This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary Dataprocessing technologies have dramatically improved in their sophistication and raw throughput. Unfortunately, the volumes of data that are being generated continue to double, requiring further advancements in the platform capabilities to keep up.
These practices are crucial for building robust and scalable data pipelines, maintaining data quality, and enabling data-driven decision-making. Let us dive into some of the crucial best practices for data engineering that data engineers must implement in their dataworkflows and projects.
Summary Streaming dataprocessing enables new categories of data products and analytics. Unfortunately, reasoning about stream processing engines is complex and lacks sufficient tooling. Data lakes are notoriously complex. Data lakes are notoriously complex.
The answer lies in unstructured dataprocessing—a field that powers modern artificial intelligence (AI) systems. Unlike neatly organized rows and columns in spreadsheets, unstructured data—such as text, images, videos, and audio—requires advanced processing techniques to derive meaningful insights.
In this edition, we talk to Richard Meng, co-founder and CEO of ROE AI , a startup that empowers data teams to extract insights from unstructured, multimodal data including documents, images and web pages using familiar SQL queries. ROE AI solves unstructured data with zero embedding vectors. What inspires you as a founder?
The journey from raw data to meaningful insights is no walk in the park. It requires a skillful blend of data engineering expertise and the strategic use of tools designed to streamline this process. That’s where data pipeline tools come in. What are Data Pipelines? How Do Data Pipelines Work?
Today enterprises can leverage the combination of Cloudera and Snowflake—two best-of-breed tools for ingestion, processing and consumption of data—for a single source of truth across all data, analytics, and AI workloads.
Examples include “reduce dataprocessing time by 30%” or “minimize manual data entry errors by 50%.” Start Small and Scale: Instead of overhauling all processes at once, identify a small, manageable project to automate as a proof of concept. How effective are your current dataworkflows?
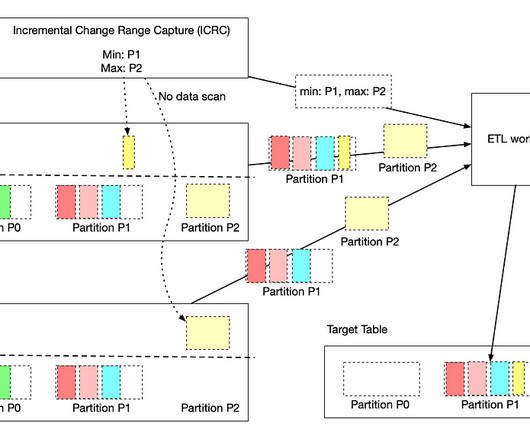
by Jun He , Yingyi Zhang , and Pawan Dixit Incremental processing is an approach to process new or changed data in workflows. The key advantage is that it only incrementally processesdata that are newly added or updated to a dataset, instead of re-processing the complete dataset.
What is Data Transformation? Data transformation is the process of converting raw data into a usable format to generate insights. It involves cleaning, normalizing, validating, and enriching data, ensuring that it is consistent and ready for analysis. This is crucial for maintaining data integrity and quality.
Dagster vs Airflow: Overview Dagster and Airflow are two popular open-source tools that have emerged as leaders in data orchestration. They are often compared because of their shared goal of automating dataworkflows and widespread adoption in the data engineering community. What is Airflow? What is Dagster?
Read Time: 1 Minute, 42 Second In this blog post, we’ll delve into a practical example that showcases the prowess of Snowpark by processing customer invoice data from a CSV file and handling credit card details from a JSON source. The journey begins with customer invoice data stored in a CSV file.
Examples include “reduce dataprocessing time by 30%” or “minimize manual data entry errors by 50%.” Start Small and Scale: Instead of overhauling all processes at once, identify a small, manageable project to automate as a proof of concept. How effective are your current dataworkflows?
We created data logs as a solution to provide users who want more granular information with access to data stored in Hive. In this context, an individual data log entry is a formatted version of a single row of data from Hive that has been processed to make the underlying data transparent and easy to understand.
