This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Though basic and easy to use, traditional table storage formats struggle to keep up. Track data files within the table along with their column statistics.
In addition to log files, sensors, and messaging systems, Striim continuously ingests real-time data from cloud-based or on-premises data warehouses and databases such as Oracle, Oracle Exadata, Teradata, Netezza, Amazon Redshift, SQL Server, HPE NonStop, MongoDB, and MySQL.
Read Time: 6 Minute, 6 Second In modern data pipelines, handling data in various formats such as CSV, Parquet, and JSON is essential to ensure smooth dataprocessing. However, one of the most common challenges faced by data engineers is the evolution of schemas as new data comes in.
Proficiency in Programming Languages Knowledge of programming languages is a must for AI data engineers and traditional data engineers alike. In addition, AI data engineers should be familiar with programming languages such as Python , Java, Scala, and more for data pipeline, data lineage, and AI model development.
Why Future-Proofing Your Data Pipelines Matters Data has become the backbone of decision-making in businesses across the globe. The ability to harness and analyze data effectively can make or break a company’s competitive edge. Set Up Auto-Scaling: Configure auto-scaling for your dataprocessing and storage resources.
Raw data, however, is frequently disorganised, unstructured, and challenging to work with directly. Dataprocessing analysts can be useful in this situation. Let’s take a deep dive into the subject and look at what we’re about to study in this blog: Table of Contents What Is DataProcessing Analysis?
For example, the datastorage systems and processing pipelines that capture information from genomic sequencing instruments are very different from those that capture the clinical characteristics of a patient from a site. A conceptual architecture illustrating this is shown in Figure 3.
Think of it as the “slow and steady wins the race” approach to dataprocessing. Stream Processing Pattern Now, imagine if instead of waiting to do laundry once a week, you had a magical washing machine that could clean each piece of clothing the moment it got dirty. The data lakehouse has got you covered!
Despite Spark’s extensive features, it’s worth mentioning that it doesn’t provide true real-time processing, which we will explore in more depth later. Spark SQL brings native support for SQL to Spark and streamlines the process of querying semistructured and structured data. Big dataprocessing.
Big data is a term that refers to the massive volume of data that organizations generate every day. In the past, this data was too large and complex for traditional dataprocessing tools to handle. There are a variety of big dataprocessing technologies available, including Apache Hadoop, Apache Spark, and MongoDB.
The future of SQL (Structured Query Language) is a scalding subject among professionals in the data-driven world. As data generation continues to skyrocket, the demand for real-time decision-making, dataprocessing, and analysis increases. How is SQL Being Utilized? billion in 2022 to $154.6
Should that be the case, Azure SQL Database might be your best bet. Microsoft SQL Server's functionalities are fully included in Azure SQL Database, a cloud-based database service that also offers greater flexibility and scalability. In this article, I will cover the various aspects of Azure SQL Database.
Hadoop and Spark are the two most popular platforms for Big Dataprocessing. They both enable you to deal with huge collections of data no matter its format — from Excel tables to user feedback on websites to images and video files. Obviously, Big Dataprocessing involves hundreds of computing units.
Striim, for instance, facilitates the seamless integration of real-time streaming data from various sources, ensuring that it is continuously captured and delivered to big datastorage targets. By efficiently handling data ingestion, this component sets the stage for effective dataprocessing and analysis.
PySpark SQL and Dataframes A dataframe is a shared collection of organized or semi-structured data in PySpark. This collection of data is kept in Dataframe in rows with named columns, similar to relational database tables. PySpark SQL combines relational processing with the functional programming API of Spark.
RDBMS is not always the best solution for all situations as it cannot meet the increasing growth of unstructured data. As dataprocessing requirements grow exponentially, NoSQL is a dynamic and cloud friendly approach to dynamically process unstructured data with ease.IT
Openness : The term “open” in open data lakehouse signifies interoperability and compatibility with various dataprocessing frameworks, analytics tools, and programming languages. Support for Modern Analytics Workloads : With support for both SQL-based querying and advanced analytics frameworks (e.g.,
Most cutting-edge technology organizations like Netflix, Apple, Facebook, and Uber have massive Spark clusters for dataprocessing and analytics. The Pig has SQL-like syntax and it is easier for SQL developers to get on board easily. Spark can be used interactively also for dataprocessing.
The Rise of the Data Engineer The Downfall of the Data Engineer Functional Data Engineering — a modern paradigm for batch dataprocessing There is a global consensus stating that you need to master a programming language (Python or Java based) and SQL in order to be self-sufficient.
It serves another end of the business, as compared to the Snowflake Copilot assistant, which helps SQL developers accelerate development from inside the Snowflake UI by turning text into SQL. With Cortex Fine-Tuning, you can fine-tune by calling an API or SQL function, all without the hassle of managing any infrastructure.
Big Data has found a comfortable home inside the Hadoop ecosystem. Hadoop based data stores have gained wide acceptance around the world by developers, programmers, data scientists, and database experts. It also supports user-defined functions and allows processing of compressed data.
These servers are primarily responsible for datastorage, management, and processing. This is important before cloud computing will provide the field of data science with the ability to utilize various platforms and tools, to help store and analyze extensive data.
