This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Building efficient datapipelines with DuckDB 4.1. Use DuckDB to process data, not for multiple users to access data 4.2. Cost calculation: DuckDB + Ephemeral VMs = dirt cheap data processing 4.3. Processing data less than 100GB? Introduction 2. Project demo 3. Use DuckDB 4.4.
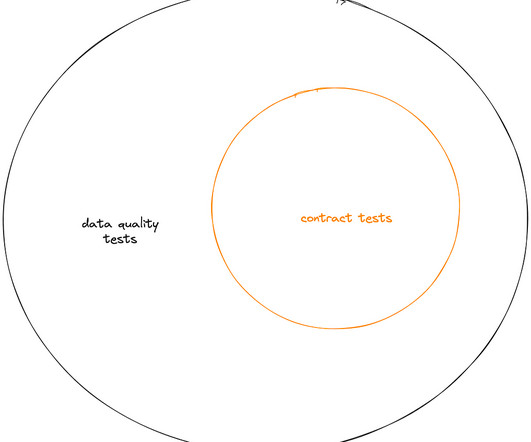
Introduction Testing your datapipeline 1. End-to-end system testing 2. Data quality testing 3. Unit and contract testing Conclusion Further reading Introduction Testing datapipelines are different from testing other applications, like a website backend. Monitoring and alerting 4.
Why Future-Proofing Your DataPipelines Matters Data has become the backbone of decision-making in businesses across the globe. The ability to harness and analyze data effectively can make or break a company’s competitive edge. Resilience and adaptability are the cornerstones of a future-proof datapipeline.
Whether it’s customer transactions, IoT sensor readings, or just an endless stream of social media hot takes, you need a reliable way to get that data from point A to point B while doing something clever with it along the way. That’s where datapipeline design patterns come in. Data Mesh Pattern 8.
Adding high-quality entity resolution capabilities to enterprise applications, services, data fabrics or datapipelines can be daunting and expensive. This will help you decide whether to build an in-house entity resolution system or utilize an existing solution like the Senzing® API for entity resolution.
Were explaining the end-to-end systems the Facebook app leverages to deliver relevant content to people. At Facebooks scale, the systems built to support and overcome these challenges require extensive trade-off analyses, focused optimizations, and architecture built to allow our engineers to push for the same user and business outcomes.
by Jasmine Omeke , Obi-Ike Nwoke , Olek Gorajek Intro This post is for all data practitioners, who are interested in learning about bootstrapping, standardization and automation of batch datapipelines at Netflix. You may remember Dataflow from the post we wrote last year titled Datapipeline asset management with Dataflow.
However, we've found that this vertical self-service model doesn't work particularly well for datapipelines, which involve wiring together many different systems into end-to-end data flows. Datapipelines power foundational parts of LinkedIn's infrastructure, including replication between data centers.
Get More Insights In Your Inbox Spencer Cook, Senior Solutions Architect at Databricks, joins to unpack how enterprises are moving beyond hype and building practical AI systems using vector search, RAG, and real-time datapipelines.
Summary Any software system that survives long enough will require some form of migration or evolution. When that system is responsible for the data layer the process becomes more challenging. Sriram Panyam has been involved in several projects that required migration of large volumes of data in high traffic environments.
Summary The first step of datapipelines is to move the data to a place where you can process and prepare it for its eventual purpose. Data transfer systems are a critical component of data enablement, and building them to support large volumes of information is a complex endeavor.
Understand source data] Know what you have to work with 2.3. Model your data] Define data models for historical analytics 2.4. Pipeline design] Design datapipelines to populate your data models 2.5. Data quality] Ensure you quality check your data before usage 2.
In this fast-paced digital era, multiple sources like IoT devices, social media platforms, and financial systems generate the data continuously and in real-time. Every business wants to analyze these data in real-time to be ahead in the competitive game. It has the ability to […]
Delivering the right events at low latency and with a high volume is critical to Picnic’s system architecture. In our previous blog, Dima Kalashnikov explained how we configure our Internal services pipeline in the Analytics Platform. In this post, we will explain how our team automates the creation of new datapipeline deployments.
