This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary Dataprocessing technologies have dramatically improved in their sophistication and raw throughput. Unfortunately, the volumes of data that are being generated continue to double, requiring further advancements in the platform capabilities to keep up.
The typical pharmaceutical organization faces many challenges which slow down the data team: Raw, barely integrated data sets require engineers to perform manual , repetitive, error-prone work to create analyst-ready data sets. Cloud computing has made it much easier to integrate data sets, but that’s only the beginning.
With the Oxylabs scraper APIs you can extract data from even javascript heavy websites. Combined with their residential proxies you can be sure that you’ll have reliable and highqualitydata whenever you need it. With the Oxylabs scraper APIs you can extract data from even javascript heavy websites.
Summary Streaming dataprocessing enables new categories of data products and analytics. Unfortunately, reasoning about stream processing engines is complex and lacks sufficient tooling. Data lakes are notoriously complex. Data lakes are notoriously complex.
Data input and maintenance : Automation plays a key role here by streamlining how data enters your systems. With automation you become more agile, thanks to the ability to gather high-qualitydata efficiently and maintain it over time – reducing errors and manual processes. Find out more in our eBook.
Process-centric data teams focus their energies predominantly on orchestrating and automating workflows. They have demonstrated that robust, well-managed dataprocessing pipelines inevitably yield reliable, high-qualitydata. Over the years, we have also been helping data-centric data teams.
Avinash emphasized data readiness as a fundamental component that significantly impacts the timeline and effectiveness of integrating AI into production systems. He emphasized the following: - DataQuality: Consistent and high-qualitydata is crucial.
In order to build high-qualitydata lineage, we developed different techniques to collect data flow signals across different technology stacks: static code analysis for different languages, runtime instrumentation, and input and output data matching, etc.
I finally found a good critique that discusses its flaws, such as multi-hop architecture, inefficiencies, high costs, and difficulties maintaining dataquality and reusability.
In addition, AI data engineers should be familiar with programming languages such as Python , Java, Scala, and more for data pipeline, data lineage, and AI model development.
This was a great conversation about the complexities of working in a niche domain of data analysis and how to build a pipeline of highqualitydata from collection to analysis.
Data Governance & Ethics : Understand emerging data regulations and ethical frameworks that shape how organizations collect, store, and use data. Why Gartners Data & Analytics Summit Matters In a world where real-time insights and advanced analytics can make or break an enterprise, staying ahead of the curve is crucial.
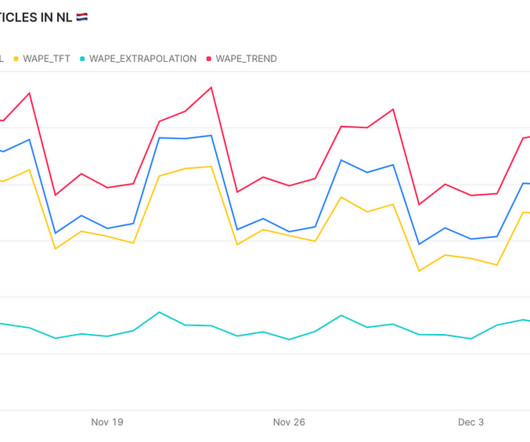
million customers worldwide, recognized how the immense volume of data they maintained could provide better insight into customers’ needs. Since leveraging Cloudera’s data platform, Rabobank has been able to improve its customers’ financial management. Rabobank , headquartered in the Netherlands with over 8.3
The fact that ETL tools evolved to expose graphical interfaces seems like a detour in the history of dataprocessing, and would certainly make for an interesting blog post of its own. Sure, there’s a need to abstract the complexity of dataprocessing, computation and storage.
Dataquality monitoring refers to the assessment, measurement, and management of an organization’s data in terms of accuracy, consistency, and reliability. It utilizes various techniques to identify and resolve dataquality issues, ensuring that high-qualitydata is used for business processes and decision-making.
Tools like BiG EVAL are leading dataquality field for all technical systems in which data is transported and transformed. BiG EVAL utilizes plausibility and validation mechanisms to adopt proactive quality assurance and enable short release cycles in agile projects as well.
