This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Join the community in the new Zulip chat workspace at dataengineeringpodcast.com/chat Your host is Tobias Macey and today I’m interviewing Tom Kaitchuck about Pravega, an open source datastorage platform optimized for persistent streams Interview Introduction How did you get involved in the area of data management?
AI-powered data engineering solutions make it easier to streamline the data management process, which helps businesses find useful insights with little to no manual work. Real-time dataprocessing has emerged The demand for real-time data handling is expected to increase significantly in the coming years.
It means that there is a high risk of data loss but Apache Kafka solves this because it is distributed and can easily scale horizontally and other servers can take over the workload seamlessly. It offers a unified solution to real-time data needs any organisation might have. This is where Apache Kafka comes in.
Think of it as the “slow and steady wins the race” approach to dataprocessing. Stream Processing Pattern Now, imagine if instead of waiting to do laundry once a week, you had a magical washing machine that could clean each piece of clothing the moment it got dirty.
In addition, AI data engineers should be familiar with programming languages such as Python , Java, Scala, and more for data pipeline, data lineage, and AI model development. DataStorage Solutions As we all know, data can be stored in a variety of ways.
I finally found a good critique that discusses its flaws, such as multi-hop architecture, inefficiencies, high costs, and difficulties maintaining data quality and reusability. The article advocates for a "shift left" approach to dataprocessing, improving data accessibility, quality, and efficiency for operational and analytical use cases.
This episode promises invaluable insights into the shift from batch to real-time dataprocessing, and the practical applications across multiple industries that make this transition not just beneficial but necessary. Explore the intricate challenges and groundbreaking innovations in datastorage and streaming.
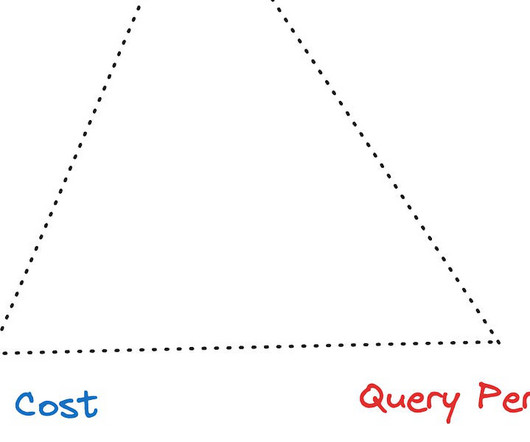
The paper discusses trade-offs among data freshness, resource cost, and query performance. Ref: [link] In the current state of the data infrastructure, we use a combination of multiple specialized datastorage and processing engines to achieve this balance. Presto tried with RaptorX. It doesn’t fly.
This module can ingest live data streams from multiple sources, including Apache Kafka , Apache Flume , Amazon Kinesis , or Twitter, splitting them into discrete micro-batches. Netflix leverages Spark Streaming and Kafka for near real-time movie recommendations. Big dataprocessing.
Big data is a term that refers to the massive volume of data that organizations generate every day. In the past, this data was too large and complex for traditional dataprocessing tools to handle. There are a variety of big dataprocessing technologies available, including Apache Hadoop, Apache Spark, and MongoDB.
Features of PySpark Features that contribute to PySpark's immense popularity in the industry- Real-Time Computations PySpark emphasizes in-memory processing, which allows it to perform real-time computations on huge volumes of data. PySpark is used to process real-time data with Kafka and Streaming, and this exhibits low latency.
If you want to break into the field of data engineering but don't yet have any expertise in the field, compiling a portfolio of data engineering projects may help. Data pipeline best practices should be shown in these initiatives. Source Code: Stock and Twitter Data Extraction Using Python, Kafka, and Spark 2.
He wrote some years ago 3 articles defining data engineering field. Some concepts When doing data engineering you can touch a lot of different concepts. formats — This is a huge part of data engineering. Picking the right format for your datastorage. Understand Change Data Capture — CDC.
Rockset continuously ingests data streams from Kafka, without the need for a fixed schema, and serves fast SQL queries on that data. We created the Kafka Connect Plugin for Rockset to export data from Kafka and send it to a collection of documents in Rockset. This blog covers how we implemented the plugin.
Hadoop and Spark are the two most popular platforms for Big Dataprocessing. They both enable you to deal with huge collections of data no matter its format — from Excel tables to user feedback on websites to images and video files. Obviously, Big Dataprocessing involves hundreds of computing units.
