This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Businesses need to understand the trends in datapreparation to adapt and succeed. If you input poor-quality data into an AI system, the results will be poor. This principle highlights the need for careful datapreparation, ensuring that the input data is accurate, consistent, and relevant.
The Critical Role of AI Data Engineers in a Data-Driven World How does a chatbot seamlessly interpret your questions? The answer lies in unstructured dataprocessing—a field that powers modern artificial intelligence (AI) systems. How does a self-driving car understand a chaotic street scene?
Cortex AI delivers exceptional quality across a wide range of unstructured dataprocessing tasks through models and specialized functions tailored for different tasks. Get started: Dive into unstructured dataprocessing with our multimodal analytics quickstart. Explore Snowflake Cortex AI COMPLETE Multimodal today.
Before loading the data to Snowflake with sub-second latency, Striim allows users to perform in-line transformations, including denormalization, filtering, enrichment and masking, using a SQL-based language. In-flight dataprocessing reduces the time needed for datapreparation as it delivers the data in a consumable form.
While Pandas is the library for dataprocessing in Python, it isn't really built for speed. Learn more about the new library, Modin, developed to distribute Pandas' computation to speedup your data prep.
But with the start of the 21st century, when data started to become big and create vast opportunities for business discoveries, statisticians were rightfully renamed into data scientists. Data scientists today are business-oriented analysts who know how to shape data into answers, often building complex machine learning models.
Particularly, we’ll explain how to obtain audio data, prepare it for analysis, and choose the right ML model to achieve the highest prediction accuracy. But first, let’s go over the basics: What is the audio analysis, and what makes audio data so challenging to deal with. Audio datapreparation.
Machine Learning in AWS SageMaker Machine learning in AWS SageMaker involves steps facilitated by various tools and services within the platform: DataPreparation: SageMaker comprises tools for labeling the data and data and feature transformation. What is Amazon SageMaker processing? Is SageMaker free in AWS?
On the other hand, data science is a technique that collects data from various resources for datapreparation and modeling for extensive analysis. Cloud Computing provides storage, scalable compute, and network bandwidth to handle substantial data applications.
CPUs and GPUs can be used in tandem for data engineering and data science workloads. A typical machine learning workflow involves datapreparation, model training, model scoring, and model fitting. To overcome this, practitioners often turn to NVIDIA GPUs to accelerate machine learning and deep learning workloads. .
It involves many moving parts, from datapreparation to building indexing and query pipelines. Luckily, this task looks a lot like the way we tackle problems that arise when connecting data. He has been working with data and has architected systems for more than 15 years as a freelance engineer and consultant.
DataOps involves collaboration between data engineers, data scientists, and IT operations teams to create a more efficient and effective data pipeline, from the collection of raw data to the delivery of insights and results. Another key difference is the types of tools and technologies used by DevOps and DataOps.
Python’s integration with Power BI offers a range of benefits: Enhanced Data Analysis : Python’s extensive libraries such as Pandas, NumPy, and SciPy enable advanced dataprocessing and statistical analysis that may be beyond Power BI’s built-in capabilities. Why Integrate Python with Power BI?
Hear me out – back in the on-premises days we had data loading processes that connect directly to our source system databases and perform huge data extract queries as the start of one long, monolithic data pipeline, resulting in our data warehouse. Finally – where we get our data from, is changing massively.
Data cleaning is like ensuring that the ingredients in a recipe are fresh and accurate; otherwise, the final dish won't turn out as expected. It's a foundational step in datapreparation, setting the stage for meaningful and reliable insights and decision-making. Generates clean scripts for further dataprocessing.
Azure Synapse Analytics Pipelines: Azure Synapse Analytics (formerly SQL Data Warehouse) provides data exploration, datapreparation, data management, and data warehousing capabilities. It provides data prep, management, and enterprise data warehousing tools. It does the job.
