents What are DataPipelines?
Here’s how Snowflake Cortex AI and Snowflake ML are accelerating the delivery of trusted AI solutions for the most critical generative AI applications: Natural language processing (NLP) for datapipelines: Large language models (LLMs) have a transformative potential, but they often batch inference integration into pipelines, which can be cumbersome.
What is Data Transformation? Data transformation is the process of converting rawdata into a usable format to generate insights. It involves cleaning, normalizing, validating, and enriching data, ensuring that it is consistent and ready for analysis.
For each data logs table, we initiate a new worker task that fetches the relevant metadata describing how to correctly query the data. Once we know what to query for a specific table, we create a task for each partition that executes a job in Dataswarm (our datapipeline system).
Data integration is an integral part of modern business strategy, enabling businesses to convert rawdata into actionable information and make data-driven decisions. However, its technical complexities and steeper learning curve can create a challenge for teams that require an efficient real-time datapipeline.
The demands of building, scaling, and maintaining datapipelines have grown increasingly complex and error-prone. Data engineers are now drowning in repetitive tasks, aspiring to drive data-backed decisions. Traditional approaches to building these pipelines have showcased their vulnerabilities.
With these points in mind, I argue that the biggest hurdle to the widespread adoption of these advanced techniques in the healthcare industry is not intrinsic to the industry itself, or in any way related to its practitioners or patients, but simply the current lack of high-quality datapipelines. What makes a good DataPipeline?
Reading Time: 7 minutes In today’s data-driven world, efficient datapipelines have become the backbone of successful organizations. These pipelines ensure that data flows smoothly from various sources to its intended destinations, enabling businesses to make informed decisions and gain valuable insights.
As a result, data has to be moved between the source and destination systems and this is usually done with the aid of datapipelines. What is a DataPipeline? A datapipeline is a set of processes that enable the movement and transformation of data from different sources to destinations.
7 DataPipeline Examples: ETL, Data Science, eCommerce, and More Joseph Arnold July 6, 2023 What Are DataPipelines? Datapipelines are a series of data processing steps that enable the flow and transformation of rawdata into valuable insights for businesses.
Datapipelines are a significant part of the big data domain, and every professional working or willing to work in this field must have extensive knowledge of them. Table of Contents What is a DataPipeline? The Importance of a DataPipeline What is an ETL DataPipeline?
Observability in Your DataPipeline: A Practical Guide Eitan Chazbani June 8, 2023 Achieving observability for datapipelines means that data engineers can monitor, analyze, and comprehend their datapipeline’s behavior. This is part of a series of articles about data observability.
But let’s be honest, creating effective, robust, and reliable datapipelines, the ones that feed your company’s reporting and analytics, is no walk in the park. From building the connectors to ensuring that data lands smoothly in your reporting warehouse, each step requires a nuanced understanding and strategic approach.
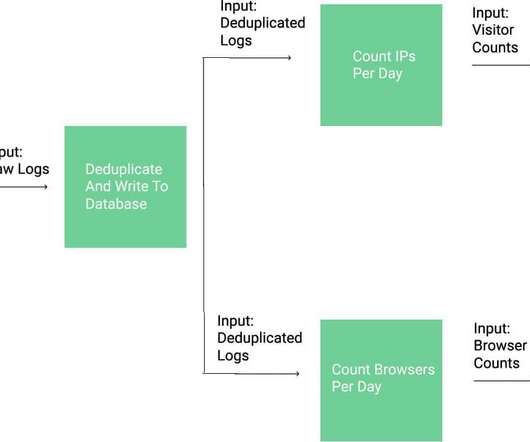
If you’ve ever wanted to learn Python online with streaming data, or data that changes quickly, you may be familiar with the concept of a datapipeline. Datapipelines allow you transform data from one representation to another through a series of steps. We store the raw log data to a database.
As you do not want to start your development with uncertainty, you decide to go for the operational rawdata directly. Accessing Operational Data I used to connect to views in transactional databases or APIs offered by operational systems to request the rawdata. Does it sound familiar?
Datapipelines are integral to business operations, regardless of whether they are meticulously built in-house or assembled using various tools. As companies become more data-driven, the scope and complexity of datapipelines inevitably expand. Ready to fortify your data management practice?
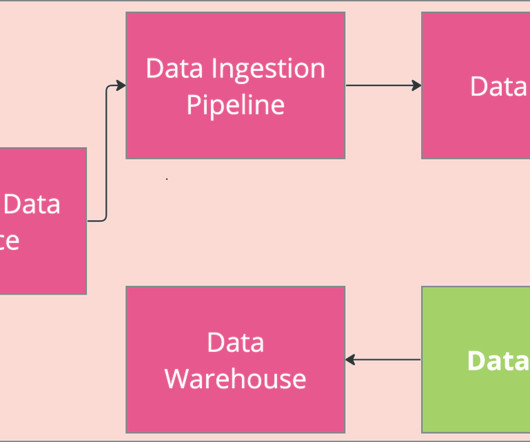
Data ingestion When we think about the flow of data in a pipeline, data ingestion is where the data first enters our platform. There are two primary types of rawdata. And data orchestration tools are generally easy to stand-up for initial use-cases. Missed Nishith’s 5 considerations?
A star-studded baseball team is analogous to an optimized “end-to-end datapipeline” — both require strategy, precision, and skill to achieve success. Just as every play and position in baseball is key to a win, each component of a datapipeline is integral to effective data management.
