This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In recent years, quite a few organizations have preferred Java to meet their data science needs. From ERPs to web applications, Navigation Systems to Mobile Applications, Java has been facilitating advancement for more than a quarter of a century now. Is Learning Java Mandatory? So let us get to it.
However, one thing that has consistently been fundamental to the process is Java. The cross-platform flexibility I’ve had when working with Java is unparalleled. If you’re interested in software development, familiarity with Java is a non-negotiable aspect. Plus, it’s an excellent way to commence your software journey.
Apache Spark is one of the hottest and largest open source project in dataprocessing framework with rich high-level APIs for the programming languages like Scala, Python, Java and R. It realizes the potential of bringing together both Big Data and machine learning.
If you search top and highly effective programming languages for Big Data on Google, you will find the following top 4 programming languages: Java Scala Python R JavaJava is one of the oldest languages of all 4 programming languages listed here. Java is portable due to something called Java Virtual Machine – JVM.
Why do data scientists prefer Python over Java? Java vs Python for Data Science- Which is better? Which has a better future: Python or Java in 2021? These are the most common questions that our ProjectAdvisors get asked a lot from beginners getting started with a data science career. renamed to Java.
It provides high-level APIs in Java, Scala, Python, and R and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools, including Spark SQL for SQL and structured dataprocessing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming. exe file 3.
“Big data Analytics” is a phrase that was coined to refer to amounts of datasets that are so large traditional dataprocessing software simply can’t manage them. For example, big data is used to pick out trends in economics, and those trends and patterns are used to predict what will happen in the future.
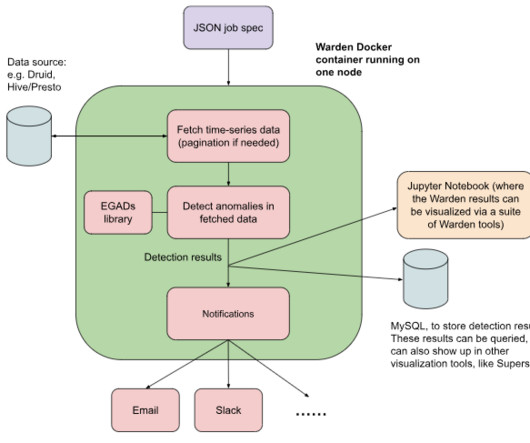
Charles Wu | Software Engineer; Isabel Tallam | Software Engineer; Kapil Bajaj | Engineering Manager Overview In this blog, we present a pragmatic way of integrating analytics, written in Python, with our distributed anomaly detection platform, written in Java. Background Warden is the distributed anomaly detection platform at Pinterest.
It has in-memory computing capabilities to deliver speed, a generalized execution model to support various applications, and Java, Scala, Python, and R APIs. Spark Streaming enhances the core engine of Apache Spark by providing near-real-time processing capabilities, which are essential for developing streaming analytics applications.
In addition to Python support, there is typically support for other programming languages, including JavaScript for web integration and Java for platform integration—though oftentimes with fewer features and less maturity. The Java developer imports it in Java for production deployment.
For most professionals who are from various backgrounds like - Java, PHP,net, mainframes, data warehousing, DBAs, data analytics - and want to get into a career in Hadoop and Big Data, this is the first question they ask themselves and their peers. Your search for the question “How much Java is required for Hadoop?”
Spark Streaming Kafka Streams 1 Data received from live input data streams is Divided into Micro-batched for processing. processes per data stream(real real-time) 2 A separate processing Cluster is required No separate processing cluster is required. Kafka keeps data in Topics, or in a memory buffer.
Most Popular Programming Certifications C & C++ Certifications Oracle Certified Associate Java Programmer OCAJP Certified Associate in Python Programming (PCAP) MongoDB Certified Developer Associate Exam R Programming Certification Oracle MySQL Database Administration Training and Certification (CMDBA) CCA Spark and Hadoop Developer 1.
PySpark is used to process real-time data with Kafka and Streaming, and this exhibits low latency. Multi-Language Support PySpark platform is compatible with various programming languages, including Scala, Java, Python, and R. Because of its interoperability, it is the best framework for processing large datasets.
Hadoop and Spark are the two most popular platforms for Big Dataprocessing. They both enable you to deal with huge collections of data no matter its format — from Excel tables to user feedback on websites to images and video files. Obviously, Big Dataprocessing involves hundreds of computing units.
Most cutting-edge technology organizations like Netflix, Apple, Facebook, and Uber have massive Spark clusters for dataprocessing and analytics. MapReduce is written in Java and the APIs are a bit complex to code for new programmers, so there is a steep learning curve involved.
Summary Real-time dataprocessing has steadily been gaining adoption due to advances in the accessibility of the technologies involved. To bring streaming data in reach of application engineers Matteo Pelati helped to create Dozer. To bring streaming data in reach of application engineers Matteo Pelati helped to create Dozer.
In addition, AI data engineers should be familiar with programming languages such as Python , Java, Scala, and more for data pipeline, data lineage, and AI model development.
Since all the flows were simple event processing, the NiFi flows were built out in a matter of hours (drag-and-drop) instead of months (coding in Java). . Because, they’ll be able to store massive amounts of data, process this data in real-time or batch, and serve the data to other applications.
Cluster Computing: Efficient processing of data on Set of computers (Refer commodity hardware here) or distributed systems. It’s also called a Parallel Dataprocessing Engine in a few definitions. Spark is utilized for Big data analytics and related processing. Happy Learning!!!