They then arrange the data in a suitable format that is simple to understand. Upkeep of databases: Data analysts contribute to the design and upkeep of database systems. Datapreparation: Because of flaws, redundancy, missing numbers, and other issues, data gathered from numerous sources is always in a raw format.
Serving: Delivering Data with Precision: The seamless process significantly enhances the user experience, allowing for intuitive data exploration and decision-making without requiring technical query language knowledge. The significance of GenAI 1.
Data Storage: The next step after data ingestion is to store it in HDFS or a NoSQL database such as HBase. HBase storage is ideal for random read/write operations, whereas HDFS is designed for sequential processes. DataProcessing: This is the final step in deploying a big data model. How to avoid the same.
AWS Glue is a widely-used serverless data integration service that uses automated extract, transform, and load ( ETL ) methods to preparedata for analysis. It offers a simple and efficient solution for dataprocessing in organizations. where it can be used to facilitate business decisions. You can use Glue's G.1X
Database management: Data engineers should be proficient in storing and managing data and working with different databases, including relational and NoSQL databases. Data modeling: Data engineers should be able to design and develop data models that help represent complex data structures effectively.
The pipelines and workflows that ingest data, process it and output charts, dashboards, or other analytics resemble a production pipeline. The execution of these pipelines is called data operations or data production. Data sources must deliver error-free data on time. Dataprocessing must work perfectly.
The collection and preparation of data used for analytics are achieved by building data pipelines that ingest raw data and transform it into useful formats leveraging cloud data platforms like Snowflake, Databricks, and Google BigQuery. Changes in one pipeline often cascade down to different teams and projects.
Organisations are constantly looking for robust and effective platforms to manage and derive value from their data in the constantly changing landscape of data analytics and processing. These platforms provide strong capabilities for dataprocessing, storage, and analytics, enabling companies to fully use their data assets.
Tableau also provides flexible data refresh options, enabling me to schedule and manage data updates according to my preferences. Real-time DataProcessing Power BI supports real-time dataprocessing, a feature I find valuable for working with live data and obtaining immediate insights.
An Azure Data Engineer is responsible for designing, implementing, and maintaining data management and dataprocessing systems on the Microsoft Azure cloud platform. They work with large and complex data sets and are responsible for ensuring that data is stored, processed, and secured efficiently and effectively.
Source: The Data Team’s Guide to the Databricks Lakehouse Platform Integrating with Apache Spark and other analytics engines, Delta Lake supports both batch and stream dataprocessing. Besides that, it’s fully compatible with various data ingestion and ETL tools. Databricks two-plane infrastructure.
There are also client layers where all data management activities happen. When data is in place, it needs to be converted into the most digestible forms to get actionable results on analytical queries. For that purpose, different dataprocessing options exist. This, in turn, makes it possible to processdata in parallel.
Hadoop’s significance in data warehousing is progressing rapidly as a transitory platform for extract, transform, and load (ETL) processing. Mention about ETL and eyes glaze over Hadoop as a logical platform for datapreparation and transformation as it allows them to manage huge volume, variety, and velocity of data flawlessly.
Business Intelligence: Business Intelligence can handle moderate to large volumes of structured data. While it may not be designed specifically for big dataprocessing, it can integrate with dataprocessing technologies to analyze substantial amounts of data.
Snowflake Data Marketplace gives users rapid access to various third-party data sources. Moreover, numerous sources offer unique third-party data that is instantly accessible when needed. Snowflake's machine learning partners transfer most of their automated feature engineering down into Snowflake's cloud data platform.
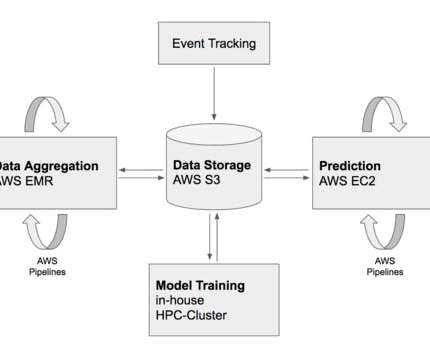
Moving deep-learning machinery into production requires regular data-aggregation-, model-training- and prediction-tasks. DataPreparation Before any machine learning is applied, data has to be gathered and organized to fit the input format of the machine learning model.
