This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
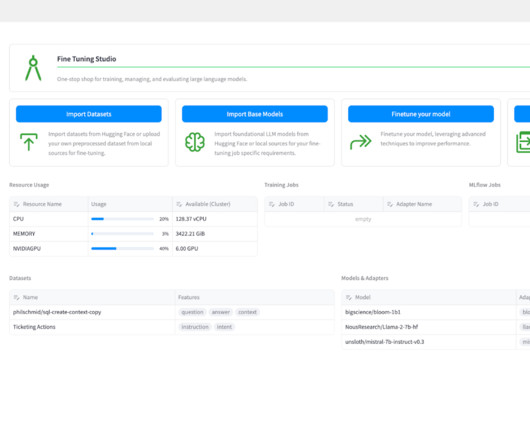
Fine Tuning Studio enables users to track the location of all datasets, models, and model adapters for training and evaluation. DataPreparation. We can import this dataset on the Import Datasets page. Let’s name our prompt better-ticketing and use our bitext dataset as the base dataset for the prompt.
For example: Text Data: Natural Language Processing (NLP) techniques are required to handle the subtleties of human language, such as slang, abbreviations, or incomplete sentences. Images and Videos: Computer vision algorithms must analyze visual content and deal with noisy, blurry, or mislabeled datasets.
Williams on Unsplash Data pre-processing is one of the major steps in any Machine Learning pipeline. Tensorflow Transform helps us achieve it in a distributed environment over a huge dataset. This dataset is free to use for commercial and non-commercial purposes. A description of the dataset is shown in the below figure.
Level 2: Understanding your dataset To find connected insights in your business data, you need to first understand what data is contained in the dataset. This is often a challenge for business users who arent familiar with the source data. Thats where ThoughtSpots architecture comes in.
Businesses need to understand the trends in datapreparation to adapt and succeed. If you input poor-quality data into an AI system, the results will be poor. This principle highlights the need for careful datapreparation, ensuring that the input data is accurate, consistent, and relevant.
To address these challenges, Company implements a three-layer architecture : RAW Layer : Stores ingested data directly from source systems without transformations. SILVER Layer : Cleansed and enriched dataprepared for analytical processing. Built clean, enriched datasets in the SILVER layer.
An open-source AI-driven data quality testing that learns from your data automatically while providing a simple UI, not a code-specific DSL, to review, improve, and manage your data quality test estatea Test Generator. The Challenge of Writing Manual Data Quality Testing Organizations often have hundreds or thousands of tables.
Tableau Prep is a fast and efficient datapreparation and integration solution (Extract, Transform, Load process) for preparingdata for analysis in other Tableau applications, such as Tableau Desktop. simultaneously making raw data efficient to form insights. Connecting to Data Begin by selecting your dataset.
A lot of missing values in the dataset can affect the quality of prediction in the long run. Several methods can be used to fill the missing values and Datawig is one of the most efficient ones.
When created, Snowflake materializes query results into a persistent table structure that refreshes whenever underlying data changes. These tables provide a centralized location to host both your raw data and transformed datasets optimized for AI-powered analytics with ThoughtSpot.
Particularly, we’ll explain how to obtain audio data, prepare it for analysis, and choose the right ML model to achieve the highest prediction accuracy. But first, let’s go over the basics: What is the audio analysis, and what makes audio data so challenging to deal with. Labeling of audio data in Audacity.
Increase your confidence to perform data cleaning with a broader perspective of what datasets typically look like, and follow this toolbox of code snipets to make your data cleaning process faster and more efficient.
There are two main steps for preparingdata for the machine to understand. Any ML project starts with datapreparation. You can’t simply feed the system your whole dataset of emails and expect it to understand what you want from it. What should it be like and how to prepare a great one?
Nonetheless, it is an exciting and growing field and there can't be a better way to learn the basics of image classification than to classify images in the MNIST dataset. Table of Contents What is the MNIST dataset? Test the Trained Neural Network Visualizing the Test Results Ending Notes What is the MNIST dataset?
The platform converges data cataloging, data ingestion, data profiling, data tagging, data discovery, and data exploration into a unified platform, driven by metadata. Modak Nabu automates repetitive tasks in the datapreparation process and thus accelerates the datapreparation by 4x.