Exponential Growth in AI-Driven Data Solutions This approach, known as data building, involves integrating AI-based processes into the services. As early as 2025, the integration of these processes will become increasingly significant. It lets you describe data more complexly and make predictions.
Learn all about Azure ETL Tools in minutes with this quick guide, showcasing the top 7 Azure tools with their key features, pricing, and pros/cons for your dataprocessing needs. Many are turning to Azure ETL tools for their simplicity and efficiency, offering a seamless experience for easy data extraction, transformation, and loading.
Building a batch pipeline is essential for processing large volumes of data efficiently and reliably. Are you ready to step into the heart of big data projects and take control of data like a pro? Batch data pipelines are your ticket to the world of efficient dataprocessing.
By mastering Azure Data Factory with the help of detailed explanations, Azure Data Factory tutorial videos, and hands-on practical experience, beginners can build automated data pipelines, orchestrating data movement and processing across sources and destinations effortlessly.
Key operations include handling missing data, converting timestamps, and categorizing rides by parameters like time of day, trip duration, and location clusters. Store the data in in Google Cloud Storage to ensure scalability and reliability. by ingesting raw data into a cloud storage solution like AWS S3.
Notably, the process includes an RL step to create a specialized reasoning model (R1-Zero) capable of excelling in reasoning tasks without labeled SFT data, highlighting advancements in training methodologies for AI models. link] Get Your Guide: From Snowflake to Databricks: Our cost-effective journey to a unified data warehouse.
If you are willing to gain hands-on experience with Google BigQuery , you must explore the GCP Project to Learn using BigQuery for Exploring Data. Google Cloud Dataproc Dataproc is a fully-managed and scalable Spark and Hadoop Service that supports batch processing, querying, streaming, and machine learning.
If you're looking to revolutionize your dataprocessing and analysis, Python for ETL is the key to unlock the door. Check out this ultimate guide to explore the fascinating world of ETL with Python and discover why it's the top choice for modern data enthusiasts. Python ETL really empowers you to transform data like a pro.
From the fundamentals to advanced concepts, it covers everything from a step-by-step process of creating PySpark UDFs, demonstrating their seamless integration with SQL , and practical examples to solidify your understanding. As data grows in size and complexity, so does the need for tailored dataprocessing solutions.
However, creating and deploying these agents often involves challenges such as managing complex dataworkflows, integrating machine learning models, and ensuring scalability across operations. It simplifies the development process by providing full-stack templates, allowing users to go from zero to production in minutes.
Just like an orchestra conductor , Kubernetes orchestrates the entire deployment and management of your data science projects. This comprehensive blog will explore 15 exciting Kubernetes projects tailored for data scientists and developers, highlighting the significant benefits and career impact of mastering Kubernetes in data science.
A data science pipeline represents a systematic approach to collecting, processing, analyzing, and visualizing data for informed decision-making. Data science pipelines are essential for streamlining dataworkflows, efficiently handling large volumes of data, and extracting valuable insights promptly.
What industry is big data developer in? What is a Big Data Developer? A Big Data Developer is a specialized IT professional responsible for designing, implementing, and managing large-scale dataprocessing systems that handle vast amounts of information, often called "big data." Billion by 2026.
Enter Azure Databricks – the game-changing platform that empowers data professionals to streamline their workflows and unlock the limitless potential of their data. With Azure Databricks, managing and analyzing large volumes of data becomes effortlessly seamless. What is Azure Databricks Used for?
It is a comprehensive analytics solution that integrates business intelligence, real-time analytics, data science, data engineering, data integration, and data warehousing. The job of a data engineer is to gather, process, and arrange data so that it can be used for analysis and decision-making.
You can now use Snowflake Notebooks to simplify the process of connecting to your data and to amplify your data engineering, analytics and machine learning workflows. Schedule data ingestion, processing, model training and insight generation to enhance efficiency and consistency in your dataprocesses.