This involves connecting to multiple data sources, using extract, transform, load ( ETL ) processes to standardize the data, and using orchestration tools to manage the flow of data so that it’s continuously and reliably imported – and readily available for analysis and decision-making.
Vector Search and Unstructured DataProcessing Advancements in Search Architecture In 2024, organizations redefined search technology by adopting hybrid architectures that combine traditional keyword-based methods with advanced vector-based approaches.
Azure Data Engineering is a rapidly growing field that involves designing, building, and maintaining dataprocessing systems using Microsoft Azure technologies. Any Azure Data Engineer must have experience with Azure’s datastorage options, including Azure Cosmos DB, Azure Data Lake Storage, and Azure Blob Storage.
Let’s explore what to consider when thinking about data ingestion tools and explore the leading tools in the field. Consideration What to Look For Integration Capabilities Support for a diverse array of data sources and destinations, ensuring compatibility with your data ecosystem. Cost : It’s open-source software, so free.
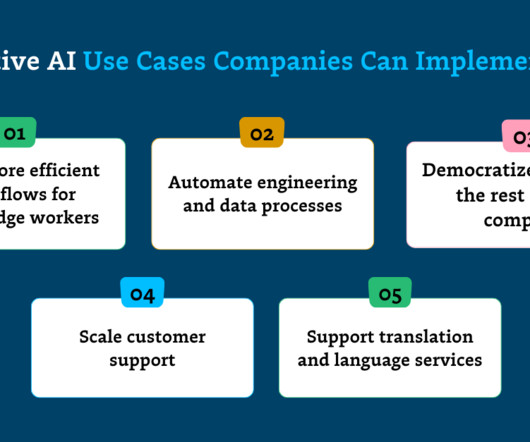
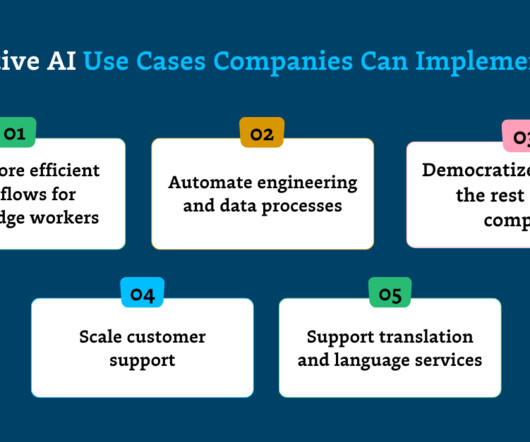
Automate engineering and dataprocesses By automating repetitive or mundane aspects of coding and data engineering, generative AI is streamlining workflows and driving productivity for software and data engineers alike. Tools like Tensorflow and HuggingFace are good options to fine-tune your models.
They are also accountable for communicating data trends. Let us now look at the three major roles of data engineers. Generalists They are typically responsible for every step of the dataprocessing, starting from managing and making analysis and are usually part of small data-focused teams or small companies.
Data engineers design, manage, test, maintain, store, and work on the data infrastructure that allows easy access to structured and unstructured data. Data engineers need to work with large amounts of data and maintain the architectures used in various data science projects. Technical Data Engineer Skills 1.Python
Data modeling: Data engineers should be able to design and develop data models that help represent complex data structures effectively. Dataprocessing: Data engineers should know dataprocessing frameworks like Apache Spark, Hadoop, or Kafka, which help process and analyze data at scale.
A growing number of companies now use this data to uncover meaningful insights and improve their decision-making, but they can’t store and process it by the means of traditional datastorage and processing units. Key Big Data characteristics. Datastorage and processing.
Apache Kafka Amazon MSK and Kafka Under the Hood Apache Kafka is an open-source streaming platform. Learn about the AWS-managed Kafka offering in this course to see how it can be more quickly deployed. Apache Hadoop Introduction to Google Cloud Dataproc Hadoop allows for distributed processing of large datasets.
But with the start of the 21st century, when data started to become big and create vast opportunities for business discoveries, statisticians were rightfully renamed into data scientists. Data scientists today are business-oriented analysts who know how to shape data into answers, often building complex machine learning models.
As a result, data engineers working with big data today require a basic grasp of cloud computing platforms and tools. Businesses can employ internal, public, or hybrid clouds depending on their datastorage needs, including AWS, Azure, GCP, and other well-known cloud computing platforms.
