This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Rawdata, however, is frequently disorganised, unstructured, and challenging to work with directly. Dataprocessing analysts can be useful in this situation. Let’s take a deep dive into the subject and look at what we’re about to study in this blog: Table of Contents What Is DataProcessing Analysis?
Think of it as the “slow and steady wins the race” approach to dataprocessing. Stream Processing Pattern Now, imagine if instead of waiting to do laundry once a week, you had a magical washing machine that could clean each piece of clothing the moment it got dirty. The data lakehouse has got you covered!
Third-Party Data: External data sources that your company does not collect directly but integrates to enhance insights or support decision-making. These data sources serve as the starting point for the pipeline, providing the rawdata that will be ingested, processed, and analyzed.
Data science uses machine learning algorithms like Random Forests, K-nearest Neighbors, Naive Bayes, Regression Models, etc. They can categorize and cluster rawdata using algorithms, spot hidden patterns and connections in it, and continually learn and improve over time. These large data sets are referred to as "Big Data."
A Beginner’s Guide [SQ] Niv Sluzki July 19, 2023 ELT is a dataprocessing method that involves extracting data from its source, loading it into a database or data warehouse, and then later transforming it into a format that suits business needs. The data is loaded as-is, without any transformation.
A data engineer is an engineer who creates solutions from rawdata. A data engineer develops, constructs, tests, and maintains data architectures. Let’s review some of the big picture concepts as well finer details about being a data engineer. Earlier we mentioned ETL or extract, transform, load.
DataOps Architecture Legacy data architectures, which have been widely used for decades, are often characterized by their rigidity and complexity. These systems typically consist of siloed datastorage and processing environments, with manual processes and limited collaboration between teams.
The integration of data from separate sources becomes a self-consistent data set with the removal of duplications and flagging of inconsistencies or, if possible, their resolution. Datastorage uses a non-volatile environment with strict management controls on the modification and deletion of data.
Data engineering design patterns are repeatable solutions that help you structure, optimize, and scale dataprocessing, storage, and movement. They make data workflows more resilient and easier to manage when things inevitably go sideways. Data Lakes vs. Data Warehouses: Where Should Your Data Live?
This involves connecting to multiple data sources, using extract, transform, load ( ETL ) processes to standardize the data, and using orchestration tools to manage the flow of data so that it’s continuously and reliably imported – and readily available for analysis and decision-making.
Businesses benefit at large with these data collection and analysis as they allow organizations to make predictions and give insights about products so that they can make informed decisions, backed by inferences from existing data, which, in turn, helps in huge profit returns to such businesses. What is the role of a Data Engineer?
To choose the most suitable data management solution for your organization, consider the following factors: Data types and formats: Do you primarily work with structured, unstructured, or semi-structured data? Consider whether you need a solution that supports one or multiple data formats. only structured data).
To choose the most suitable data management solution for your organization, consider the following factors: Data types and formats: Do you primarily work with structured, unstructured, or semi-structured data? Consider whether you need a solution that supports one or multiple data formats. only structured data).
To choose the most suitable data management solution for your organization, consider the following factors: Data types and formats: Do you primarily work with structured, unstructured, or semi-structured data? Consider whether you need a solution that supports one or multiple data formats. only structured data).
The emergence of cloud data warehouses, offering scalable and cost-effective datastorage and processing capabilities, initiated a pivotal shift in data management methodologies. How ELT Works The process of ELT can be broken down into the following three stages: 1. What Is ELT? So, what exactly is ELT?
As the volume and complexity of data continue to grow, organizations seek faster, more efficient, and cost-effective ways to manage and analyze data. In recent years, cloud-based data warehouses have revolutionized dataprocessing with their advanced massively parallel processing (MPP) capabilities and SQL support.
The Data Lake: A Reservoir of Unstructured Potential A data lake is a centralized repository that stores vast amounts of rawdata. It can store any type of data — structured, unstructured, and semi-structured — in its native format, providing a highly scalable and adaptable solution for diverse data needs.
The Data Lake: A Reservoir of Unstructured Potential A data lake is a centralized repository that stores vast amounts of rawdata. It can store any type of data — structured, unstructured, and semi-structured — in its native format, providing a highly scalable and adaptable solution for diverse data needs.
The Data Lake: A Reservoir of Unstructured Potential A data lake is a centralized repository that stores vast amounts of rawdata. It can store any type of data — structured, unstructured, and semi-structured — in its native format, providing a highly scalable and adaptable solution for diverse data needs.
But this data is not that easy to manage since a lot of the data that we produce today is unstructured. In fact, 95% of organizations acknowledge the need to manage unstructured rawdata since it is challenging and expensive to manage and analyze, which makes it a major concern for most businesses. You can use Glue's G.1X
An Azure Data Engineer is a professional responsible for designing, implementing, and managing data solutions using Microsoft's Azure cloud platform. They work with various Azure services and tools to build scalable, efficient, and reliable data pipelines, datastorage solutions, and dataprocessing systems.
Without a fixed schema, the data can vary in structure and organization. File systems, data lakes, and Big Dataprocessing frameworks like Hadoop and Spark are often utilized for managing and analyzing unstructured data. You can’t just keep it in SQL databases, unlike structured data.
In 2010, a transformative concept took root in the realm of datastorage and analytics — a data lake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. Rawdata store section.