DataPipeline Observability: A Model For Data Engineers Eitan Chazbani June 29, 2023 Datapipeline observability is your ability to monitor and understand the state of a datapipeline at any time. We believe the world’s datapipelines need better data observability.
In this article, Ill share how even the best AI applications can break, and share how leading teams are managing reliability at scale across the ever-evolving data + AI estate. Theres endless ways a data source can and does change, and its unavoidable for owners of datapipelines and products to be occasionally surprised by it.
APIs are a way to communicate between systems on the Internet 2.1. API Data extraction = GET-ting data from a server 3.1. GET data 3.1.1. GET data for a specific entity 3. Introduction 2. HTTP is a protocol commonly used for websites 2.1.1. Request: Ask the Internet exactly what you want 2.1.2.
Datapipelines are the backbone of your business’s data architecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. We’ll answer the question, “What are datapipelines?” Table of Contents What are DataPipelines?
In this episode Ian Schweer shares his experiences at Riot Games supporting player-focused features such as machine learning models and recommeder systems that are deployed as part of the game binary. The biggest challenge with modern datasystems is understanding what data you have, where it is located, and who is using it.
Recognizing this shortcoming and the capabilities that could be unlocked by a robust solution Rishabh Poddar helped to create Opaque Systems as an outgrowth of his PhD studies. Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code. When is Opaque the wrong choice?
However, leveraging AI agents like Striims Sherlock and Sentinel, which enable encryption and masking for PII, can help ensure that data is safe even in the event a breach occurs. Systems must be capable of handling high-velocity data without bottlenecks. As you can see, theres a lot to consider in adopting real-time AI.
Data transformations as functions lead to maintainable code 3. Track connections & configs when connecting to external systems 3.2. Track pipeline progress (logging, Observer) with objects 3.3. Use objects to store configurations of datasystems (e.g., Templatize data flow patterns with a Class 4.
Business success is based on how we use continuously changing data. That’s where streaming datapipelines come into play. This article explores what streaming datapipelines are, how they work, and how to build this datapipeline architecture. What is a streaming datapipeline?
At scale with dozens of data engineers building hundreds of production jobs, controlling their performance at scale is untenable for a myriad of reasons from technical to human. The missing link today is the establishment of a closed loop feedback system that helps automatically drive pipeline infrastructure towards business goals.
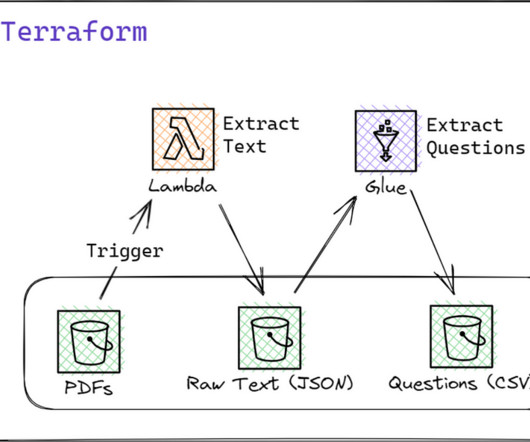
I know the manual work you did last summer Photo by EJ Yao on Unsplash Introduction A few weeks ago, I wrote a post about developing a datapipeline using both on-premise and AWS tools. This post is part of my recent effort in bringing more cloud-oriented data engineering posts. Adding a module to the Glue job Our main.tf
As a data or analytics engineer, you knew where to find all the transformation logic and models because they were all in the same codebase. You probably work closely with the colleague who builds the datapipeline that you were consuming. There was only one data team, two at most. How did they do it?
ERP and CRM systems are designed and built to fulfil a broad range of business processes and functions. This generalisation makes their data models complex and cryptic and require domain expertise. As you do not want to start your development with uncertainty, you decide to go for the operational raw data directly.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Dagster offers a new approach to building and running data platforms and datapipelines. What are the key points of comparison for that combination in relation to other possible selections?
On-premise and cloud working together to deliver a data product Photo by Toro Tseleng on Unsplash Developing a datapipeline is somewhat similar to playing with lego, you mentalize what needs to be achieved (the data requirements), choose the pieces (software, tools, platforms), and fit them together. Google Cloud.