Faster, easier AI/ML and data engineering workflows Explore, analyze and visualize data using Python and SQL. Discover valuable business insights through exploratory data analysis. Develop scalable datapipelines and transformations for data engineering.
We’ll discuss batch data processing, the limitations we faced, and how Psyberg emerged as a solution. Furthermore, we’ll delve into the inner workings of Psyberg, its unique features, and how it integrates into our datapipelining workflows. The fact tables then feed downstream intraday pipelines that process the data hourly.
The data industry has a wide variety of approaches and philosophies for managing data: Inman data factory, Kimball methodology, s tar schema , or the data vault pattern, which can be a great way to store and organize rawdata, and more. Data mesh does not replace or require any of these.
Right now we’re focused on rawdata quality and accuracy because it’s an issue at every organization and so important for any kind of analytics or day-to-day business operation that relies on data — and it’s especially critical to the accuracy of AI solutions, even though it’s often overlooked.
After the hustle and bustle of extracting data from multiple sources, you have finally loaded all your data to a single source of truth like the Snowflake data warehouse. However, data modeling is still challenging and critical for transforming your rawdata into any analysis-ready form to get insights.
In this post, we will help you quickly level up your overall knowledge of datapipeline architecture by reviewing: Table of Contents What is datapipeline architecture? Why is datapipeline architecture important? What is datapipeline architecture? Why is datapipeline architecture important?
The Ten Standard Tools To Develop DataPipelines In Microsoft Azure. While working in Azure with our customers, we have noticed several standard Azure tools people use to develop datapipelines and ETL or ELT processes. We counted ten ‘standard’ ways to transform and set up batch datapipelines in Microsoft Azure.
In machine learning, a data scientist derives features from various data sources to build a model that makes predictions based on historical data. Integration with datapipelines — Teams that have already built datapipelines in dbt can continue to use these with the Snowflake Feature Store.
Microsoft offers a leading solution for business intelligence (BI) and data visualization through this platform. It empowers users to build dynamic dashboards and reports, transforming rawdata into actionable insights. Its flexibility suits advanced users creating end-to-end data solutions.
Given that you can version your data and track all of the modifications made to it in a manner that allows for traversal of those changesets, how much additional storage is necessary over and above the original capacity needed for the rawdata? What are some things that users should be aware of to help mitigate this?
Managing complex datapipelines is a major challenge for data-driven organizations looking to accelerate analytics initiatives. When created, Snowflake materializes query results into a persistent table structure that refreshes whenever underlying data changes. Now, that’s changing.
From this research, we developed a framework with a sequence of stages to implement data integrity quickly and measurably via datapipelines. Table of Contents Why does data integrity matter? At every level of a business, individuals must trust the data, so they can confidently make timely decisions. Let’s explore!
Those coveted insights live at the end of a process lovingly known as the datapipeline. The pathway from ETL to actionable analytics can often feel disconnected and cumbersome, leading to frustration for data teams and long wait times for business users. Keep reading to see how it works.
Preamble Hello and welcome to the Data Engineering Podcast, the show about modern data infrastructure When you’re ready to launch your next project you’ll need somewhere to deploy it. Go to dataengineeringpodcast.com to subscribe to the show, sign up for the newsletter, read the show notes, and get in touch.
It’s designed to be user-friendly, customizable, and extensible, making it a valuable tool for data engineers, analysts, and data-driven organizations looking to streamline their datapipelines. With its drag-and-drop interface, creating datapipelines becomes as easy as arranging blocks in a puzzle.
Dataform enables the application of software engineering best practices such as testing, environments, version control, dependencies management, orchestration and automated documentation to datapipelines. It is a serverless, SQL workflow orchestration workhorse within GCP.
In the same way that application performance monitoring ensures reliable software and keeps application downtime at bay, Monte Carlo solves the costly problem of broken datapipelines. constraints on data manipulation, security, privacy concerns, etc.) How does Unomi help with the new third party data restrictions ?
The six steps are: Data Collection – data ingestion and monitoring at the edge (whether the edge be industrial sensors or people in a brick and mortar retail store). Data Enrichment – datapipeline processing, aggregation & management to ready the data for further refinement.
Data Engineering is typically a software engineering role that focuses deeply on data – namely, data workflows, datapipelines, and the ETL (Extract, Transform, Load) process. What is the role of a Data Engineer? Data scientists and data Analysts depend on data engineers to build these datapipelines.
First and foremost, we designed the Cloudera Data Platform (CDP) to optimize every step of what’s required to go from rawdata to AI use cases. CDP enables a fully integrated and seamless ML lifecycle — from datapipelines to production and everything in between.
The client needed to build its own internal datapipeline with enough flexibility to meet the business requirements for a job market analysis platform & dashboard. The client intends to build on and improve this datapipeline by moving towards a more serverless architecture and adding DevOps tools & workflows.
The client needed to build its own internal datapipeline with enough flexibility to meet the business requirements for a job market analysis platform & dashboard. The client intends to build on and improve this datapipeline by moving towards a more serverless architecture and adding DevOps tools & workflows.
You work hard to make sure that your data is clean, reliable, and reproducible throughout the ingestion pipeline, but what happens when it gets to the data warehouse? Dataform picks up where your ETL jobs leave off, turning rawdata into reliable analytics.
Summary The most complicated part of data engineering is the effort involved in making the rawdata fit into the narrative of the business. Your newly mimicked datasets are safe to share with developers, QA, data scientists—heck, even distributed teams around the world.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content