Key components of an observability pipeline include: Data collection: Acquiring relevant information from various stages of your data pipelines using monitoring agents or instrumentation libraries. Datastorage: Keeping collected metrics and logs in a scalable database or time-series platform.
An Azure Data Engineer is responsible for designing, implementing and managing data solutions on Microsoft Azure. The Azure Data Engineer certification imparts to them a deep understanding of dataprocessing, storage and architecture. It makes us a versatile data professional.
That’s why it’s essential for teams to choose the right architecture for the storage layer of their data stack. But, the options for datastorage are evolving quickly. So let’s get to the bottom of the big question: what kind of datastorage layer will provide the strongest foundation for your data platform?
A data lake is essentially a vast digital dumping ground where companies toss all their rawdata, structured or not. A modern data stack can be built on top of this datastorage and processing layer, or a data lakehouse or data warehouse, to store data and process it before it is later transformed and sent off for analysis.
Here are some of the tools you might get familiar with upon completion of this research: Apache NiFi: A framework for dataprocessing that enables users to gather, transform, and transfer data from edge devices to cloud computing infrastructure. That's where fog computing and related edge computing paradigms come in.
Initially developed by Netflix and later donated to the Apache Software Foundation, Apache Iceberg is an open-source table format for large-scale distributed data sets. It’s designed to improve upon the performance and usability challenges of older datastorage formats such as Apache Hive and Apache Parquet.
The key differentiation lies in the transformational steps that a data pipeline includes to make data business-ready. Ultimately, the core function of a pipeline is to take rawdata and turn it into valuable, accessible insights that drive business growth. best suit our processeddata? cleaning, formatting)?
Data lakes are useful, flexible datastorage repositories that enable many types of data to be stored in its rawest state. Traditionally, after being stored in a data lake, rawdata was then often moved to various destinations like a data warehouse for further processing, analysis, and consumption.
The practice of designing, building, and maintaining the infrastructure and systems required to collect, process, store, and deliver data to various organizational stakeholders is known as data engineering. You can pace your learning by joining data engineering courses such as the Bootcamp Data Engineer.
It is a cloud-based service by Amazon Web Services (AWS) that simplifies processing large, distributed datasets using popular open-source frameworks, including Apache Hadoop and Spark. Let’s see what is AWS EMR, its features, benefits, and especially how it helps you unlock the power of your big data.
The data source is the location of the data that the processing will consume for dataprocessing functions. This can be the point of origin of the data, the place of its creation. Alternatively, this can be data generated by another process and then made available for subsequent processing.
A growing number of companies now use this data to uncover meaningful insights and improve their decision-making, but they can’t store and process it by the means of traditional datastorage and processing units. Key Big Data characteristics. Datastorage and processing.
The DW nature isn’t the best fit for complex dataprocessing such as machine learning as warehouses normally store task-specific data, while machine learning and data science tasks thrive on the availability of all collected data. Data lake. Lakehouse architecture. DataFrame API support.
PySpark, for instance, optimizes distributed data operations across clusters, ensuring faster dataprocessing. Python for Data Engineering Use Cases Data engineering, at its core, is about preparing “big data” for analytical processing.
Big data operations require specialized tools and techniques since a relational database cannot manage such a large amount of data. Big data enables businesses to gain a deeper understanding of their industry and helps them extract valuable information from the unstructured and rawdata that is regularly collected.
Data engineers design, manage, test, maintain, store, and work on the data infrastructure that allows easy access to structured and unstructured data. Data engineers need to work with large amounts of data and maintain the architectures used in various data science projects. Technical Data Engineer Skills 1.Python
Data Ingestion DataProcessingData Splitting Model Training Model Evaluation Model Deployment Monitoring Model Performance Machine Learning Pipeline Tools Machine Learning Pipeline Deployment on Different Platforms FAQs What tools exist for managing data science and machine learning pipelines?
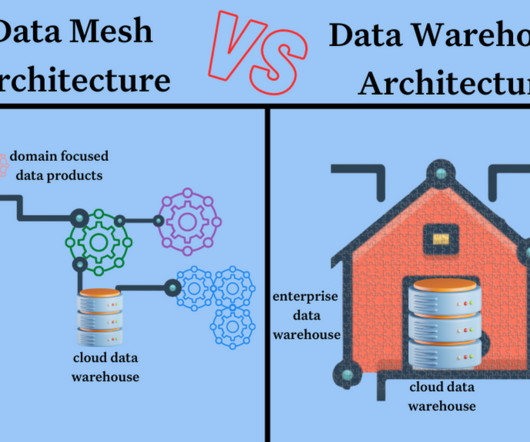
Today, when a data professional uses the term “data warehouse” they are likely referring to these cloud solutions that feature architectures with separate compute query engine and datastorage. A data mesh might leverage one or several cloud data warehouses depending on how closely the organization adheres to the dogma.
Moreover, numerous sources offer unique third-party data that is instantly accessible when needed. Provides Powerful Computing Resources for DataProcessing Before inputting data into advanced machine learning models and deep learning tools, data scientists require sufficient computing resources to analyze and prepare it.
Traditionally, the dimensional data modeling approach is used to build complex data warehouses, while Data Vaults are used in data warehouses to offer long-term historical datastorage while modeling. Why is data modeling important for a data warehouse?
Data Science- Definition Data Science is an interdisciplinary branch encompassing data engineering and many other fields. Data Science involves applying statistical techniques to rawdata, just like data analysts, with the additional goal of building business solutions.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content