The Machine Learning Platform (MLP) team at Netflix provides an entire ecosystem of tools around Metaflow , an open source machine learning infrastructure framework we started, to empower data scientists and machine learning practitioners to build and manage a variety of ML systems. ETL workflows), as well as downstream (e.g.
Here’s how Snowflake Cortex AI and Snowflake ML are accelerating the delivery of trusted AI solutions for the most critical generative AI applications: Natural language processing (NLP) for datapipelines: Large language models (LLMs) have a transformative potential, but they often batch inference integration into pipelines, which can be cumbersome.
AI data engineers play a critical role in developing and managing AI-powered datasystems. Table of Contents What Does an AI Data Engineer Do? AI data engineers are data engineers that are responsible for developing and managing datapipelines that support AI and GenAI data products.
The answer lies in unstructured data processing—a field that powers modern artificial intelligence (AI) systems. Unlike neatly organized rows and columns in spreadsheets, unstructured data—such as text, images, videos, and audio—requires advanced processing techniques to derive meaningful insights.
Snowflake enables organizations to be data-driven by offering an expansive set of features for creating performant, scalable, and reliable datapipelines that feed dashboards, machine learning models, and applications. But before data can be transformed and served or shared, it must be ingested from source systems.
As we look towards 2025, it’s clear that data teams must evolve to meet the demands of evolving technology and opportunities. In this blog post, we’ll explore key strategies that data teams should adopt to prepare for the year ahead. Tool sprawl is another hurdle that data teams must overcome.
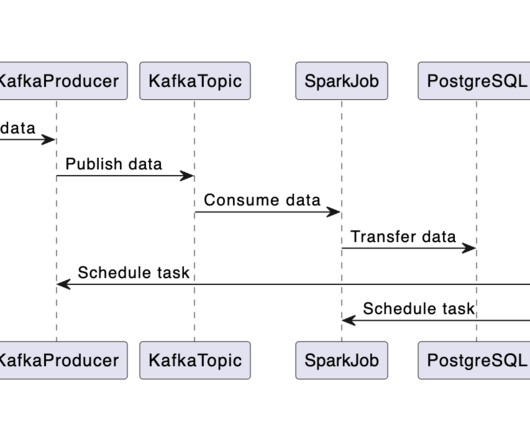
The first phase focuses on building a datapipeline. This involves getting data from an API and storing it in a PostgreSQL database. Overview Let’s break down the datapipeline process step-by-step: Data Streaming: Initially, data is streamed from the API into a Kafka topic. Image by the author.
Airflow Sensors are one of the most common tasks in datapipelines. If you want to make complex and robust datapipelines, you have to understand how Sensors work genuinely. Back to your datapipeline: Image your DAG runs every day at midnight but the files from sources A, B, and C, never come. It depends.
By enabling advanced analytics and centralized document management, Digityze AI helps pharmaceutical manufacturers eliminate data silos and accelerate data sharing. KAWA Analytics Digital transformation is an admirable goal, but legacy systems and inefficient processes hold back many companies efforts.
To meet this need, people who work in data engineering will focus on making systems that can handle ongoing data streams with little delay. Cloud-Native Data Engineering These days, cloud-based systems are the best choice for data engineering infrastructure because they are flexible and can grow as needed.
Monte Carlo and Databricks double-down on their partnership, helping organizations build trusted AI applications by expanding visibility into the datapipelines that fuel the Databricks Data Intelligence Platform. For too long, data teams have been flying blind when it comes to AI systems.
The Bronze layer is the initial landing zone for all incoming raw data, capturing it in its unprocessed, original form. This foundational layer is a repository for various data types, from transaction logs and sensor data to social media feeds and system logs. However, this architecture is not without its challenges.
If the underlying data is incomplete, inconsistent, or delayed, even the most advanced AI models and business intelligence systems will produce unreliable insights. Many organizations struggle with: Inconsistent data formats : Different systems store data in varied structures, requiring extensive preprocessing before analysis.
Summary Stream processing systems have long been built with a code-first design, adding SQL as a layer on top of the existing framework. In this episode Yingjun Wu explains how it is architected to power analytical workflows on continuous data flows, and the challenges of making it responsive and scalable.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Dagster offers a new approach to building and running data platforms and datapipelines. How do you manage the personalization of the AI functionality in your system for each user/team?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content