This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Unlocking Data Team Success: Are You Process-Centric or Data-Centric? Over the years of working with data analytics teams in large and small companies, we have been fortunate enough to observe hundreds of companies. We’ve identified two distinct types of data teams: process-centric and data-centric.
The typical pharmaceutical organization faces many challenges which slow down the data team: Raw, barely integrated data sets require engineers to perform manual , repetitive, error-prone work to create analyst-ready data sets. Cloud computing has made it much easier to integrate data sets, but that’s only the beginning.
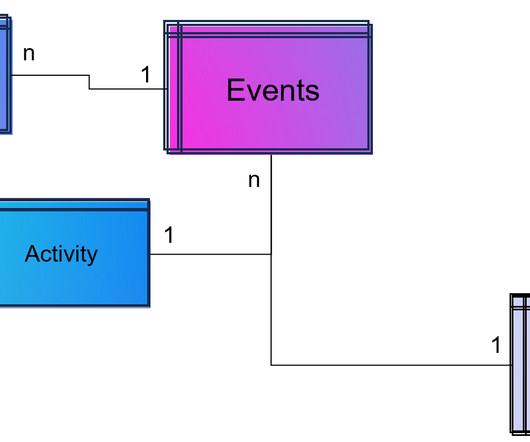
The Race For Data Quality In A Medallion Architecture The Medallion architecture pattern is gaining traction among data teams. It is a layered approach to managing and transforming data. By systematically moving data through these layers, the Medallion architecture enhances the data structure in a data lakehouse environment.
Part 2: Types of graph intelligence for combating fraud To gain intelligence for combating fraud via graph, there are two graph algorithms. -> Type 1: Vertex-centric intelligence Vertex-centric graph intelligence helps us quantify the likelihood that the user is a bad actor.
The fact that ETL tools evolved to expose graphical interfaces seems like a detour in the history of dataprocessing, and would certainly make for an interesting blog post of its own. Sure, there’s a need to abstract the complexity of dataprocessing, computation and storage.
Of course, this is not to imply that companies will become only software (there are still plenty of people in even the most software-centric companies), just that the full scope of the business is captured in an integrated software defined process. Here, the bank loan business division has essentially become software.
For those reasons, it is not surprising that it has taken over most of the modern data stack: infrastructure, databases, orchestration, dataprocessing, AI/ML and beyond. That’s without mentioning the fact that for a cloud-native company, Tableau’s Windows-centric approach at the time didn’t work well for the team.
It allows data scientists to analyze large datasets and interactively run jobs on them from the R shell. Big dataprocessing. Distributed: RDDs are distributed across the network, enabling them to be processed in parallel. Here are some of the possible use cases.
As the databases professor at my university used to say, it depends. Using SQL to run your search might be enough for your use case, but as your project requirements grow and more advanced features are needed—for example, enabling synonyms, multilingual search, or even machine learning—your relational database might not be enough.
The example we’ll walk you through will mirror a typical LLM application workflow you’d run to populate a vector database with some text knowledge. Specifically, we’ll cover pulling data from the web, creating text embeddings (vectors) and pushing them to a vector store. The application will receive a small data input (e.g.,
Hadoop and Spark are the two most popular platforms for Big Dataprocessing. They both enable you to deal with huge collections of data no matter its format — from Excel tables to user feedback on websites to images and video files. Obviously, Big Dataprocessing involves hundreds of computing units.
“The Snowflake Native App Framework really helps them give their customers the reassurance that their data is not traveling across the internet, and that they’re able to do all of their dataprocessing within their own environment.” One conversation quickly coming to the forefront is first-party data.
Data Engineers are skilled professionals who lay the foundation of databases and architecture. Using database tools, they create a robust architecture and later implement the process to develop the database from zero. Let us now understand the basic responsibilities of a Data engineer.
In addition to Business Intelligence (BI), Process Mining is no longer a new phenomenon, but almost all larger companies are conducting this data-driven process analysis in their organization. This aspect can be applied well to Process Mining, hand in hand with BI and AI.
But what about data engineers? A data scientist is only as good as the data they have access to. Most companies store their data in variety of formats across databases and text files. This is where data engineers come in — they build pipelines that transform that data into formats that data scientists can use.
When organizing vast amounts of data, Data Engineering skills are most important. Data must be comprehensive and cohesive, and Data Engineers are best at this task with their set of skills. Skills Required To Be A Data Engineer. Data Engineers must be proficient in Python to create complicated, scalable algorithms.
Data Engineers indulge in the whole dataprocess, from data management to analysis. Engineers work with Data Scientists to help make the most of the data they collect and have deep knowledge of distributed systems and computer science. Who is Data Engineer, and What Do They Do?
Big Data NoSQL databases were pioneered by top internet companies like Amazon, Google, LinkedIn and Facebook to overcome the drawbacks of RDBMS. RDBMS is not always the best solution for all situations as it cannot meet the increasing growth of unstructured data.
For Ripple's product capabilities, the Payments team of Ripple, for example, ingests millions of transactional records into databases and performs analytics to generate invoices, reports, and other related payment operations. A lack of a centralized system makes building a single source of high-quality data difficult.
Data Types Big DataData Mining Big data refers to robust and complicated datasets that require a high level of expertise and tools for managing, processing, or analyzing. Traditional dataprocessing techniques cannot be used.