Read Qualitydata you can depend on – today, tomorrow, and beyond For many years Precisely customers have ensured the accuracy of data across their organizations by leveraging our leading data solutions including Trillium Quality, Spectrum Quality, and Data360 DQ+. What does all this mean for your business?
Organizations should be careful not to automate business processes before considering which data sets those processes impact. Automation increases the potential to create a large volume of bad data very quickly. Digital transformation leverages data and new technologies to drive value through innovation and efficiency.
Sign up today for your free trial Sign up Making Your Data AI-Ready Using AI in data engineering workflows can automate processes including data acquisition, profiling, transformation, and cleansing – all with the goal of creating high-quality, accurate data that can be used to build and train effective AI models.
Orchestration & Dependencies : Involves the scheduling and coordination of multiple dataprocessing steps, ensuring each stage completes successfully before the next begins. As new data sources, dependencies, and compliance requirements emerge, adapting mitigation techniques will prevent disruptions and maintain data integrity.
Leveraging details about data and how it is processed enhances several key aspects of data management: Ensuring DataQuality Metadata ensures data accuracy and consistency by maintaining information about data sources, updates, and validation rules.
L1 is usually the raw, unprocessed data ingested directly from various sources; L2 is an intermediate layer featuring data that has undergone some form of transformation or cleaning; and L3 contains highly processed, optimized, and typically ready for analytics and decision-making processes. What is Data in Use?
See it for yourself: Check out a demo of Ascend’s new AI capabilities #2 - Expanded Data Engineering Capabilities Will Unlock Deeper Business Value With the demand for AI use cases climbing, the need to efficiently extract highqualitydata has introduced new opportunities and complexities.
The surge in package theft due to more online shopping overwhelmed traditional security measures and data management systems, which showcased significant operational vulnerabilities.
By adopting a set of best practices inspired by Agile methodologies, DevOps principles, and statistical process control techniques, DataOps helps organizations deliver high-qualitydata insights more efficiently.
A lack of a centralized system makes building a single source of high-qualitydata difficult. The key aspect of any business-centric team in delivering products and features is to make critical decisions on ensuring low latency, high throughput, cost-effective storage, and highly efficient infrastructure.
AI enhances predictive maintenance in several ways: Data Analysis: In real-time modes, AI processes large volumes of information while detecting any patterns or anomalies that could indicate an impending failure ahead of traditional monitoring systems.
The rich context provided by our Snowflake-powered Data Warehouse enhances their performance, allowing us to create a robust feature set for training. Training these models on our historical demand and assessing their performance is manageable as a one-time project since concepts like data drift are still not a big concern.
DBT’s superpowers include seamlessly connecting with databases and data warehouses, performing amazing transformations, and effortlessly managing dependencies to ensure high-qualitydata. Each successful deployment enriches its data ecosystem, empowering decision-makers with valuable, up-to-date insights.
As the use of AI becomes more ubiquitous across data organizations and beyond, dataquality rises in importance right alongside it. After all, you can’t have high-quality AI models without high-qualitydata feeding them. That’s like trying to cook something using only spoiled ingredients.
Consideration What to Look For Integration Capabilities Support for a diverse array of data sources and destinations, ensuring compatibility with your data ecosystem. Batch vs. Streaming Assess if your dataprocessing leans towards real-time analytics or if batch processing suffices for your use case.
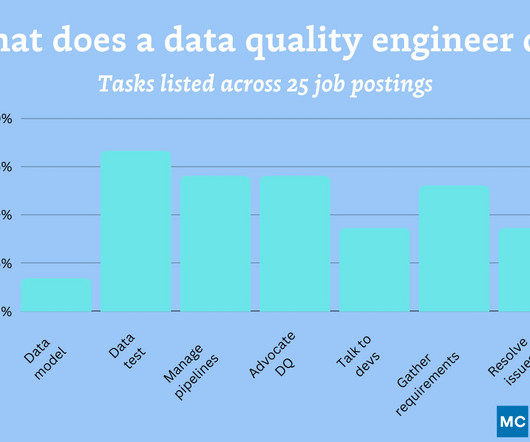
These specialists are also commonly referred to as data reliability engineers. To be successful in their role, dataquality engineers will need to gather dataquality requirements (mentioned in 65% of job postings) from relevant stakeholders.