In the last years Spark has been powering a lot of data use cases but with the modern data stack and more recently with DuckDB, Polars and smaller size OLAP technologies it allows a new way to do dataprocessing. This is a must-read and a good showcase of what you can do. Kestra raises $3m Seed funding.
Authors: Bingfeng Xia and Xinyu Liu Background At LinkedIn, Apache Beam plays a pivotal role in stream processing infrastructures that process over 4 trillion events daily through more than 3,000 pipelines across multiple production data centers. The release of Apache Beam in 2016 proved to be a game-changer for LinkedIn.
💡 Additional big tech stuff to check: real-time ML training at Etsy and last mile dataprocessing with Ray at Pinterest. Scrape & analyse football data — Benoit nicely put in perspective how to use Kestra, Malloy and DuckDB to analyse data. A bittersweet feeling.
Discover the Flink Table API, which helps developers express complex dataprocessing in Java or Python. Get practical examples and guidance for your workflows.
Our tactical approach was to use Netflix-specific libraries for collecting traces from Java-based streaming services until open source tracer libraries matured. We chose Open-Zipkin because it had better integrations with our Spring Boot based Java runtime environment.
Event-driven and streaming architectures enable complex processing on market events as they happen, making them a natural fit for financial market applications. Flink SQL is a dataprocessing language that enables rapid prototyping and development of event-driven and streaming applications.
Your host is Tobias Macey and today I’m interviewing Shevek about Compilerworks and his work on writing compilers to automate data lineage tracking from your SQL code Interview Introduction How did you get involved in the area of data management? How are you applying compilers to the challenges of dataprocessing systems?
Summary A majority of the scalable dataprocessing platforms that we rely on are built as distributed systems. Kyle Kingsbury created the Jepsen framework for testing the guarantees of distributed dataprocessing systems and identifying when and why they break.
Event processing can also be stopped at any time by disabling the consumers in case production flow gets any impact with this parallel dataprocessing. For fast processing of the events, we use different settings of Kafka consumer and Java executor thread pool.
In this episode Andy Dang explains why the project was created, how you can apply it to your existing data systems, and how it functions to provide detailed context for being able to gain insight into all of your dataprocesses. How do you maintain feature parity between the Python and Java integrations?
Big data is a term that refers to the massive volume of data that organizations generate every day. In the past, this data was too large and complex for traditional dataprocessing tools to handle. There are a variety of big dataprocessing technologies available, including Apache Hadoop, Apache Spark, and MongoDB.
Some Kafka and Rockset users have also built real-time e-commerce applications , for example, using Rockset’s Java, Node.js ® , Go, and Python SDKs where an application can use SQL to query raw data coming from Kafka through an API (but that is a topic for another blog).
Snowpark is the set of libraries and runtimes that enables data engineers, data scientists and developers to build data engineering pipelines, ML workflows, and data applications in Python, Java, and Scala. Now users with USAGE privilege on the CHATGPT function can call this UDF.
Figure 2: Questions answered by precision medicine Snowflake and FAIR in the world of precision medicine and biomedical research Cloud-based big data technologies are not new for large-scale dataprocessing. A conceptual architecture illustrating this is shown in Figure 3.
The Rise of the Data Engineer The Downfall of the Data Engineer Functional Data Engineering — a modern paradigm for batch dataprocessing There is a global consensus stating that you need to master a programming language (Python or Java based) and SQL in order to be self-sufficient.
First, let's talk about the skill set required to become a good data scientist. A data scientist works with quantum computing. Therefore, the most important thing to know is programming languages like Java, Python, R, SAS, SQL, etc. Additionally, a data scientist understands Big Data frameworks like Pig, Spark, and Hadoop.
Because it is statically typed and object-oriented, Scala has often been considered a hybrid language used for data science between object-oriented languages like Java and functional ones like Haskell or Lisp. As a result, Java is the best coding language for data science. How Is Programming Used in Data Science?
In this article, we’ll explore what Snowflake Snowpark is, the unique functionalities it brings to the table, why it is a game-changer for developers, and how to leverage its capabilities for more streamlined and efficient dataprocessing. What Is Snowflake Snowpark?
In this blog we will explore how we can use Apache Flink to get insights from data at a lightning-fast speed, and we will use Cloudera SQL Stream Builder GUI to easily create streaming jobs using only SQL language (no Java/Scala coding required). Flink is a “streaming first” modern distributed system for dataprocessing.
0 — Quick Review Quickly, let’s review what spark does… Spark is a big dataprocessing engine. It takes python/java/scala/R/SQL and converts that code into a highly optimized set of transformations. At it’s lowest level, spark creates tasks, which are parallelizable transformations on data partitions. Let’s dive in!
But with the start of the 21st century, when data started to become big and create vast opportunities for business discoveries, statisticians were rightfully renamed into data scientists. Data scientists today are business-oriented analysts who know how to shape data into answers, often building complex machine learning models.
How much Java is required to learn Hadoop? “I want to work with big data and hadoop. If you want to work with big data , then learning Hadoop is a must - as it is becoming the de facto standard for big dataprocessing. Table of Contents Can students or professionals without Java knowledge learn Hadoop?
It provides high-level APIs in Java, Scala, Python, and R and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools, including Spark SQL for SQL and structured dataprocessing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming.
If you are using a Linux package such as DEB or RPM, this is usually in the /usr/share/java/kafka-connect-jdbc directory. If you’re installing from an archive, this will be in the share/java/kafka-connect-jdbc directory in your installation. Pere Urbón-Bayes is a technology architect for Confluent based out of Berlin, Germany.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content