This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary Dataprocessing technologies have dramatically improved in their sophistication and raw throughput. Unfortunately, the volumes of data that are being generated continue to double, requiring further advancements in the platform capabilities to keep up.
In this edition, we talk to Richard Meng, co-founder and CEO of ROE AI , a startup that empowers data teams to extract insights from unstructured, multimodal data including documents, images and web pages using familiar SQL queries. What inspires you as a founder? First, Snowflake has enabled us to strengthen user trust in our app.
The Critical Role of AI Data Engineers in a Data-Driven World How does a chatbot seamlessly interpret your questions? The answer lies in unstructured dataprocessing—a field that powers modern artificial intelligence (AI) systems. Commitment to promoting fairness and transparency in AI dataworkflows.
Examples include “reduce dataprocessing time by 30%” or “minimize manual data entry errors by 50%.” Deploy DataOps DataOps , or Data Operations, is an approach that applies the principles of DevOps to data management. How effective are your current dataworkflows?
AI-powered data engineering solutions make it easier to streamline the data management process, which helps businesses find useful insights with little to no manual work. Real-time dataprocessing has emerged The demand for real-time data handling is expected to increase significantly in the coming years.
Advanced Data Transformation Techniques For data engineers ready to push the boundaries, advanced data transformation techniques offer the tools to tackle complex data challenges and drive innovation.
Examples include “reduce dataprocessing time by 30%” or “minimize manual data entry errors by 50%.” Deploy DataOps DataOps , or Data Operations, is an approach that applies the principles of DevOps to data management. How effective are your current dataworkflows?
Summary Streaming dataprocessing enables new categories of data products and analytics. Unfortunately, reasoning about stream processing engines is complex and lacks sufficient tooling. Data lakes are notoriously complex. Data lakes are notoriously complex.
The data, originating from different formats and sources, requires consolidation into Snowflake tables for comprehensive analysis. Therefore, Snowpark, with its capabilities in simplifying complex dataworkflows, becomes instrumental in achieving this objective. The journey begins with customer invoice data stored in a CSV file.
Schedule data ingestion, processing, model training and insight generation to enhance efficiency and consistency in your dataprocesses. That’s why we partner with Hex , to provide data teams with access to best-in-class tools to drive more decisions for the business and more value from their data.
I finally found a good critique that discusses its flaws, such as multi-hop architecture, inefficiencies, high costs, and difficulties maintaining data quality and reusability. The article advocates for a "shift left" approach to dataprocessing, improving data accessibility, quality, and efficiency for operational and analytical use cases.
Matt Harrison is a Python expert with a long history of working with data who now spends his time on consulting and training. What are some of the utility features that you have found most helpful for dataprocessing? Pandas is a tool that spans dataprocessing and data science.
What are the different concerns that need to be included in a stack that supports fully automated dataworkflows? There was recently an interesting article suggesting that the "left-to-right" approach to dataworkflows is backwards.
To prevent this issue, we built verification in the post-processing stage to ensure that the user ID column in the data matches the identifier for the user whose logs we are generating.
Since all of Fabric’s tools run natively on OneLake, real-time performance without data duplication is possible in Direct Lake mode. Because of the architecture’s ability to abstract infrastructure complexity, users can focus solely on dataworkflows.
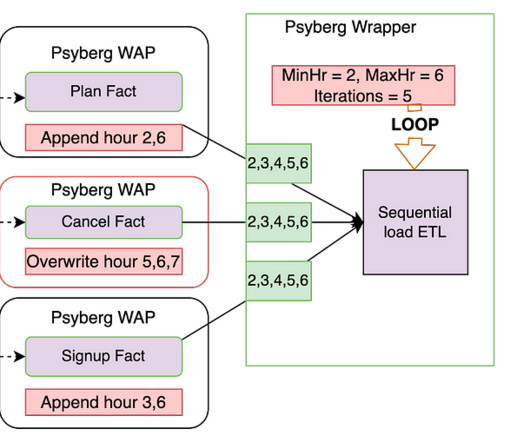
In the previous installments of this series, we introduced Psyberg and delved into its core operational modes: Stateless and Stateful DataProcessing. Pipelines After Psyberg Let’s explore how different modes of Psyberg could help with a multistep data pipeline. Stay tuned for a new post on this!
DataOps improves the robustness, transparency and efficiency of dataworkflows through automation. For example, DataOps can be used to automate data integration. Previously, the consulting team had been using a patchwork of ETL to consolidate data from disparate sources into a data lake.
This methodology emphasizes automation, collaboration, and continuous improvement, ensuring faster, more reliable dataworkflows. With dataworkflows growing in scale and complexity, data teams often struggle to keep up with the increasing volume, variety, and velocity of data. Let’s dive in!
Managing and orchestrating dataworkflows efficiently is crucial in today’s data-driven world. As the amount of data constantly increases with each passing day, so does the complexity of the pipelines handling such dataprocesses.
This blog explores the world of open source data orchestration tools, highlighting their importance in managing and automating complex dataworkflows. From Apache Airflow to Google Cloud Composer, we’ll walk you through ten powerful tools to streamline your dataprocesses, enhance efficiency, and scale your growing needs.
Start small, then scale With dataworkflows growing in scale and complexity, data teams often struggle to keep up with the increasing volume, variety, and velocity of data. This is where DataOps comes ina methodology designed to streamline and automate dataworkflows, ensuring faster and more reliable data delivery.
From there, you can address more complex use cases, such as creating a 360-degree view of customers by integrating systems across CRM, ERP, marketing applications, social media handles and other data sources.
