This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Using nested data types in dataprocessing 3.3.1. STRUCT enables more straightforward dataschema and data access 3.3.2. Nested data types can be sorted 3.3.3. Use STRUCT for one-to-one & hierarchical relationships 3.2. Use ARRAY[STRUCT] for one-to-many relationships 3.3.
Read Time: 6 Minute, 6 Second In modern data pipelines, handling data in various formats such as CSV, Parquet, and JSON is essential to ensure smooth dataprocessing. However, one of the most common challenges faced by data engineers is the evolution of schemas as new data comes in.
Processing complex, schema-less, semistructured, hierarchical data can be extremely time-consuming, costly and error-prone, particularly if the data source has polymorphic attributes. For many data sources, the schema of the data source can change without warning.
AWS Glue is a widely-used serverless data integration service that uses automated extract, transform, and load ( ETL ) methods to prepare data for analysis. It offers a simple and efficient solution for dataprocessing in organizations. AWS Glue automates several processes as well. You can use Glue's G.1X
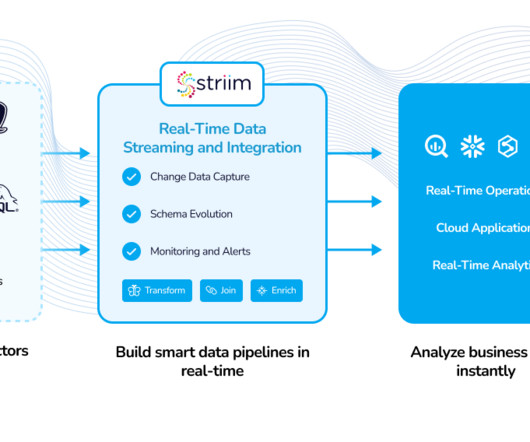
Furthermore, Striim also supports real-time data replication and real-time analytics, which are both crucial for your organization to maintain up-to-date insights. By efficiently handling data ingestion, this component sets the stage for effective dataprocessing and analysis.
The dataprocessing pipeline characterizes these objects, deriving key parameters such as brightness, color, ellipticity, and coordinate location, and broadcasts this information in alert packets. The data from these detections are then serialized into Avro binary format.
Delta Lake also refuses writes with wrongly formatted data (schema enforcement) and allows for schema evolution. Spark: The definitive guide: Big dataprocessing made simple. Delta Lake also works with the concept of ACID transactions, that is, no partial writing caused by job failures or inconsistent readings.
Even with feature parity as the north star, depending on the size of your data and complexity of the dataprocessing pipelines you could be looking at a multi-month, maybe even multi-quarter project for phase one—which is a lifetime in tech years. This could include FAQs, custom tooling, common libraries or dataschemas.
A Beginner’s Guide [SQ] Niv Sluzki July 19, 2023 ELT is a dataprocessing method that involves extracting data from its source, loading it into a database or data warehouse, and then later transforming it into a format that suits business needs. What is ELT (Extract, Load, Transform)? ELT vs. ETL: What Is the Difference?
BigQuery also offers native support for nested and repeated dataschema[4][5]. We take advantage of this feature in our ad bidding systems, maintaining consistent data views from our Account Specialists’ spreadsheets, to our Data Scientists’ notebooks, to our bidding system’s in-memory data.
show(truncate=False) #Drop duplicates on selected columns dropDisDF = df.dropDuplicates(["department","salary"]) print("Distinct count of department salary : "+str(dropDisDF.count())) dropDisDF.show(truncate=False) } Get FREE Access to Data Analytics Example Codes for Data Cleaning, Data Munging, and Data Visualization Q6.
And by leveraging distributed storage and open-source technologies, they offer a cost-effective solution for handling large data volumes. In other words, the data is stored in its raw, unprocessed form, and the structure is imposed when a user or an application queries the data for analysis or processing.
And by leveraging distributed storage and open-source technologies, they offer a cost-effective solution for handling large data volumes. In other words, the data is stored in its raw, unprocessed form, and the structure is imposed when a user or an application queries the data for analysis or processing.
And by leveraging distributed storage and open-source technologies, they offer a cost-effective solution for handling large data volumes. In other words, the data is stored in its raw, unprocessed form, and the structure is imposed when a user or an application queries the data for analysis or processing.
For example, you can learn about how JSONs are integral to non-relational databases – especially dataschemas, and how to write queries using JSON. Apache Spark Apache Spark In this lecture, you’ll learn about Spark – an open-source analytics engine for dataprocessing.
To mitigate this, in Python v2, we replaced the intermediate processing batches with Parquet storage and loaded the table once into the database, rather than after each batch. This strategy dramatically reduced processing time and network costs. Our answer to this challenge lay in big dataprocessing.
This problem is not new in dataprocessing. Although the Kafka Streams library is “dataschema agnostic” today and therefore cannot leverage many standard techniques from the query processing literature, such as predicate pushdown, there is still a large optimization room on structural topology formation for it to explore.
On the other hand, if you require advanced analytics, real-time processing, machine learning, and uncovering insights from diverse and large-scale datasets, a big data platform would be more appropriate. Scalability and Performance: Evaluate the scalability and performance requirements of your dataprocessing.
Marketing teams should have easy access to the analytical data they need for campaigns. Furthermore, the self-serve data infrastructure should include encryption, data product versioning, dataschema, and automation.
Data Storage: The next step after data ingestion is to store it in HDFS or a NoSQL database such as HBase. HBase storage is ideal for random read/write operations, whereas HDFS is designed for sequential processes. DataProcessing: This is the final step in deploying a big data model. How to avoid the same.
But persistent staging is typically more structured and integrated into your overall customer data pipeline. It’s not just a dumping ground for data, but a crucial step in your customer dataprocessing workflow. Your understanding of your customers will change, and your data model should be able to keep up.
Big Data Hadoop Interview Questions and Answers These are Hadoop Basic Interview Questions and Answers for freshers and experienced. Hadoop vs RDBMS Criteria Hadoop RDBMS Datatypes Processes semi-structured and unstructured data. Processes structured data. are all examples of unstructured data.
Pig vs Hive Criteria Pig Hive Type of Data Apache Pig is usually used for semi structured data. Used for Structured DataSchemaSchema is optional. Hive requires a well-defined Schema. Language It is a procedural data flow language. ORC files improve performance for reads, writes and dataprocessing.
The data engineering landscape is constantly changing but major trends seem to remain the same. How to Become a Data Engineer As a data engineer, I am tasked to design efficient dataprocesses almost every day. It was created by Spotify to manage massive dataprocessing workloads.
On the hardware side, the integration of specialized hardware like Graphics Processing Units (GPUs) and Tensor Processing Units (TPUs) into dataprocessing pipelines has revolutionized the speed at which data can be analyzed. Hardware acceleration Image from The Chip Letter.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content