In this blog, you’ll build a complete ETL pipeline in Python to perform data extraction from the Spotify API, followed by data manipulation and transformation for analysis. You’ll walk through each stage of the dataprocessingworkflow, similar to what’s used in production-grade systems.
The process of merging and integrating data from several sources into a logical, unified view of data is known as data integration. Data integration projects revolve around managing this process. Data integration processes typically involve three stages- extraction, transformation, and loading ( ETL ).
In fact, job postings for data engineers are expected to grow by 50% in the next few years, making it one of the most in-demand tech careers. If you’re searching for a way to tap into this growing field, mastering ETL processes is a critical first step. But what does it take to become an ETL Data Engineer?
Matt Harrison is a Python expert with a long history of working with data who now spends his time on consulting and training. What are some of the utility features that you have found most helpful for dataprocessing? Pandas is a tool that spans dataprocessing and data science.
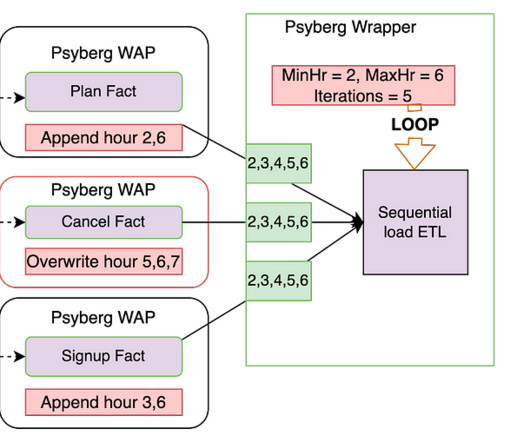
In the previous installments of this series, we introduced Psyberg and delved into its core operational modes: Stateless and Stateful DataProcessing. Pipelines After Psyberg Let’s explore how different modes of Psyberg could help with a multistep data pipeline. In this case, the minimum hour to process the data is hour 2.
This AWS data engineer roadmap unfolds a step-by-step guide through the AWS Data Engineer Certification process. FAQs on AWS Data Engineer Certification What is AWS Data Engineer Certification? Understanding of orchestration techniques and programming concepts for dataprocessing is also essential.
Using Artificial Intelligence (AI) in the Data Analytics process is the first step for businesses to understand AI's potential. AI for Data Analysis means leveraging AI techniques and algorithms to automate and improve the process of analyzing large datasets, extracting meaningful insights, and making data-driven decisions.
What are the different concerns that need to be included in a stack that supports fully automated dataworkflows? There was recently an interesting article suggesting that the "left-to-right" approach to dataworkflows is backwards.
Since all of Fabric’s tools run natively on OneLake, real-time performance without data duplication is possible in Direct Lake mode. Because of the architecture’s ability to abstract infrastructure complexity, users can focus solely on dataworkflows.
Traditional ETL processes have long been a bottleneck for businesses looking to turn raw data into actionable insights. Amazon, which generates massive volumes of data daily, faced this exact challenge. The idea of "Zero ETL" often creates the misconception that data transformation is no longer necessary.
Testing and Data Observability. Process Analytics. We have also included vendors for the specific use cases of ModelOps, MLOps, DataGovOps and DataSecOps which apply DataOps principles to machine learning, AI, data governance, and data security operations. . Reflow — A system for incremental dataprocessing in the cloud.
It is a cloud-based Microsoft tool that provides a cloud-based integration service for data analytics at scale and supports ETL and ELT paradigms. What sets Azure Data Factory apart from conventional ETL tools? Activities: Activities represent a processing step in a pipeline. What are the steps involved in an ETL process?
The dynamic nature of the consulting team meant that architectural decisions made at the data engineering level were often short-sighted and incoherent. The company incurred technical debt as consultants grafted one manually-driven exception process on top of another to adapt to evolving business requirements.
Whether you're an experienced data engineer or a beginner just starting, this blog series will have something for you. We'll explore various data engineering projects, from building data pipelines and ETL processes to creating data warehouses and implementing machine learning algorithms.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content