This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
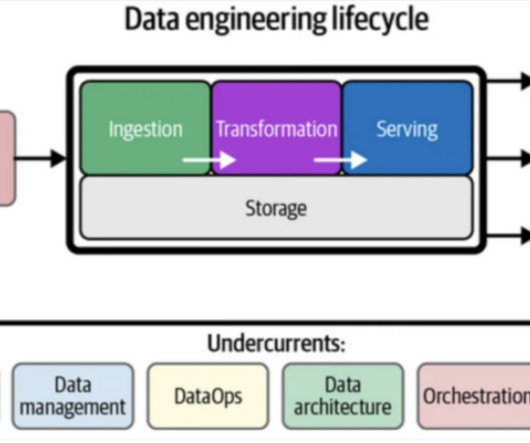
Data lakes are notoriously complex. For data engineers who battle to build and scale highqualitydata workflows on the data lake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics.
Businesses need to understand the trends in datapreparation to adapt and succeed. If you input poor-qualitydata into an AI system, the results will be poor. This principle highlights the need for careful datapreparation, ensuring that the input data is accurate, consistent, and relevant.
Current open-source frameworks like YAML-based Soda Core, Python-based Great Expectations, and dbt SQL are frameworks to help speed up the creation of dataquality tests. They are all in the realm of software, domain-specific language to help you write dataquality tests.
There are two main steps for preparingdata for the machine to understand. Any ML project starts with datapreparation. Plus, you likely won’t be able to use too much data. Assessing text dataquality. There are different views on what’s considered highqualitydata in different areas of application.
Azure Databricks Delta Live Table s: These provide a more straightforward way to build and manage Data Pipelines for the latest, high-qualitydata in Delta Lake. Power BI dataflows: Power BI dataflows are a self-service datapreparation tool. It does the job. Oozie is an open-source DAG runner.
A data fabric offers several key benefits that transform your data management: Accelerates analytics and decision-making processes by enhancing data accessibility through seamless data integration and retrieval across diverse environments.
Data cleaning is like ensuring that the ingredients in a recipe are fresh and accurate; otherwise, the final dish won't turn out as expected. It's a foundational step in datapreparation, setting the stage for meaningful and reliable insights and decision-making. Let's explore these essential tools.
For machine learning algorithms to predict prices accurately, people who do the datapreparation must consider these factors and gather all this information to train the model. Data collection and preprocessing As with any machine learning task, it all starts with high-qualitydata that should be enough for training a model.
Some of the value companies can generate from data orchestration tools include: Faster time-to-insights. Automated data orchestration removes data bottlenecks by eliminating the need for manual datapreparation, enabling analysts to both extract and activate data in real-time. Improved data governance.
DataQuality: Data Mining and BI rely on the availability of high-qualitydata. Both disciplines emphasize the importance of data accuracy, completeness, consistency, and reliability to ensure the reliability of the insights derived.
Thanks to the metadata in the knowledge graph and delivery suggestions from the recommendation engine, the data fabric understands the structure of data and the different intents of data consumers. As such, it can suggest different datapreparation or delivery types. Orchestration and DataOps.
Microsoft Certified: Azure Data Scientist Associate: This certification is designed for data scientists who use Azure Machine Learning to design and build models, and who use Azure Databricks to build, train, and deploy machine learning models. It covers topics such as data exploration, datapreparation, and feature engineering.
Due to the enormous amount of data being generated and used in recent years, there is a high demand for data professionals, such as data engineers, who can perform tasks such as data management, data analysis, datapreparation, etc.
Without proper datapreparation, you risk issues like bias and hallucination, inaccurate predictions, poor model performance, and more. “If If you do not have AI-ready data, then you’re more than likely to experience some of these challenges,” says Cotroneo.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content