Then, based on this information from the sample, defect or abnormality the rate for whole dataset is considered. This process of inferring the information from sample data is known as ‘inferential statistics.’ A database is a structured data collection that is stored and accessed electronically.
Datapreparation for LOS prediction. As with any ML initiative, everything starts with data. The main sources of such data are electronic health record ( EHR ) systems which capture tons of important details. Yet, there’re a few essential things to keep in mind when creating a dataset to train an ML model.
In this tutorial, we show how to apply mathematical set operations (union, intersection, and difference) to Pandas DataFrames with the goal of easing the task of comparing the rows of two datasets.
GitHub Copilot Features AI-Powered Coding Assistant : Trained on a massive dataset of publicly available code, including GitHub repositories, it can generate functions, classes, and entire code blocks. Data Project Assistance : Helps streamline tasks in data-driven projects, including datapreparation, analysis, and visual output.
Construction engineer investigating his work — Stable diffusion Introduction In our previous publication, From Data Engineering to Prompt Engineering , we demonstrated how to utilize ChatGPT to solve datapreparation tasks. We will start out propagating the Database Schema and some example data to ChatGPT.
Regardless of the structure they eventually build, it’s usually composed of two types of specialists: builders, who use data in production, and analysts, who know how to make sense of data. Distinction between data scientists and engineers is similar. Data scientist’s responsibilities — Datasets and Models.
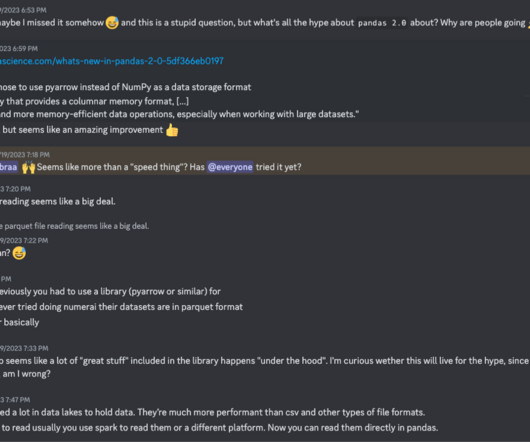
For that reason, one of the major limitations of pandas was handling in-memory processing for larger datasets. In this release, the big change comes from the introduction of the Apache Arrow backend for pandas data. X and allows us to conduct faster and more memory-efficient data operations, especially for larger datasets.
It enables models to stay updated by automatically retraining on incrementally larger and more recent data with a pre-defined periodicity. In content moderation classifier development, there are Data ETL (Export, Transform, Load) pipelines that collect data from various sources and store it in offline locations like a data lake or HDFS.
Advanced Data Cleaning and Transformation : Scenario : A financial institution needs to clean and preprocess large datasets with complex transformations. Solution : Utilize Python’s Pandas library to perform data wrangling tasks such as handling missing values, merging datasets, and applying complex transformations.
Power BI, Microsoft's cutting-edge business analytics solution, empowers users to visualize data and seamlessly distribute insights. However, the complex process of datapreparation, modeling, and report creation can be time and resource consuming, especially when handling intricate datasets.
What is Data Cleaning? Data cleaning, also known as data cleansing, is the essential process of identifying and rectifying errors, inaccuracies, inconsistencies, and imperfections in a dataset. It involves removing or correcting incorrect, corrupted, improperly formatted, duplicate, or incomplete data.
In this blog, we’ll explain why you should prepare your data before use in machine learning , how to clean and preprocess the data, and a few tips and tricks about datapreparation. Why PrepareData for Machine Learning Models? It may hurt it by adding in irrelevant, noisy data.
While it’s important to have the in-house data science expertise and the ML experts on-hand to build and test models, the reality is that the actual data science work — and the machine learning models themselves — are only one part of the broader enterprise machine learning puzzle. Laurence Goasduff, Gartner.
For machine learning algorithms to predict prices accurately, people who do the datapreparation must consider these factors and gather all this information to train the model. Data relevance. Data sources In developing hotel price prediction models, gathering extensive data from different sources is crucial.
