This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Read Time: 6 Minute, 6 Second In modern data pipelines, handling data in various formats such as CSV, Parquet, and JSON is essential to ensure smooth dataprocessing. However, one of the most common challenges faced by data engineers is the evolution of schemas as new data comes in.
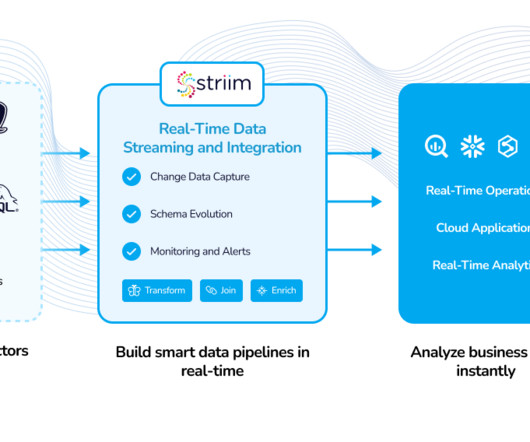
Striim, for instance, facilitates the seamless integration of real-time streaming data from various sources, ensuring that it is continuously captured and delivered to big datastorage targets. By efficiently handling data ingestion, this component sets the stage for effective dataprocessing and analysis.
AWS Glue is a widely-used serverless data integration service that uses automated extract, transform, and load ( ETL ) methods to prepare data for analysis. It offers a simple and efficient solution for dataprocessing in organizations. AWS Glue automates several processes as well. You can use Glue's G.1X
Concepts, theory, and functionalities of this modern datastorage framework Photo by Nick Fewings on Unsplash Introduction I think it’s now perfectly clear to everybody the value data can have. To use a hyped example, models like ChatGPT could only be built on a huge mountain of data, produced and collected over years.
A Beginner’s Guide [SQ] Niv Sluzki July 19, 2023 ELT is a dataprocessing method that involves extracting data from its source, loading it into a database or data warehouse, and then later transforming it into a format that suits business needs. The data is loaded as-is, without any transformation.
And by leveraging distributed storage and open-source technologies, they offer a cost-effective solution for handling large data volumes. In other words, the data is stored in its raw, unprocessed form, and the structure is imposed when a user or an application queries the data for analysis or processing.
And by leveraging distributed storage and open-source technologies, they offer a cost-effective solution for handling large data volumes. In other words, the data is stored in its raw, unprocessed form, and the structure is imposed when a user or an application queries the data for analysis or processing.
And by leveraging distributed storage and open-source technologies, they offer a cost-effective solution for handling large data volumes. In other words, the data is stored in its raw, unprocessed form, and the structure is imposed when a user or an application queries the data for analysis or processing.
For example, you can learn about how JSONs are integral to non-relational databases – especially dataschemas, and how to write queries using JSON. Apache Spark Apache Spark In this lecture, you’ll learn about Spark – an open-source analytics engine for dataprocessing.
This process involves data collection from multiple sources, such as social networking sites, corporate software, and log files. DataStorage: The next step after data ingestion is to store it in HDFS or a NoSQL database such as HBase. DataProcessing: This is the final step in deploying a big data model.
show(truncate=False) #Drop duplicates on selected columns dropDisDF = df.dropDuplicates(["department","salary"]) print("Distinct count of department salary : "+str(dropDisDF.count())) dropDisDF.show(truncate=False) } Get FREE Access to Data Analytics Example Codes for Data Cleaning, Data Munging, and Data Visualization Q6.
Big Data: Big data platforms utilize distributed file systems such as Hadoop Distributed File System ( HDFS ) for storing and managing large-scale distributed data. Data Warehouse or Big Data: Accepted Data Source Data Warehouse accepts various internal and external data sources.
Data consistency is ensured through uniform definitions and governance requirements across the organization, and a comprehensive communication layer allows other teams to discover the data they need. Marketing teams should have easy access to the analytical data they need for campaigns.
Big Data Hadoop Interview Questions and Answers These are Hadoop Basic Interview Questions and Answers for freshers and experienced. Hadoop vs RDBMS Criteria Hadoop RDBMS Datatypes Processes semi-structured and unstructured data. Processes structured data. are all examples of unstructured data.
But persistent staging is typically more structured and integrated into your overall customer data pipeline. It’s not just a dumping ground for data, but a crucial step in your customer dataprocessing workflow. You might choose a cloud data warehouse like the Snowflake AI Data Cloud or BigQuery.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content