This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Recommended actions: Establish secure, scalable connections to data sources like APIs, databases, or third-party tools. DataProcessing and Transformation With raw data flowing in, it’s time to make it useful. Key questions: What transformations are needed to prepare data for analysis?
Let’s set the scene: your company collects data, and you need to do something useful with it. Whether it’s customer transactions, IoT sensor readings, or just an endless stream of social media hot takes, you need a reliable way to get that data from point A to point B while doing something clever with it along the way.
Table of Contents What is Real-Time Data Ingestion? Data Collection The first step is to collect real-time data (purchase_data) from various sources, such as sensors, IoT devices, and web applications, using data collectors or agents.
AWS DevOps offers an innovative and versatile set of services and tools that allow you to manage, scale, and optimize big data projects. With AWS DevOps, data scientists and engineers can access a vast range of resources to help them build and deploy complex dataprocessing pipelines, machine learning models, and more.
With global data creation expected to soar past 180 zettabytes by 2025, businesses face an immense challenge: managing, storing, and extracting value from this explosion of information. Traditional datastorage systems like data warehouses were designed to handle structured and preprocessed data.
Introduction to Teradata VantageCloud Lake on AWS Teradata VantageCloud Lake, a comprehensive data platform, serves as the foundation for our data mesh architecture on AWS. The data mesh architecture Key components of the data mesh architecture 1.
With SQL, machine learning, real-time data streaming, graph processing, and other features, this leads to incredibly rapid big dataprocessing. DataFrames are used by Spark SQL to accommodate structured and semi-structured data. Calcite has chosen to stay out of the datastorage and processing business.
Learn all about Azure ETL Tools in minutes with this quick guide, showcasing the top 7 Azure tools with their key features, pricing, and pros/cons for your dataprocessing needs. Many are turning to Azure ETL tools for their simplicity and efficiency, offering a seamless experience for easy data extraction, transformation, and loading.
This blog is your ultimate gateway to transforming yourself into a skilled and successful Big Data Developer, where your analytical skills will refine raw data into strategic gems. So, get ready to turn the turbulent sea of 'data chaos' into 'data artistry.' What industry is big data developer in?
Think of the data integration process as building a giant library where all your data's scattered notebooks are organized into chapters. You define clear paths for data to flow, from extraction (gathering structured/unstructured data from different systems) to transformation (cleaning the raw data, processing the data, etc.)
According to I DC’s Data Age Report , the digital universe is likely to reach 175 zettabytes by 2025, showing the exponential growth of data with the increasing complexity of analysis. It supports flexible instance and storage scaling to accommodate varying workloads.
Elevate your dataprocessing skills with Amazon Managed Streaming for Apache Kafka, making real-time data streaming a breeze. Deeply Integrated: Seamlessly integrate AWS Kafka with various AWS services, including analytics, storage, and machine learning offerings. billion in 2023 at a CAGR of 26.9%.
A data lake retains all data, including data currently in use, data that may be used and even data that may never actually be used, but there is some assumption that it may be of some help in the future. In Data lakes the schema is applied by the query and they do not have a rigorous schema like data warehouses.
AWS Glue is a widely-used serverless data integration service that uses automated extract, transform, and load ( ETL ) methods to prepare data for analysis. It offers a simple and efficient solution for dataprocessing in organizations. It was responsible for extracting data and categorizing it.
Skills Developed : Real-time dataprocessing with Kafka Building anomaly detection workflows Real-time visualization with Grafana 7) Weather Pattern Prediction Industries like agriculture, logistics, and disaster management need accurate weather predictions to reduce risks and improve operational planning.
Big data has taken over many aspects of our lives and as it continues to grow and expand, big data is creating the need for better and faster datastorage and analysis. These Apache Hadoop projects are mostly into migration, integration, scalability, data analytics, and streaming analysis.
With the proliferation of data sources, IoT devices, and edge nodes, almost 2.5 quintillion bytes of data is produced daily. This data is distributed across many platforms, including cloud databases, websites, CRM tools, social media channels, email marketing, etc.
AI data architecture is the integrated framework that governs how data is ingested, processed, stored, and managed to support artificial intelligence applications. Key components of AI data architecture An effective AI data architecture includes: 1.
According to Wasabi's 2023 Cloud Storage Index Executive Summary Report, Nearly 90% of respondents stated they had switched from on-premises to cloud storage solutions due to better system resilience, durability, and scalability. Storage Capacity : The pricing for Azure Blob Storage is based on the data stored in your account.
When combined with the distributed computing framework of Hadoop, businesses can leverage the scalability and parallel processing capabilities of Hadoop to efficiently manage and process their big data. Both structured and unstructured data in distributed file systems. Faster processing time for large data sets.
Since then, it has been used by companies operating in various industries to manage big data archives, providing a platform for them to build their own custom software services to store and processdata. Real-time data streaming also helps to reduce the amount of datastorage solutions needed.
Focussed on designing, building, and maintaining large-scale dataprocessing systems. Extract, transform, and load data into a target system. Works on datastorage and retrieval, dataprocessing, and data visualization. Works with databases, ETL tools, and scripting languages.
Features of GCP GCP offers services, including Machine learning analytics Application modernization Security Business Collaboration Productivity Management Cloud app development DataStorage, and management AWS - Amazon Web Services - An Overview Amazon Web Services is the largest cloud provider, developed and maintained by Amazon.
Data Engineer Interview Questions on Big Data Any organization that relies on data must perform big data engineering to stand out from the crowd. But data collection, storage, and large-scale dataprocessing are only the first steps in the complex process of big data analysis.
