This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts. DataStorage Solutions As we all know, data can be stored in a variety of ways.
In today’s data-driven world, organizations amass vast amounts of information that can unlock significant insights and inform decision-making. A staggering 80 percent of this digital treasure trove is unstructureddata, which lacks a pre-defined format or organization. What is unstructureddata?
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Though basic and easy to use, traditional table storage formats struggle to keep up. Track data files within the table along with their column statistics.
Raw data, however, is frequently disorganised, unstructured, and challenging to work with directly. Dataprocessing analysts can be useful in this situation. Let’s take a deep dive into the subject and look at what we’re about to study in this blog: Table of Contents What Is DataProcessing Analysis?
For example, the datastorage systems and processing pipelines that capture information from genomic sequencing instruments are very different from those that capture the clinical characteristics of a patient from a site. A conceptual architecture illustrating this is shown in Figure 3.
“California Air Resources Board has been exploring processing atmospheric data delivered from four different remote locations via instruments that produce netCDF files. Previously, working with these large and complex files would require a unique set of tools, creating data silos. ” U.S.
Vector Search and UnstructuredDataProcessing Advancements in Search Architecture In 2024, organizations redefined search technology by adopting hybrid architectures that combine traditional keyword-based methods with advanced vector-based approaches.
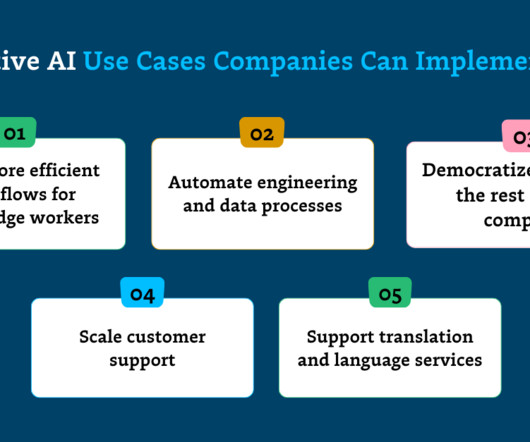
Build more efficient workflows for knowledge workers Across industries, companies are driving early generative AI use cases by automating and simplifying time-intensive processes for knowledge workers. Let’s explore how a few key sectors are putting gen AI to use.
Striim, for instance, facilitates the seamless integration of real-time streaming data from various sources, ensuring that it is continuously captured and delivered to big datastorage targets. By efficiently handling data ingestion, this component sets the stage for effective dataprocessing and analysis.
Comparison of Snowflake Copilot and Cortex Analyst Cortex Search: Deliver efficient and accurate enterprise-grade document search and chatbots Cortex Search is a fully managed search solution that offers a rich set of capabilities to index and query unstructureddata and documents.
Hadoop and Spark are the two most popular platforms for Big Dataprocessing. They both enable you to deal with huge collections of data no matter its format — from Excel tables to user feedback on websites to images and video files. Obviously, Big Dataprocessing involves hundreds of computing units.
IBM is one of the best companies to work for in Data Science. The platform allows not only datastorage but also deep dataprocessing by making use of Apache Hadoop. The CDP private cloud is a scalable datastorage solution that can handle analytical and machine learning workloads.
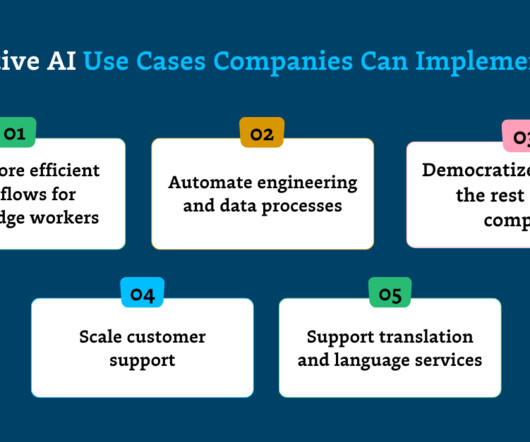
Build more efficient workflows for knowledge workers Across industries, companies are driving early generative AI use cases by automating and simplifying time-intensive processes for knowledge workers. Let’s explore how a few key sectors are putting gen AI to use.
Statistics are used by data scientists to collect, assess, analyze, and derive conclusions from data, as well as to apply quantifiable mathematical models to relevant variables. Microsoft Excel An effective Excel spreadsheet will arrange unstructureddata into a legible format, making it simpler to glean insights that can be used.
Amazon S3 : Highly scalable, durable object storage designed for storing backups, data lakes, logs, and static content. Data is accessed over the network and is persistent, making it ideal for unstructureddatastorage. R7g , X2idn ) are ideal. I4i , D3en ). M6i , M7g ).
The integration of data from separate sources becomes a self-consistent data set with the removal of duplications and flagging of inconsistencies or, if possible, their resolution. Datastorage uses a non-volatile environment with strict management controls on the modification and deletion of data.
This involves connecting to multiple data sources, using extract, transform, load ( ETL ) processes to standardize the data, and using orchestration tools to manage the flow of data so that it’s continuously and reliably imported – and readily available for analysis and decision-making.
That’s why it’s essential for teams to choose the right architecture for the storage layer of their data stack. But, the options for datastorage are evolving quickly. So let’s get to the bottom of the big question: what kind of datastorage layer will provide the strongest foundation for your data platform?
RDBMS is not always the best solution for all situations as it cannot meet the increasing growth of unstructureddata. As dataprocessing requirements grow exponentially, NoSQL is a dynamic and cloud friendly approach to dynamically processunstructureddata with ease.IT
To choose the most suitable data management solution for your organization, consider the following factors: Data types and formats: Do you primarily work with structured, unstructured, or semi-structured data? Consider whether you need a solution that supports one or multiple data formats.