Performance Aspect Power BI Tableau Speed of Data Rendering In my experience, Power BI exhibits commendable speed in rendering visualizations, particularly with smaller datasets. Tableau, on the other hand, stands out for its exceptional speed, ensuring swift rendering even when dealing with large and complex datasets.
Scale Existing Python Code with Ray Python is popular among data scientists and developers because it is user-friendly and offers extensive built-in data processing libraries. For analyzing huge datasets, they want to employ familiar Python primitive types. Then Redshift can be used as a data warehousing tool for this.
Training neural networks and implementing them into your classifier can be a cumbersome task since they require knowledge of deep learning and quite large datasets. Stating categories and collecting training dataset. Before a model can classify any documents, it has to be trained on historical data tagged with category labels.
Data testing tools: Key capabilities you should know Helen Soloveichik August 30, 2023 Data testing tools are software applications designed to assist data engineers and other professionals in validating, analyzing and maintaining data quality. There are several types of data testing tools.
On the other hand, data science is a technique that collects data from various resources for datapreparation and modeling for extensive analysis. Cloud Computing provides storage, scalable compute, and network bandwidth to handle substantial data applications.
You have a large dataset of labeled cat images, but you’re worried that it’s not enough. What if your model encounters a cat in the wild that’s sitting in a strange position or has a different fur color than anything in your dataset? Data augmentation in Python enhances dataset diversity for robust machine learning.
Time-saving: SageMaker automates many of the tasks, by creating a pipeline starting from datapreparation and ML model training, which saves time and resources. Analyze – Data Wrangler allows you to analyze the features in your dataset at any stage of the datapreparation process.
Companies want to spend less time on datapreparation and more time deriving insights from easy-to-access location reports. Build data integrity with accuracy and context. Ensuring data accuracy and context is essential. It’s time to make location data work for you. Enabling competitive advantage.
For machine learning models to predict ADR effectively, a comprehensive understanding of these variables is required in the datapreparation stage. Recognizing which factors to consider and which to exclude is a critical step in the datapreparation process. Data shortage and poor quality.
As you now know the key characteristics, it gets clear that not all data can be referred to as Big Data. What is Big Data analytics? Big Data analytics is the process of finding patterns, trends, and relationships in massive datasets that can’t be discovered with traditional data management techniques and tools.
Power BI Basics Microsoft Power BI is a business intelligence and data visualization software that is used to create interactive dashboards and business intelligence reports from various data sources. Dashboards, reports, workspace, datasets, and apps are the building blocks of power BI.
AI-based models are highly dependent on accurate, clean, well-labeled, and prepareddata in order to produce the desired output and cognition. These models are fed with bulky datasets covering an array of probabilities and computations to make its functioning as smart and gifted as human intelligence.
Over the years, the field of data engineering has seen significant changes and paradigm shifts driven by the phenomenal growth of data and by major technological advances such as cloud computing, data lakes, distributed computing, containerization, serverless computing, machine learning, graph database, etc.
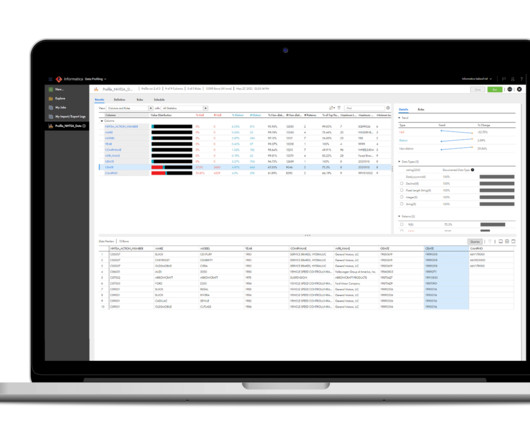
Data testing tools are software applications designed to assist data engineers and other professionals in validating, analyzing, and maintaining data quality. There are several types of data testing tools. Data profiling tools: Profiling plays a crucial role in understanding your dataset’s structure and content.
Top 20 Python Projects for Data Science Without much ado, it’s time for you to get your hands dirty with Python Projects for Data Science and explore various ways of approaching a business problem for data-driven insights. 1) Music Recommendation System on KKBox Dataset Music in today’s time is all around us.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content