Organisations are constantly looking for robust and effective platforms to manage and derive value from their data in the constantly changing landscape of data analytics and processing. These platforms provide strong capabilities for dataprocessing, storage, and analytics, enabling companies to fully use their data assets.
An Azure Data Engineer is a professional responsible for designing, implementing, and managing data solutions using Microsoft's Azure cloud platform. They work with various Azure services and tools to build scalable, efficient, and reliable data pipelines, data storage solutions, and dataprocessing systems.
This article presents the challenges associated with Build Analytics and the measures we adopted to enhance the efficiency of build processes at ThoughtSpot. This pipeline is designed to capture detailed data, process it efficiently, and provide actionable insights through ThoughtSpot’s powerful analytics features.
Data engineers can find one for almost any need, from data extraction to complex transformations, ensuring that they’re not reinventing the wheel by writing code that’s already been written. PySpark, for instance, optimizes distributed data operations across clusters, ensuring faster dataprocessing.
In this article, we’ll break down the intricacies of an end-to-end data pipeline and highlight its importance in today’s landscape. A visual maze: The tangled web of disparate tools commonly used in fragmented data pipelines. Playing the Field – Data Transformation: This is where the action happens.
Treating data as a product is more than a concept; it’s a paradigm shift that can significantly elevate the value that business intelligence and data-centric decision-making have on the business. It is the stage where data truly becomes a product, delivering tangible value to its end users.
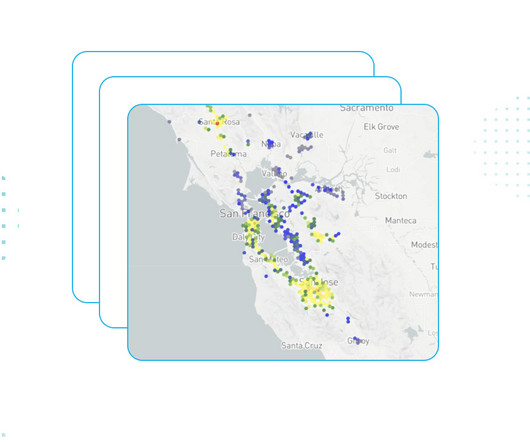
Over the last three geospatial-centric blog posts, weve covered the basics of what geospatial data is, how it works in the broader world of data and how it specifically works in Snowflake based on our native support for GEOGRAPHY , GEOMETRY and H3.
The demand for data-related professions, including data engineering, has indeed been on the rise due to the increasing importance of data-driven decision-making in various industries. Becoming an Azure Data Engineer in this data-centric landscape is a promising career choice.
Variety : Refers to the professed formats of data, from structured, numeric data in traditional databases, to unstructured text documents, emails, videos, audios, stock ticker data and financial transactions. Some examples of Big Data: 1. However, big data analytics and using big data tools must be learned.
This capability is particularly useful in complex data landscapes, where data may pass through multiple systems and transformations before reaching its final destination Impact analysis: When changes are made to data sources or dataprocessing systems, it’s critical to understand the potential impact on downstream processes and reports.
36 Give Data Products a Frontend with Latent Documentation Document more to help everyone 37 How Data Pipelines Evolve Build ELT at mid-range and move to data lakes when you need scale 38 How to Build Your Data Platform like a Product PM your data with business. Increase visibility. how fast are queries?
There are three types: Azure IR (fully managed serverless compute), Self-Hosted IR (for private network data stores), and Azure-SSIS IR (for running SSIS packages). Azure Data Factory Data Migration: Overview Cross-Region: Source & Sink Setup: Configure data source (storage accounts, databases) in both regions.
Studying data in deeper detail can help to identify the inefficiencies, bottlenecks or anomalies hence leading to quick actions resulting in efficient operations and reduced costs. Appreciated Customer Experience: The industry focuses on customer-centric approaches to enhance the overall customer experience.
Data Transformation Because of the many variations of source systems, the data collected during the ingestion phase is often raw, messy, and unstructured. In the ETL world, data transformation is intended to change the structure of the source data to match a specific target database schema, usually in the context of a data warehouse.
Not only that, but they are also responsible for working on web applications, content management systems, databases, and operating systems. I had earlier chosen KnowledgeHut’s training in Project Management to understand such processes efficiently.
Application Management Application management expertise is crucial in an Azure-centric ecosystem. Microsoft Certification: Azure Data Fundamentals Azure Data Fundamentals is designed for individuals who want to gain knowledge of data principles & core concepts related to Azure data services.
First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based data warehouse. Central Source of Truth for Analytics A Cloud Data Warehouse (CDW) is a type of database that provides analytical dataprocessing and storage capabilities within a cloud-based infrastructure.
Akka Streams then changed tact as streaming became the core mechanism to drive processors in a more data-centric manner. We think of streams and events much like database tables and rows; they are the basic building blocks of a data platform. The term is called turning the database inside out.
Storing events in a stream and connecting streams via stream processors provide a generic, data-centric, distributed application runtime that you can use to build ETL, event streaming applications, applications for recording metrics and anything else that has a real-time data requirement. Instrumentation plane.
Over the last three geospatial-centric blog posts, weve covered the basics of what geospatial data is, how it works in the broader world of data and how it specifically works in Snowflake based on our native support for GEOGRAPHY , GEOMETRY and H3.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content