An Azure Data Engineer is responsible for designing, implementing, and maintaining data management and dataprocessing systems on the Microsoft Azure cloud platform. They work with large and complex data sets and are responsible for ensuring that data is stored, processed, and secured efficiently and effectively.
And they need to learn from qualitydata. The same applies to machine learning — it needs high-qualitydata. How has your organization integrated AI and ML into its processes? For example, retail companies can operate without focusing on data, though being competitive is another matter.
Business Intelligence: Business Intelligence can handle moderate to large volumes of structured data. While it may not be designed specifically for big dataprocessing, it can integrate with dataprocessing technologies to analyze substantial amounts of data.
Data-driven Orientation: Both big data and machine learning embrace a data-centric approach. They prioritize the utilization of data to acquire insights, generate predictions, and inform decision-making. DataProcessing: Both big data and machine learning encompass the processing and examination of extensive datasets.
While data engineering and Artificial Intelligence (AI) may seem like distinct fields at first glance, their symbiosis is undeniable. The foundation of any AI system is high-qualitydata. Here lies the critical role of data engineering: preparing and managing data to feed AI models.
Azure Databricks Delta Live Table s: These provide a more straightforward way to build and manage Data Pipelines for the latest, high-qualitydata in Delta Lake. Azure Machine Learning can then use this data to train, test, and deploy machine learning models. It does the job.
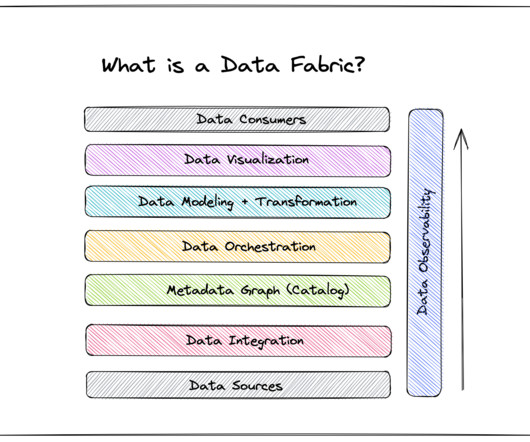
Reduced reliance on IT Integral to a data fabric is a set of pre-built models and algorithms that expedite dataprocessing. You can also feel confident that users at your organization will more readily adopt your data fabric, because they’ll know they can trust the insights it generates.
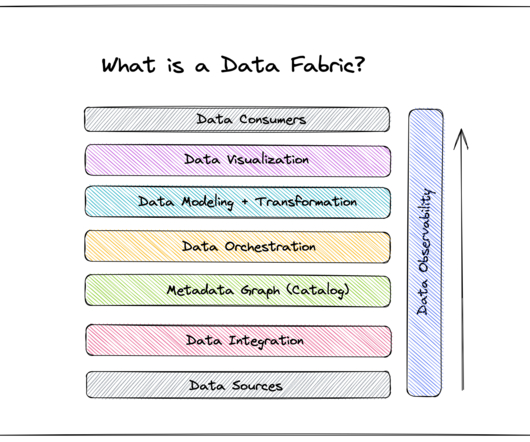
Reduced reliance on IT Integral to a data fabric is a set of pre-built models and algorithms that expedite dataprocessing. You can also feel confident that users at your organization will more readily adopt your data fabric, because they’ll know they can trust the insights it generates.
Gathering data at high velocities necessitates capturing and ingesting data streams as they occur, ensuring timely acquisition and availability for analysis. Utilizing is related to the dataprocessing and analyzing speed for gleaning useful insights.
Databand allows data engineering and data science teams to define dataquality rules, monitor data consistency, and identify data drift or anomalies. It also provides real-time notifications and alerts, enabling teams to proactively address issues and maintain high-qualitydata.
The problem: over-reliance on manual testing and a lack of visibility across domains Checkout.com’s decentralized data structure and reliance on manual tests and monitors meant that data engineering was a single point of failure for data issues. And I hope that this trend will continue moving forward.”
Technology According to a Glassdoor report, data engineering average salary at large companies generally ranges from S$86,288 to S$171,980. Data engineers in the technology industry focus on data streaming and dataprocessing pipelines. Size issues are another major data engineering issue for technology companies.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content