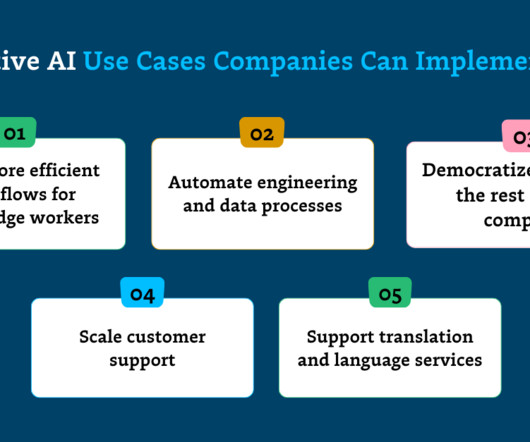
Automate engineering and dataprocesses By automating repetitive or mundane aspects of coding and data engineering, generative AI is streamlining workflows and driving productivity for software and data engineers alike. As Engineering Director Emmanuel Fuentes told us recently, “It’s helping people bootstrap.
According to the World Economic Forum, the amount of data generated per day will reach 463 exabytes (1 exabyte = 10 9 gigabytes) globally by the year 2025. Certain roles like Data Scientists require a good knowledge of coding compared to other roles.
Hadoop Gigabytes to petabytes of data may be stored and processed effectively using the open-source framework known as Apache Hadoop. Hadoop enables the clustering of many computers to examine big datasets in parallel more quickly than a single powerful machine for datastorage and processing. degrees.
I’d also like to offer some perspective on how best to handle issues such as a person’s right to rectification, data portability, data deletion and restriction of dataprocessing. Once sensitive data is no longer available through Time Travel , it will be available in Fail Safe for seven days (non-configurable).
Azure Data Engineering is a rapidly growing field that involves designing, building, and maintaining dataprocessing systems using Microsoft Azure technologies. Proficiency in programming languages: Knowledge of programming languages such as Python and SQL is essential for Azure Data Engineers.
But with the start of the 21st century, when data started to become big and create vast opportunities for business discoveries, statisticians were rightfully renamed into data scientists. Data scientists today are business-oriented analysts who know how to shape data into answers, often building complex machine learning models.
As an Azure Data Engineer, you will be expected to design, implement, and manage data solutions on the Microsoft Azure cloud platform. You will be in charge of creating and maintaining data pipelines, datastorage solutions, dataprocessing, and data integration to enable data-driven decision-making inside a company.
Organizations across industries moved beyond experimental phases to implement production-ready GenAI solutions within their data infrastructure. Natural Language Interfaces Companies like Uber, Pinterest, and Intuit adopted sophisticated text-to-SQL interfaces, democratizing data access across their organizations.
Organisations are constantly looking for robust and effective platforms to manage and derive value from their data in the constantly changing landscape of data analytics and processing. These platforms provide strong capabilities for dataprocessing, storage, and analytics, enabling companies to fully use their data assets.
An Azure Data Engineer is responsible for designing, implementing, and maintaining data management and dataprocessing systems on the Microsoft Azure cloud platform. They work with large and complex data sets and are responsible for ensuring that data is stored, processed, and secured efficiently and effectively.
With programs like Data Science Acceleration Platform and IQNxt, Wipro excels in creating a revenue roadmap for its clients. It is a multibillion-dollar business known for innovations like floppy disk, ATM, SQL programming languages, etc. IBM has developed a system called IBM Cloud Pak for data.
Concepts, theory, and functionalities of this modern datastorage framework Photo by Nick Fewings on Unsplash Introduction I think it’s now perfectly clear to everybody the value data can have. To use a hyped example, models like ChatGPT could only be built on a huge mountain of data, produced and collected over years.
That depends on the business use case, use case complexity, workflow complexity, and whether batch or streaming data is required. Use Nifi for ETL of streaming data, when real-time dataprocessing is needed, or when data must flow from various sources rapidly and reliably.
An Azure Data Engineer is a professional responsible for designing, implementing, and managing data solutions using Microsoft's Azure cloud platform. They work with various Azure services and tools to build scalable, efficient, and reliable data pipelines, datastorage solutions, and dataprocessing systems.
Here is a step-by-step guide on how to become an Azure Data Engineer: 1. Understanding SQL You must be able to write and optimize SQL queries because you will be dealing with enormous datasets as an Azure Data Engineer. You ought to be able to create a data model that is performance- and scalability-optimized.
Data Engineers are engineers responsible for uncovering trends in data sets and building algorithms and data pipelines to make raw data beneficial for the organization. This job requires a handful of skills, starting from a strong foundation of SQL and programming languages like Python , Java , etc.
Database management: Data engineers should be proficient in storing and managing data and working with different databases, including relational and NoSQL databases. Data modeling: Data engineers should be able to design and develop data models that help represent complex data structures effectively.
Applications of Cloud Computing in DataStorage and Backup Many computer engineers are continually attempting to improve the process of data backup. Previously, customers stored data on a collection of drives or tapes, which took hours to collect and move to the backup location.
An Azure Data Engineer is responsible for designing, implementing and managing data solutions on Microsoft Azure. The Azure Data Engineer certification imparts to them a deep understanding of dataprocessing, storage and architecture. It makes us a versatile data professional.
Here are some role-specific skills you should consider to become an Azure data engineer- Most datastorage and processing systems use programming languages. Data engineers must thoroughly understand programming languages such as Python, Java, or Scala. Who should take the certification exam?
Key Benefits and Takeaways: Understand data intake strategies and data transformation procedures by learning data engineering principles with Python. Investigate alternative datastorage solutions, such as databases and data lakes. Key Benefits and Takeaways: Learn the core concepts of big data systems.
For datastorage, the database is one of the fundamental building blocks. Relational Databases A relational database organizes data into tables that contain links between data elements that define their relationships. This allows quick access to information based on the connections between data elements.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content