This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A lot of missing values in the dataset can affect the quality of prediction in the long run. Several methods can be used to fill the missing values and Datawig is one of the most efficient ones.
Introduction Data science has taken over all economic sectors in recent times. To achieve maximum efficiency, every company strives to use various data at every stage of its operations.
Deeplearning is in the news. But deeplearning is a tool that enterprises use to solve practical problems. In this blog, we provide a few examples that show how organizations put deeplearning to work. In this blog, we provide a few examples that show how organizations put deeplearning to work.
Deeplearning approaches have many advantages over traditional techniques, making them a great fit for our requirements. We have developed a deeplearning system based on RNNs and put it into production. We have developed a deeplearning system based on RNNs and put it into production.
We all have witnessed how Deeplearning has emerged as one of the most promising domains of artificial intelligence, enabling machines to process, analyze and draw insights from vast amounts of data. And hence, it has become significant to master some of the major deeplearning tools to work with this concept better.
But today’s programs, armed with machine learning and deeplearning algorithms, go beyond picking the right line in reply, and help with many text and speech processing problems. There are two main steps for preparingdata for the machine to understand. Any ML project starts with datapreparation.
Check out the top 6 data science trends in 2024 any data science enthusiast should know: 1. Advent of DeepLearning Simply put, deeplearning is a machine learning technique that trains computers to think and act like humans i.e., by example. What’s new for DeepLearning in 2024?
Particularly, we’ll explain how to obtain audio data, prepare it for analysis, and choose the right ML model to achieve the highest prediction accuracy. But first, let’s go over the basics: What is the audio analysis, and what makes audio data so challenging to deal with. Audio data analysis steps. Audio datapreparation.
This blog shows how text data representations can be used to build a classifier to predict a developer’s deeplearning framework of choice based on the code that they wrote, via examples of TensorFlow and PyTorch projects.
It means computers learn and there are many concepts, methods, algorithms and processes involved in making this happen. Let us try to understand some of the more important machine learning terms. Three concepts – artificial intelligence, machine learning and deeplearning – are often thought to be synonymous.
The built-in algorithm learns from every case, enhancing its results over time. Datapreparation for LOS prediction. As with any ML initiative, everything starts with data. Of course, you must decide on the general approach at the datapreparation stage as it will impact data labeling.
It is important to make use of this big data by processing it into something useful so that the organizations can use advanced analytics and insights to their advant age (generating better profits, more customer-reach, and so on). These steps will help understand the data, extract hidden patterns and put forward insights about the data.
Data science project cycle is composed of six phases: Business understanding Data understanding Datapreparation Modelling Evaluation Deployment This is the greater abstraction level of the Crisp-DM methodology, meaning one that can apply, with no exception, to all data problems.
Namely, AutoML takes care of routine operations within datapreparation, feature extraction, model optimization during the training process, and model selection. To grasp how DevOps principles can be integrated into machine learning, read our article on MLOps methods and tools. In brief, AutoML promises to. AutoML use cases.
To overcome this, practitioners often turn to NVIDIA GPUs to accelerate machine learning and deeplearning workloads. . CPUs and GPUs can be used in tandem for data engineering and data science workloads.
They come with strong backgrounds in computer science, mathematics, statistics, programming languages, and machine learning frameworks skills. What Do Machine Learning Software Engineers Do? Here are a few key Machine Learning software engineer responsibilities : 1.
Data scientists and machine learning engineers often come across this scenario where the data for their project is not sufficient for training a machine learning model, often resulting in poor performance. Table of Contents What is Data Augmentation in DeepLearning?
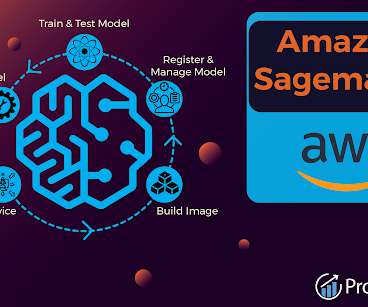
Machine Learning in AWS SageMaker Machine learning in AWS SageMaker involves steps facilitated by various tools and services within the platform: DataPreparation: SageMaker comprises tools for labeling the data and data and feature transformation. FAQs What is Amazon SageMaker used for?
Artificial Intelligence is achieved through the techniques of Machine Learning and DeepLearning. Machine Learning (ML) is a part of Artificial Intelligence. It builds a model based on Sample data and is designed to make predictions and decisions without being programmed for it. is highly beneficial.
Azure’s AI services enable a wide range of AI capabilities, from machine learning and deeplearning to natural language processing and computer vision. Azure provides a powerful platform for building intelligent applications using advanced analytics, machine learning, and artificial intelligence.