Because of this, all businesses—from global leaders like Apple to sole proprietorships—need Data Engineers proficient in SQL. NoSQL – This alternative kind of datastorage and processing is gaining popularity. Data Engineers must be proficient in Python to create complicated, scalable algorithms.
As the volume and complexity of data continue to grow, organizations seek faster, more efficient, and cost-effective ways to manage and analyze data. In recent years, cloud-based data warehouses have revolutionized dataprocessing with their advanced massively parallel processing (MPP) capabilities and SQL support.
Data-Arks serves as a vital component in integrating Large Language Models (LLMs) into the analytics workflow, streamlining processes like generating regular metric reports and conducting fraud investigations [link]. The author categorizes these queries into four types: append-only, upsert, min-delta (CDC), and full-delta (CDC).
Data engineering design patterns are repeatable solutions that help you structure, optimize, and scale dataprocessing, storage, and movement. They make data workflows more resilient and easier to manage when things inevitably go sideways. Popular tools include Apache Kafka , Apache Flink , and AWS Kinesis.
Here are some role-specific skills to consider if you want to become an Azure data engineer: Programming languages are used in the majority of datastorage and processing systems. Data engineers must be well-versed in programming languages such as Python, Java, and Scala.
With SQL, machine learning, real-time data streaming, graph processing, and other features, this leads to incredibly rapid big dataprocessing. DataFrames are used by Spark SQL to accommodate structured and semi-structured data. CMAK is developed to help the Kafka community.
Organisations are constantly looking for robust and effective platforms to manage and derive value from their data in the constantly changing landscape of data analytics and processing. These platforms provide strong capabilities for dataprocessing, storage, and analytics, enabling companies to fully use their data assets.
Here are some role-specific skills you should consider to become an Azure data engineer- Most datastorage and processing systems use programming languages. Data engineers must thoroughly understand programming languages such as Python, Java, or Scala. Who should take the certification exam?
Defining Architecture Components of the Big Data Ecosystem Core Hadoop Components 3) MapReduce- Distributed DataProcessing Framework of Apache Hadoop MapReduce Use Case: >4)YARN Key Benefits of Hadoop 2.0 2) Hadoop Distributed File System (HDFS) - The default big datastorage layer for Apache Hadoop is HDFS.
Understanding data modeling concepts like entity-relationship diagrams, data normalization, and data integrity is a requirement for an Azure Data Engineer. You ought to be able to create a data model that is performance- and scalability-optimized. The certification cost is $165 USD.
The primary process comprises gathering data from multiple sources, storing it in a database to handle vast quantities of information, cleaning it for further use and presenting it in a comprehensible manner. Data engineering involves a lot of technical skills like Python, Java, and SQL (Structured Query Language).
BI (Business Intelligence) Strategies and systems used by enterprises to conduct data analysis and make pertinent business decisions. Big Data Large volumes of structured or unstructured data. Big Query Google’s cloud data warehouse. Flat File A type of database that stores data in a plain text format.
Key Benefits and Takeaways: Understand data intake strategies and data transformation procedures by learning data engineering principles with Python. Investigate alternative datastorage solutions, such as databases and data lakes. Key Benefits and Takeaways: Learn the core concepts of big data systems.
Use Cases of Real-time Ingestion Real-time ingestion provides organizations with infrastructure for implementing various data capture, dataprocessing and data analyzing tools. Here are some key uses of real-time data ingestion: 1. Like IoT devices, sensors, social media platforms, financial data, etc.
Automate engineering and dataprocesses By automating repetitive or mundane aspects of coding and data engineering, generative AI is streamlining workflows and driving productivity for software and data engineers alike. Tools like Tensorflow and HuggingFace are good options to fine-tune your models.
Datastorage is a vital aspect of any Snowflake Data Cloud database. Within Snowflake, data can either be stored locally or accessed from other cloud storage systems. Amazon S3 for AWS, Azure Blob Storage for Azure, or Google Cloud Storage for GCP) to store the actual data files in micro-partitions.
Who is Azure Data Engineer? An Azure Data Engineer is a professional who is in charge of designing, implementing, and maintaining dataprocessing systems and solutions on the Microsoft Azure cloud platform. CSV, SQL Server), transform it, and load it into a target storage (e.g.,
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content