This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A lot of missing values in the dataset can affect the quality of prediction in the long run. Several methods can be used to fill the missing values and Datawig is one of the most efficient ones.
But today’s programs, armed with machine learning and deeplearning algorithms, go beyond picking the right line in reply, and help with many text and speech processing problems. There are two main steps for preparingdata for the machine to understand. Any ML project starts with datapreparation.
Deeplearning is in the news. But deeplearning is a tool that enterprises use to solve practical problems. In this blog, we provide a few examples that show how organizations put deeplearning to work. In this blog, we provide a few examples that show how organizations put deeplearning to work.
Particularly, we’ll explain how to obtain audio data, prepare it for analysis, and choose the right ML model to achieve the highest prediction accuracy. But first, let’s go over the basics: What is the audio analysis, and what makes audio data so challenging to deal with. Labeling of audio data in Audacity.
The built-in algorithm learns from every case, enhancing its results over time. Datapreparation for LOS prediction. As with any ML initiative, everything starts with data. The main sources of such data are electronic health record ( EHR ) systems which capture tons of important details. Syntegra synthetic data.
Then, based on this information from the sample, defect or abnormality the rate for whole dataset is considered. This process of inferring the information from sample data is known as ‘inferential statistics.’ A database is a structured data collection that is stored and accessed electronically.
Nonetheless, it is an exciting and growing field and there can't be a better way to learn the basics of image classification than to classify images in the MNIST dataset. Table of Contents What is the MNIST dataset? Test the Trained Neural Network Visualizing the Test Results Ending Notes What is the MNIST dataset?
Namely, AutoML takes care of routine operations within datapreparation, feature extraction, model optimization during the training process, and model selection. To grasp how DevOps principles can be integrated into machine learning, read our article on MLOps methods and tools. In brief, AutoML promises to. AutoML use cases.
Data scientists and machine learning engineers often come across this scenario where the data for their project is not sufficient for training a machine learning model, often resulting in poor performance. Table of Contents What is Data Augmentation in DeepLearning?
Imagine you are training a machine learning model to classify images of cats. You have a large dataset of labeled cat images, but you’re worried that it’s not enough. What if your model encounters a cat in the wild that’s sitting in a strange position or has a different fur color than anything in your dataset?
Training neural networks and implementing them into your classifier can be a cumbersome task since they require knowledge of deeplearning and quite large datasets. Stating categories and collecting training dataset. We can label existing documents to use as our training dataset. Unsupervised text classification.
They come with strong backgrounds in computer science, mathematics, statistics, programming languages, and machine learning frameworks skills. What Do Machine Learning Software Engineers Do? Here are a few key Machine Learning software engineer responsibilities : 1.
Traditional processes determine the risk by manually looking at the applicant's income, credit history, and several other dynamic parameters and creating a data-driven risk model. Despite using data science in this process, there is still a large amount of manual work involved. Let's look at some of these datasets.
For machine learning algorithms to predict prices accurately, people who do the datapreparation must consider these factors and gather all this information to train the model. Data relevance. Data sources In developing hotel price prediction models, gathering extensive data from different sources is crucial.
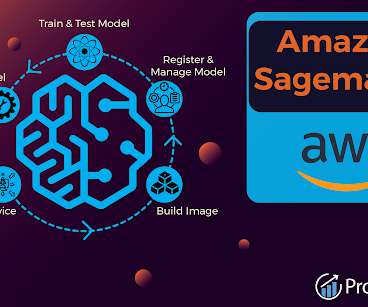
Integration with other AWS services: SageMaker integrates seamlessly with other services, such as Amazon Simple Storage Service(S3) and Amazon Elastic Compute Cloud (EC2), making it easy to incorporate machine learning into existing workflow and infrastructure. Amazon S3 is also used to store model artefacts and predictions.
It removes the issues related to the machine learning pipeline and provides an integrated setup for comprehensive model creation. SageMaker, on the other hand, works well with other AWS services and provides a sound foundation to deal with large datasets and computations effectively. FAQs What is Amazon SageMaker used for?
Azure’s AI services enable a wide range of AI capabilities, from machine learning and deeplearning to natural language processing and computer vision. Azure provides a powerful platform for building intelligent applications using advanced analytics, machine learning, and artificial intelligence.
Artificial Intelligence is achieved through the techniques of Machine Learning and DeepLearning. Machine Learning (ML) is a part of Artificial Intelligence. It builds a model based on Sample data and is designed to make predictions and decisions without being programmed for it. is highly beneficial.
The key terms that everyone should know within the spectrum of artificial intelligence are machine learning, deeplearning, computer vision , and natural language processing. DeepLearning is a subset of machine learning that focuses on building complex algorithms named deep neural networks.
Supervised vs unsupervised vs semi-supervised machine learning in a nutshell. Supervised learning is training a machine learning model using the labeled dataset. Organic labels are often available in data, but a process may involve a human expert that adds tags to raw data to show a model the target attributes (answers).