The transformation components can involve a wide array of operations such as data augmentation, filtering, grouping, aggregation, standardization, sorting, deduplication, validation, and verification. The goal is to cleanse, merge, and optimize the data, preparing it for insightful analysis and informed decision-making.
Snowpark is our secure deployment and processing of non-SQL code, consisting of two layers: Familiar Client Side Libraries – Snowpark brings deeply integrated, DataFrame-style programming and OSS compatible APIs to the languages data practitioners like to use.
Salary (Average) $135,094 per year (Source: Talent.com) Top Companies Hiring Deloitte, IBM, Capgemini Certifications Microsoft Certified: Azure Solutions Architect Expert Job Role 3: Azure Big Data Engineer The focus of Azure Big Data Engineers is developing and implementing big data solutions with the use of the Microsoft Azure platform.
Preparingdata for analysis is known as extract, transform and load (ETL). While the ETL workflow is becoming obsolete, it still serves as a common word for the datapreparation layers in a big data ecosystem. Working with large amounts of data necessitates more preparation than working with less data.
Microsoft Azure Data Engineers who take the Microsoft Azure Data Engineer Associate (DP-203) exam should combine data from different structured and unstructured data systems into structures used to construct analytics solutions. This real-world data engineering project has three steps.
Marketing Analytics: ETL pipelines can be used to extract data from various marketing channels, convert it into an analysis-friendly format, and upload it to a marketing analytics platform for campaign analysis, attribution models, and audience segmentation.
In the data fabric vs data lake dilemma, everything is simple. Data lakes are central repositories that can ingest and store massive amounts of both structured and unstructured data, typically for future analysis, big dataprocessing , and machine learning. A data fabric, on the contrary, doesn’t store data.
Databricks runs on an optimized Spark version and gives you the option to select GPU-enabled clusters, making it more suitable for complex dataprocessing. On the other hand, thanks to the Spark component, you can perform datapreparation, data engineering, ETL, and machine learning tasks using industry-standard Apache Spark.
Due to the enormous amount of data being generated and used in recent years, there is a high demand for data professionals, such as data engineers, who can perform tasks such as data management, data analysis, datapreparation, etc.
Pig Hadoop dominates the big data infrastructure at Yahoo as 60% of the processing happens through Apache Pig Scripts. The team at Facebook realized this roadblock which led to an open source innovation - Apache Hive in 2008 and since then it is extensively used by various Hadoop users for their dataprocessing needs.
In addition to analytics and data science, RAPIDS focuses on everyday datapreparation tasks. With SQL, machine learning, real-time data streaming, graph processing, and other features, this leads to incredibly rapid big dataprocessing. It comes with programming interfaces for entire clusters.
Also, experience is required in software development, dataprocesses, and cloud platforms. . Data Analysts: With the growing scope of data and its utility in economics and research, the role of data analysts has risen.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























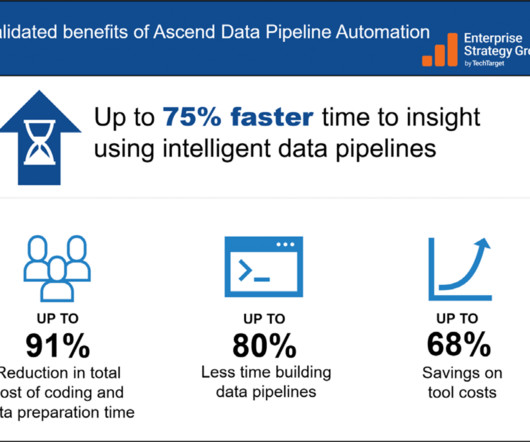
























Let's personalize your content