GCP Data Engineer Certification The Google Cloud Certified Professional Data Engineer certification is ideal for data professionals whose jobs generally involve data governance, data handling, dataprocessing, and performing a lot of feature engineering on data to prepare it for modeling.
Big data is often characterized by the seven V's: Volume , Variety , Velocity, Variability, Veracity, Visualization, and Value of data. Big data engineers leverage big data tools and technologies to process and engineer massive data sets or data stored in datastorage systems like databases and data lakes.
One of the leading cloud service providers, Amazon Web Services (AWS ), offers powerful tools and services that can propel your data analysis endeavors to new heights. With AWS, you gain access to scalable infrastructure, robust datastorage, and cutting-edge analytics capabilities.
Azure Stack Familiarize yourself with core Microsoft Azure data services such as Azure Data Lake, Azure Synapse, Azure Data Factory , Azure Cosmos DB, etc. According to the Microsoft Study Guide, you must focus on preparing the following topics: Describe core data concepts. Describe ways to represent data.
You can pick any of these cloud computing project ideas to develop and improve your skills in the field of cloud computing along with other big data technologies. The project emphasizes end-to-end testing of AWS Lambda functions and integration with DynamoDB for datastorage.
Data rights: People are entitled to see, amend, remove, and limit how their data is processed. DataProcessing Transparency: People need to know how their data is going to be used. Security: To safeguard personal information, data scientists need to put in place the proper security measures.
Starting with setting up an Azure Virtual Machine, you'll install necessary big data tools and configure Flume agents for log data ingestion. Utilizing Spark for dataprocessing and Hive for querying, you'll develop a comprehensive understanding of real-time log analysis in a cloud environment.
These platforms provide scalable infrastructure and services for machine learning, such as distributed training, model serving, and dataprocessing. An example of scalability in machine learning can be seen in the field of natural language processing ( NLP ).
It focuses on the following key areas- Core Data Concepts- Understanding the basics of data concepts, such as relational and non-relational data, structured and unstructured data, data ingestion, dataprocessing, and data visualization.
Using data analysis , you can build an advanced demand forecasting system that minimizes stockouts and overstock situations. Weather Data: Seasonal demand fluctuations (NOAA Climate Data). Social Media Trends: Consumer sentiment analysis (Twitter , Reddit APIs).
To help other people find the show please leave a review on iTunes , or Google Play Music , tell your friends and co-workers, and share it on social media. To help other people find the show please leave a review on iTunes , or Google Play Music , tell your friends and co-workers, and share it on social media.
Organisations and businesses are flooded with enormous amounts of data in the digital era. This information is gathered from a variety of sources, including sensor readings, social media engagements, and client transactions. Raw data, however, is frequently disorganised, unstructured, and challenging to work with directly.
Big data is a term that refers to the massive volume of data that organizations generate every day. In the past, this data was too large and complex for traditional dataprocessing tools to handle. There are a variety of big dataprocessing technologies available, including Apache Hadoop, Apache Spark, and MongoDB.
Striim, for instance, facilitates the seamless integration of real-time streaming data from various sources, ensuring that it is continuously captured and delivered to big datastorage targets. By efficiently handling data ingestion, this component sets the stage for effective dataprocessing and analysis.
It allows data scientists to analyze large datasets and interactively run jobs on them from the R shell. Big dataprocessing. For instance, social media platforms may use GraphX to analyze user connections and suggest potential friends. Here are some of the possible use cases.
If you want to break into the field of data engineering but don't yet have any expertise in the field, compiling a portfolio of data engineering projects may help. Data pipeline best practices should be shown in these initiatives. Source Code: Finnhub API with Kafka for Real-Time Financial Market Data Pipeline 3.
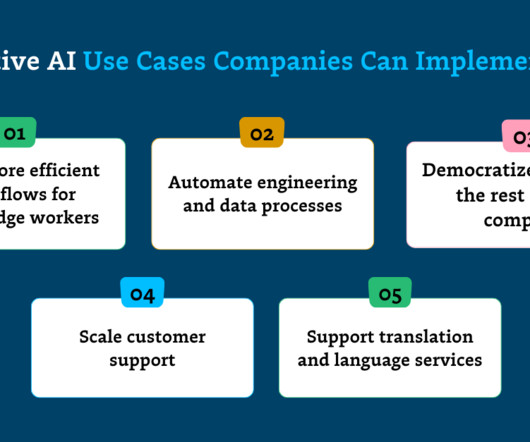
Automate engineering and dataprocesses By automating repetitive or mundane aspects of coding and data engineering, generative AI is streamlining workflows and driving productivity for software and data engineers alike. Even at OpenAI itself, LLMs are used to support DevOps and internal functions.
The history of big data takes people on an astonishing journey of big data evolution, tracing the timeline of big data. The Emergence of DataStorage and Processing Technologies A datastorage facility first appeared in the form of punch cards, developed by Basile Bouchon to facilitate pattern printing on textiles in looms.
Concepts, theory, and functionalities of this modern datastorage framework Photo by Nick Fewings on Unsplash Introduction I think it’s now perfectly clear to everybody the value data can have. To use a hyped example, models like ChatGPT could only be built on a huge mountain of data, produced and collected over years.
Unlike structured data, which is organized into neat rows and columns within a database, unstructured data is an unsorted and vast information collection. It can come in different forms, such as text documents, emails, images, videos, social media posts, sensor data, etc. Social media posts.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content