While more advanced techniques like deeplearning models can improve performance through fine-tuning and optimization, this is more limited with traditional methods, and model accuracy will likely plateau earlier. However, there are some limitations to using traditional approaches.
Datasetpreparation and construction. The starting point of any machine learning task is data. A lot of data, to be exact. A lot of quality data, to be even more exact. To learn the basics, you can read our dedicated article on how data is prepared for machine learning or watch a short video.
The various steps involved in the data analysis process include – Data Exploration – Having identified the business problem, a data analyst has to go through the data provided by the client to analyse the root cause of the problem. 5) What is data cleansing? How to create a sparse Matrix in Python?
Skills Required Skills necessary for AI engineers are programming languages, statistics, deeplearning, natural language processing, and problem-solving with communication skills. Average Annual Salary of Machine Learning Engineer A machine learning engineer can earn over $132,910 on average per year.
And if you are aspiring to become a data engineer, you must focus on these skills and practice at least one project around each of them to stand out from other candidates. Explore different types of Data Formats: A data engineer works with various dataset formats like.csv,josn,xlx, etc.
When people hear about artificial intelligence, deeplearning, and machine learning , many think of movie-like robots that resemble or even outperform human intelligence. Others believe that such machines simply consume information and learn from it by themselves. So, what challenges does data labeling involve?
Skills A data engineer should have good programming and analytical skills with big data knowledge. A machine learning engineer should know deeplearning, scaling on the cloud, working with APIs, etc. Examples Pull daily tweets from the data warehouse hive spreading in multiple clusters.
To further facilitate interoperability, Databricks developed Delta Sharing , an open protocol for the secure real-time exchange of large datasets, no matter which cloud or on-premises environment organizations use. Databricks Runtime for machine learning automatically creates a cluster configured for ML projects.
CompVis : The original source for Stable Diffusion, which is about deeplearning study and its uses. Integration with Hugging Face’s ecosystem for sharing models and datasets. Pretrained models like Stable Diffusion and Denoising Diffusion Probabilistic Models (DDPM) are built using large datasets.
As with other traditional machine learning and deeplearning paths, a lot of what the core algorithms can do depends upon the support they get from the surrounding infrastructure and the tooling that the ML platform provides. Their offline datapreparation ETLs run on Spark and they use Airflow as the orchestration layer.
as nn import torch.optim as optim from torch.utils.data import DataLoader from torchvision import datasets, transforms import matplotlib.pyplot as plt 2. Define the VAE Components Encoder The encoder maps the input data xx to the latent space zz : class Encoder(nn.Module): def __init__(self, input_dim, latent_dim): super(Encoder, self).
Databricks Snowflake Projects for Practice in 2022 Dive Deeper Into The Snowflake Architecture FAQs on Snowflake Architecture Snowflake Overview and Architecture With Data Explosion, acquiring, processing, and storing large or complicated datasets appears more challenging. Snowflake offers no built-in virtual private networking.
On the other hand, thanks to the Spark component, you can perform datapreparation, data engineering, ETL, and machine learning tasks using industry-standard Apache Spark. The platform’s massive parallel processing (MPP) architecture empowers you with high-performance querying of even massive datasets.
As with other traditional machine learning and deeplearning paths, a lot of what the core algorithms can do depends upon the support they get from the surrounding infrastructure and the tooling that the ML platform provides. Their offline datapreparation ETLs run on Spark and they use Airflow as the orchestration layer.
Particularly, we’ll present our findings on what it takes to prepare a medical image dataset, which models show best results in medical image recognition , and how to enhance the accuracy of predictions. Otherwise, let’s proceed to the first and most fundamental step in building AI-fueled computer vision tools — datapreparation.
Undoubtedly, everyone knows that the only best way to learndata science and machine learning is to learn them by doing diverse projects. Table of Contents What is a dataset in machine learning? Why you need machine learningdatasets? Where can I find datasets for machine learning?
Developing technical skills is essential, starting with foundational knowledge in mathematics, including calculus and linear algebra, which underpin machine learning and deeplearning concepts. A Data Scientist earns about 25% more than a computer programmer. What is Data in Data Science?
A big data project is a data analysis project that uses machine learning algorithms and different data analytics techniques on a large dataset for several purposes, including predictive modeling and other advanced analytics applications. Kicking off a big data analytics project is always the most challenging part.
Data Science has taken off in the technology space, the job title data scientist even being crowned as the Sexiest Job of the 21 st Century. Let's understand where Data Science belongs in the space of Artificial Intelligence. Auto-Weka : Weka is a top-rated java-based machine learning software for data exploration.
AI image generators are trained on an extensive amount of data, which comprises large datasets of images. Through the training process, the algorithms learn different aspects and characteristics of the images within the datasets. This labeled dataset is the “ground truth” that enables a feedback loop.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content