Automatic Speech Recognition: Data augmentation is being used to develop machine learning models that can be used for automatic speech recognition tasks, such as transcribing audio recordings and translating spoken languages. Data Pre-processing Data augmentation is just one part of datapreparation.
Skills Required Skills necessary for AI engineers are programming languages, statistics, deeplearning, natural language processing, and problem-solving with communication skills. Average Annual Salary of Machine Learning Engineer A machine learning engineer can earn over $132,910 on average per year.
The key terms that everyone should know within the spectrum of artificial intelligence are machine learning, deeplearning, computer vision , and natural language processing. DeepLearning is a subset of machine learning that focuses on building complex algorithms named deep neural networks.
While more advanced techniques like deeplearning models can improve performance through fine-tuning and optimization, this is more limited with traditional methods, and model accuracy will likely plateau earlier. However, there are some limitations to using traditional approaches.
To define the role of a Machine Learning Engineer , they are the professionals who go one step ahead to push or integrate the machine learning model into a system and bring it into an existing production environment. An essential skill for both the job roles is familiarity with various machine learning and deeplearning algorithms.
Nonetheless, it is an exciting and growing field and there can't be a better way to learn the basics of image classification than to classify images in the MNIST dataset. It can be used as a primary dataset for anyone trying to tackle a medical classification problem using deeplearning.
People who are unfamiliar with unprocessed data often find it difficult to navigate data lakes. Usually, raw, unstructured data needs to be analyzed and translated by a data scientist using specialized tools. . Remember, unstructured data is more flexible and scalable, which is often better for big data analytics.
Machine Learning Roles & Responsibilities: Machine learning expert is one of the most common jobs after artificial intelligence, where experts construct and instruct the learning of Artificial Intelligence (AI) systems through machine learning. Algorithms, datapreparation and model evaluations.
For machine learning algorithms to predict prices accurately, people who do the datapreparation must consider these factors and gather all this information to train the model. Data collection and preprocessing As with any machine learning task, it all starts with high-quality data that should be enough for training a model.
Integration with other AWS services: SageMaker integrates seamlessly with other services, such as Amazon Simple Storage Service(S3) and Amazon Elastic Compute Cloud (EC2), making it easy to incorporate machine learning into existing workflow and infrastructure. This library provided by SageMaker is similar in usage to Apache Spark MLLib.
Skills A data engineer should have good programming and analytical skills with big data knowledge. A machine learning engineer should know deeplearning, scaling on the cloud, working with APIs, etc. Examples Pull daily tweets from the data warehouse hive spreading in multiple clusters.
Traditional processes determine the risk by manually looking at the applicant's income, credit history, and several other dynamic parameters and creating a data-driven risk model. Despite using data science in this process, there is still a large amount of manual work involved.
Training neural networks and implementing them into your classifier can be a cumbersome task since they require knowledge of deeplearning and quite large datasets. Given the importance of the correct labeling, consider other options — like contacting companies that specialize in datapreparation.
There are two types of predictive algorithms available: those that use machine learning or those that use deeplearning. Data that is structured, such as spreadsheets or machine data, is used in machine learning (ML). Many data warehouses are not directly connected to systems that store user data.
As with other traditional machine learning and deeplearning paths, a lot of what the core algorithms can do depends upon the support they get from the surrounding infrastructure and the tooling that the ML platform provides. Their offline datapreparation ETLs run on Spark and they use Airflow as the orchestration layer.
Unlike supervised learning, the method uses small amounts of labeled data and further large amounts of unlabeled data, which reduces expenses on manual annotation and cuts datapreparation time. Speaking of supervised learning, we have an informed 14-min video explaining how data is prepared for it.
The open protocol is natively integrated with Unity Catalog, so customers can take advantage of governance capabilities and security controls when sharing data internally or externally. Databricks Runtime for machine learning automatically creates a cluster configured for ML projects.
The various steps involved in the data analysis process include – Data Exploration – Having identified the business problem, a data analyst has to go through the data provided by the client to analyse the root cause of the problem. How to save and reload a deeplearning model in Pytorch?
Data Science is integral to the job responsibilities assigned to an AI Engineer. The job of an AI Engineer comes with many responsibilities, including datapreparation , AI programming, algorithm design, data analytics, and a lot more. Machine Learning is one of the most important technologies in AI.
These roles have overlapping skills, but there is some difference between the three. The following table illustrates the key differences between these roles.
On the other hand, thanks to the Spark component, you can perform datapreparation, data engineering, ETL, and machine learning tasks using industry-standard Apache Spark. It supports both traditional ML algorithms and deeplearning frameworks, catering to a wide range of AI applications.
A lot of quality data, to be even more exact. To learn the basics, you can read our dedicated article on how data is prepared for machine learning or watch a short video. Datapreparation in 14 minutes. Data sources. Recurrent neural networks.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content