This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Hadoop and Spark are the two most popular platforms for Big Dataprocessing. They both enable you to deal with huge collections of data no matter its format — from Excel tables to user feedback on websites to images and video files. What are its limitations and how do the Hadoop ecosystem address them? scalability.
What industry is big data developer in? What is a Big Data Developer? A Big Data Developer is a specialized IT professional responsible for designing, implementing, and managing large-scale dataprocessing systems that handle vast amounts of information, often called "big data."
Learn all about Azure ETL Tools in minutes with this quick guide, showcasing the top 7 Azure tools with their key features, pricing, and pros/cons for your dataprocessing needs. He explores their collaborative potential in orchestrating, exploring, and analyzing data, shaping a secure and comprehensive data engineering landscape.
If you are willing to gain hands-on experience with Google BigQuery , you must explore the GCP Project to Learn using BigQuery for Exploring Data. Google Cloud Dataproc Dataproc is a fully-managed and scalable Spark and Hadoop Service that supports batch processing, querying, streaming, and machine learning.
In 2024, the data engineering job market is flourishing, with roles like database administrators and architects projected to grow by 8% and salaries averaging $153,000 annually in the US (as per Glassdoor ). These trends underscore the growing demand and significance of data engineering in driving innovation across industries.
If someone is looking to master the art and science of constructing batch pipelines, ProjectPro has got you covered with this comprehensive tutorial that will help you learn how to build your first batch data pipeline and transform raw data into actionable insights.
With widespread enterprise adoption, learning Hadoop is gaining traction as it can lead to lucrative career opportunities. There are several hurdles and pitfalls students and professionals come across while learning Hadoop. How much Java is required to learn Hadoop? How much Java is required to learn Hadoop?
From the fundamentals to advanced concepts, it covers everything from a step-by-step process of creating PySpark UDFs, demonstrating their seamless integration with SQL , and practical examples to solidify your understanding. As data grows in size and complexity, so does the need for tailored dataprocessing solutions.
Azure Databricks is a robust cloud-based analytics and dataprocessing platform for various data-related tasks. Compute Management: Databricks allows you to manage the compute resources required for dataprocessing tasks. This is also where dataprocessing takes place.
Think of the data integration process as building a giant library where all your data's scattered notebooks are organized into chapters. You define clear paths for data to flow, from extraction (gathering structured/unstructured data from different systems) to transformation (cleaning the raw data, processing the data, etc.)
If you're looking to revolutionize your dataprocessing and analysis, Python for ETL is the key to unlock the door. Check out this ultimate guide to explore the fascinating world of ETL with Python and discover why it's the top choice for modern data enthusiasts. Python ETL really empowers you to transform data like a pro.
Their role includes designing data pipelines, integrating data from multiple sources, and setting up databases and data lakes that can support machine learning and analytics workloads. They work with various tools and frameworks, such as Apache Spark, Hadoop , and cloud services, to manage massive amounts of data.
Additional processing capability with SQL, as well as Snowflake capabilities like Stored Procedures, Snowpark , and Streams and Tasks, help streamline operations. LTIMindtree’s PolarSled Accelerator helps migrate existing legacy systems, such as SAP, Teradata and Hadoop, to Snowflake.
Data Engineering is typically a software engineering role that focuses deeply on data – namely, dataworkflows, data pipelines, and the ETL (Extract, Transform, Load) process. They are also accountable for communicating data trends. Let us now look at the three major roles of data engineers.
Airflow — An open-source platform to programmatically author, schedule, and monitor data pipelines. Apache Oozie — An open-source workflow scheduler system to manage Apache Hadoop jobs. DBT (Data Build Tool) — A command-line tool that enables data analysts and engineers to transform data in their warehouse more effectively.
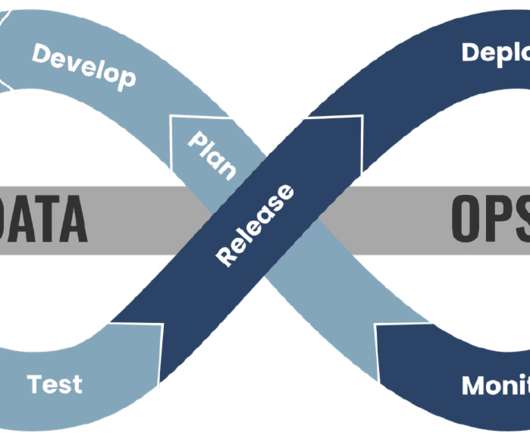
DataOps , short for data operations, is an emerging discipline that focuses on improving the collaboration, integration, and automation of dataprocesses across an organization. Accelerated Data Analytics DataOps tools help automate and streamline various dataprocesses, leading to faster and more efficient data analytics.
As the volume and complexity of data continue to grow, organizations seek faster, more efficient, and cost-effective ways to manage and analyze data. In recent years, cloud-based data warehouses have revolutionized dataprocessing with their advanced massively parallel processing (MPP) capabilities and SQL support.
The “legacy” table formats The data landscape has evolved so quickly that table formats pioneered within the last 25 years are already achieving “legacy” status. It was designed to support high-volume data exchange and compatibility across different system versions, which is essential for streaming architectures such as Apache Kafka.