Data engineering is a new and ever-evolving field that can withstand the test of time and computing developments. Companies frequently hire certified Azure Data Engineers to convert unstructureddata into useful, structured data that data analysts and data scientists can use.
To choose the most suitable data management solution for your organization, consider the following factors: Data types and formats: Do you primarily work with structured, unstructured, or semi-structured data? Consider whether you need a solution that supports one or multiple data formats.
To choose the most suitable data management solution for your organization, consider the following factors: Data types and formats: Do you primarily work with structured, unstructured, or semi-structured data? Consider whether you need a solution that supports one or multiple data formats.
A Beginner’s Guide [SQ] Niv Sluzki July 19, 2023 ELT is a dataprocessing method that involves extracting data from its source, loading it into a database or data warehouse, and then later transforming it into a format that suits business needs. The data is loaded as-is, without any transformation.
Every day, enormous amounts of data are collected from business endpoints, cloud apps, and the people who engage with them. Cloud computing enables enterprises to access massive amounts of organized and unstructureddata in order to extract commercial value. Datastorage, management, and access skills are also required.
Data Lakehouse: Bridging Data Worlds A data lakehouse combines the best features of data lakes and data warehouses. It stores structured and unstructureddata, enables schema-on-read and schema-on-write, and supports real-time dataprocessing and analytics.
Data Lakehouse: Bridging Data Worlds A data lakehouse combines the best features of data lakes and data warehouses. It stores structured and unstructureddata, enables schema-on-read and schema-on-write, and supports real-time dataprocessing and analytics.
Data Lakehouse: Bridging Data Worlds A data lakehouse combines the best features of data lakes and data warehouses. It stores structured and unstructureddata, enables schema-on-read and schema-on-write, and supports real-time dataprocessing and analytics.
AWS Glue is a widely-used serverless data integration service that uses automated extract, transform, and load ( ETL ) methods to prepare data for analysis. It offers a simple and efficient solution for dataprocessing in organizations. Glue works absolutely fine with structured as well as unstructureddata.
A growing number of companies now use this data to uncover meaningful insights and improve their decision-making, but they can’t store and process it by the means of traditional datastorage and processing units. Key Big Data characteristics. Datastorage and processing.
If you want to break into the field of data engineering but don't yet have any expertise in the field, compiling a portfolio of data engineering projects may help. Data pipeline best practices should be shown in these initiatives. Source Code: Finnhub API with Kafka for Real-Time Financial Market Data Pipeline 3.
An Azure Data Engineer is responsible for designing, implementing, and maintaining data management and dataprocessing systems on the Microsoft Azure cloud platform. They work with large and complex data sets and are responsible for ensuring that data is stored, processed, and secured efficiently and effectively.
Data engineering design patterns are repeatable solutions that help you structure, optimize, and scale dataprocessing, storage, and movement. They make data workflows more resilient and easier to manage when things inevitably go sideways. Data Lakes vs. Data Warehouses: Where Should Your Data Live?
They also facilitate historical analysis, as they store long-term data records that can be used for trend analysis, forecasting, and decision-making. Big Data In contrast, big data encompasses the vast amounts of both structured and unstructureddata that organizations generate on a daily basis.
Azure Data Engineering is a rapidly growing field that involves designing, building, and maintaining dataprocessing systems using Microsoft Azure technologies. Any Azure Data Engineer must have experience with Azure’s datastorage options, including Azure Cosmos DB, Azure Data Lake Storage, and Azure Blob Storage.
In the present-day world, almost all industries are generating humongous amounts of data, which are highly crucial for the future decisions that an organization has to make. This massive amount of data is referred to as “big data,” which comprises large amounts of data, including structured and unstructureddata that has to be processed.
Data engineering is a new and evolving field that will withstand the test of time and computing advances. Certified Azure Data Engineers are frequently hired by businesses to convert unstructureddata into useful, structured data that data analysts and data scientists can use.
They are also accountable for communicating data trends. Let us now look at the three major roles of data engineers. Generalists They are typically responsible for every step of the dataprocessing, starting from managing and making analysis and are usually part of small data-focused teams or small companies.
Importance of Big Data Companies Big Data is intricate and can be challenging to access and manage because data often arrives quickly in ever-increasing amounts. Both structured and unstructureddata may be present in this data. IBM is the leading supplier of Big Data-related products and services.
Big data enables businesses to get valuable insights into their products or services. Almost every company employs data models and big data technologies to improve its techniques and marketing campaigns. Most leading companies use big data analytical tools to enhance business decisions and increase revenues.
In-memory Databases For applications that demand real-time dataprocessing, in-memory databases are created. These databases use RAM-based datastorage, which offers quicker access and response times than disk-based storage. These databases give users more freedom in how to organize and use data.
Data Types Big DataData Mining Big data refers to robust and complicated datasets that require a high level of expertise and tools for managing, processing, or analyzing. Traditional dataprocessing techniques cannot be used.
Organisations are constantly looking for robust and effective platforms to manage and derive value from their data in the constantly changing landscape of data analytics and processing. These platforms provide strong capabilities for dataprocessing, storage, and analytics, enabling companies to fully use their data assets.
BI (Business Intelligence) Strategies and systems used by enterprises to conduct data analysis and make pertinent business decisions. Big Data Large volumes of structured or unstructureddata. Big Query Google’s cloud data warehouse. Data Visualization Graphic representation of a set or sets of data.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content