AI-driven data quality workflows deploy machine learning to automate data cleansing, detect anomalies, and validate data. Integrating AI into dataworkflows ensures reliable data and enables smarter business decisions. Data quality is the backbone of successful data engineering projects.
DataOps , short for data operations, is an emerging discipline that focuses on improving the collaboration, integration, and automation of dataprocesses across an organization. Accelerated Data Analytics DataOps tools help automate and streamline various dataprocesses, leading to faster and more efficient data analytics.
Furthermore, Striim also supports real-time data replication and real-time analytics, which are both crucial for your organization to maintain up-to-date insights. By efficiently handling data ingestion, this component sets the stage for effective dataprocessing and analysis. Are we using all the data or just a subset?
Hadoop and Spark are the two most popular platforms for Big Dataprocessing. They both enable you to deal with huge collections of data no matter its format — from Excel tables to user feedback on websites to images and video files. Obviously, Big Dataprocessing involves hundreds of computing units.
DataOps is a collaborative approach to data management that combines the agility of DevOps with the power of data analytics. It aims to streamline data ingestion, processing, and analytics by automating and integrating various dataworkflows.
Data orchestration is the process of efficiently coordinating the movement and processing of data across multiple, disparate systems and services within a company. It automates and optimizes dataprocesses, reducing manual effort and the likelihood of errors. But let’s step back for a second.
Read Time: 1 Minute, 48 Second RETRY LAST: In modern dataworkflows, tasks are often interdependent, forming complex task chains. Ensuring the reliability and resilience of these workflows is critical, especially when dealing with production data pipelines.
The article details how bypassing intermediate storage steps reduces latency and improves dataprocessing speed. The approach highlights the importance of streamlining dataworkflows for faster machine learning model training and deployment.
Additionally, they offer a way to keep your transformed data up to date without redoing the entire transformation process. By using DBT materializations, you can streamline your dataworkflows and focus on gaining insights rather than spending excessive time on repetitive calculations.
Composable Analytics — A DataOps Enterprise Platform with built-in services for data orchestration, automation, and analytics. Reflow — A system for incremental dataprocessing in the cloud. Dagster / ElementL — A data orchestrator for machine learning, analytics, and ETL. .
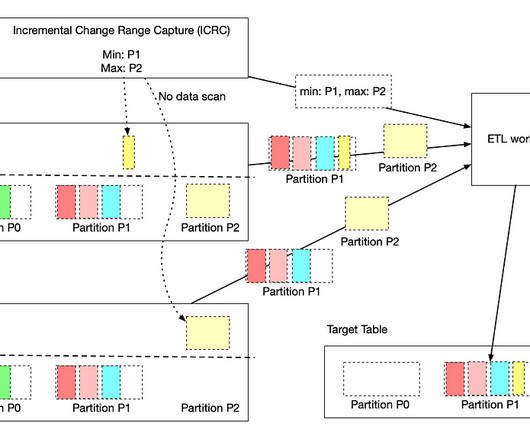
IPS provides the incremental processing support with data accuracy, data freshness, and backfill for users and addresses many of the challenges in workflows. IPS enables users to continue to use the dataprocessing patterns with minimal changes. Note that the backfill support is skipped in this blog.
In the same way, a DataOps engineer designs the data assembly line that enables data scientists to derive insights from data analytics faster and with fewer errors. DataOps engineers improve the speed and quality of the data development process by applying DevOps principles to dataworkflow, known as DataOps.
These technologies are increasingly automating processes like ETL, improving data quality management, and evolving the landscape of data tools. Integrating AI into dataworkflows is not just a trend but a paradigm shift, making dataprocesses more efficient and intelligent.
Overcoming Challenges to Achieve Data Timeliness Despite the clear benefits of timely data, organizations often encounter several hurdles: Complex Data Pipelines: Intricate data pipelines that involve multiple stages and dependencies can hinder smooth data flow.
Evolution of Data Lake Technologies The data lake ecosystem has matured significantly in 2024, particularly in table formats and storage technologies. Query Optimization and Cost Attribution By optimizing their most expensive pipelines , Medium's engineering team demonstrated significant cost savings in their Snowflake environment.
Snowflake’s Data Marketplace : Enriches data pipelines with external data sources, providing access to a diverse range of datasets and services that can be seamlessly integrated into your analytics and dataprocessingworkflows. that you can combine to create custom dataworkflows.
DuckDB’s parallel execution capabilities can help DBAs improve the performance of dataprocessing tasks. Researchers : Academics and researchers working with large volumes of data use DuckDB to process and analyze their data more efficiently. What makes DuckDB different?
Can you talk about some of the technology that helps make managing live streaming data possible? Cloudera DataFlow offers the capability for Edge to cloud streaming dataprocessing. This type of end-to-end dataprocessing that starts at the Edge and ends in the cloud is made possible by using Apache NiFi.
As an Azure Data Engineer, you will be expected to design, implement, and manage data solutions on the Microsoft Azure cloud platform. You will be in charge of creating and maintaining data pipelines, data storage solutions, dataprocessing, and data integration to enable data-driven decision-making inside a company.
It enhances data quality, governance, and optimization, making data retrieval more efficient and enabling powerful automation in data engineering processes. As practitioners using metadata to fuel data teams, we at Ascend understand the critical role it plays in organizing, managing, and optimizing dataworkflows.
At Ascend, we recognize the immense potential in integrating these advanced AI capabilities into our platform, enabling smarter applications and more efficient dataworkflows. Snowflake’s investment in expanding data engineering capabilities is a game-changer.
The Five Use Cases in Data Observability: Mastering Data Production (#3) Introduction Managing the production phase of data analytics is a daunting challenge. Overseeing multi-tool, multi-dataset, and multi-hop dataprocesses ensures high-quality outputs.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content