These Azure data engineer projects provide a wonderful opportunity to enhance your data engineering skills, whether you are a beginner, an intermediate-level engineer, or an advanced practitioner. Who is Azure Data Engineer? Azure SQL Database, Azure Data Lake Storage). Azure SQL Database, Azure Data Lake Storage).
This includes knowledge of data structures (such as stack, queue, tree, etc.), A Machine Learning professional needs to have a solid grasp on at least one programming language such as Python, C/C++, R, Java, Spark, Hadoop , etc. Machine Learning engineers are often required to collaborate with data engineers to build dataworkflows.
Users can also leverage it for generating interactive visualizations over data. It also comes with lots of automation techniques that qualify users to eliminate manual dataworkflows. It can analyze data in real-time and can perform cluster management. It is much faster than other analytic workload tools like Hadoop.
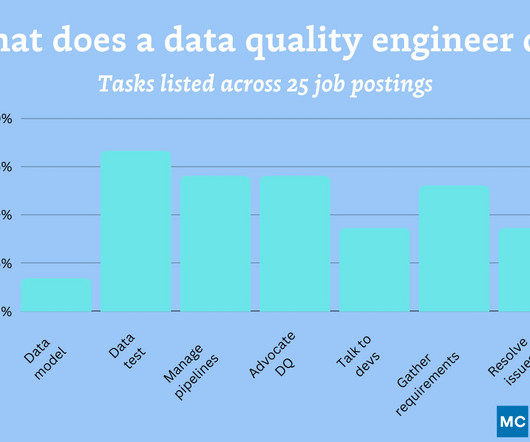
Data quality engineers also need to have experience operating in cloud environments and using many of the modern data stack tools that are utilized in building and maintaining data pipelines. 78% of job postings referenced at least part of their environment was in a modern data warehouse, lake, or lakehouse.
Microsoft Data Engineer Certification is one such certification which is most sought after by professionals. By combining data from various structured and unstructured data systems into structures, Microsoft Azure Data Engineers will be able to create analytics solutions.
The ETL (Extract, Transform, Load) process follows four main steps: i) Connect and Collect: Connect to the data source/s and move data to local and crowdsource data storage. ii) Data transformation using computing services such as HDInsight, Hadoop , Spark, etc.
But even as the modern data stack continues to evolve, Airflow maintains its title as a perennial data orchestration favorite—and for good reason. Prefect’s control panel also offers scheduling, automatic retries, and instant alerting, ensuring you always have a clear view of your dataprocesses.
Salary (Average) $135,094 per year (Source: Talent.com) Top Companies Hiring Deloitte, IBM, Capgemini Certifications Microsoft Certified: Azure Solutions Architect Expert Job Role 3: Azure Big Data Engineer The focus of Azure Big Data Engineers is developing and implementing big data solutions with the use of the Microsoft Azure platform.
The Elastic Stacks Elasticsearch is integral within analytics stacks, collaborating seamlessly with other tools developed by Elastic to manage the entire dataworkflow — from ingestion to visualization. Beats facilitate data movement from source to destination, which can be either Elasticsearch or Logstash, depending on the use case.
5 Data pipeline architecture designs and their evolution The Hadoop era , roughly 2011 to 2017, arguably ushered in big dataprocessing capabilities to mainstream organizations. Data then, and even today for some organizations, was primarily hosted in on-premises databases with non-scalable storage.
This includes knowledge of data structures (such as stack, queue, tree, etc.), A Machine Learning professional needs to have a solid grasp on at least one programming language such as Python, C/C++, R, Java, Spark, Hadoop, etc. Machine Learning engineers are often required to collaborate with data engineers to build dataworkflows.
In the big data industry, Hadoop has emerged as a popular framework for processing and analyzing large datasets, with its ability to handle massive amounts of structured and unstructured data. Table of Contents Why work on Apache Hadoop Projects? FAQs Why work on Apache Hadoop Projects?
phData Cloud Foundation is dedicated to machine learning and data analytics, with prebuilt stacks for a range of analytical tools, including AWS EMR, Airflow, AWS Redshift, AWS DMS, Snowflake, Databricks, Cloudera Hadoop, and more. This helps drive requirements and determines the right validation at the right time for the data.
Web Server Log Processing In this project, you'll process web server logs using a combination of Hadoop, Flume, Spark, and Hive on Azure. Starting with setting up an Azure Virtual Machine, you'll install necessary big data tools and configure Flume agents for log data ingestion.
DevOps tasks — for example, creating scheduled backups and restoring data from them. Airflow is especially useful for orchestrating Big Dataworkflows. Airflow is not a dataprocessing tool by itself but rather an instrument to manage multiple components of dataprocessing. When Airflow won’t work.
By converting Excel-based sales data into dynamic visualizations, this solution supports data-driven strategy and performance tracking for retail and e-commerce businesses. This project uses Python libraries such as Pandas for dataprocessing and Dash with Plotly for dashboard development.
40
40
Input your email to sign up, or if you already have an account, log in here!
Enter your email address to reset your password. A temporary password will be e‑mailed to you.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content