This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
If you search top and highly effective programming languages for Big Data on Google, you will find the following top 4 programming languages: JavaScala Python R JavaJava is one of the oldest languages of all 4 programming languages listed here. Java is portable due to something called Java Virtual Machine – JVM.
Apache Spark is one of the hottest and largest open source project in dataprocessing framework with rich high-level APIs for the programming languages like Scala, Python, Java and R. It realizes the potential of bringing together both Big Data and machine learning.
The term Scala originated from “Scalable language” and it means that Scala grows with you. In recent times, Scala has attracted developers because it has enabled them to deliver things faster with fewer codes. Developers are now much more interested in having Scala training to excel in the big data field.
In recent years, quite a few organizations have preferred Java to meet their data science needs. From ERPs to web applications, Navigation Systems to Mobile Applications, Java has been facilitating advancement for more than a quarter of a century now. Is Learning Java Mandatory? So let us get to it.
Most cutting-edge technology organizations like Netflix, Apple, Facebook, and Uber have massive Spark clusters for dataprocessing and analytics. MapReduce is written in Java and the APIs are a bit complex to code for new programmers, so there is a steep learning curve involved.
It provides high-level APIs in Java, Scala, Python, and R and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools, including Spark SQL for SQL and structured dataprocessing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming.
Spark Streaming Kafka Streams 1 Data received from live input data streams is Divided into Micro-batched for processing. processes per data stream(real real-time) 2 A separate processing Cluster is required No separate processing cluster is required. Kafka keeps data in Topics, or in a memory buffer.
This article is all about choosing the right Scala course for your journey. How should I get started with Scala? Do you have any tips to learn Scala quickly? How to Learn Scala as a Beginner Scala is not necessarily aimed at first-time programmers. Which course should I take?
Spark offers over 80 high-level operators that make it easy to build parallel apps and one can use it interactively from the Scala, Python, R, and SQL shells. Cluster Computing: Efficient processing of data on Set of computers (Refer commodity hardware here) or distributed systems.
The thought of learning Scala fills many with fear, its very name often causes feelings of terror. The truth is Scala can be used for many things; from a simple web application to complex ML (Machine Learning). The name Scala stands for “scalable language.” So what companies are actually using Scala?
In addition, AI data engineers should be familiar with programming languages such as Python , Java, Scala, and more for data pipeline, data lineage, and AI model development.
“Big data Analytics” is a phrase that was coined to refer to amounts of datasets that are so large traditional dataprocessing software simply can’t manage them. For example, big data is used to pick out trends in economics, and those trends and patterns are used to predict what will happen in the future.
It has in-memory computing capabilities to deliver speed, a generalized execution model to support various applications, and Java, Scala, Python, and R APIs. It allows data scientists to analyze large datasets and interactively run jobs on them from the R shell. Big dataprocessing.
Why do data scientists prefer Python over Java? Java vs Python for Data Science- Which is better? Which has a better future: Python or Java in 2021? These are the most common questions that our ProjectAdvisors get asked a lot from beginners getting started with a data science career. renamed to Java.
Most Popular Programming Certifications C & C++ Certifications Oracle Certified Associate Java Programmer OCAJP Certified Associate in Python Programming (PCAP) MongoDB Certified Developer Associate Exam R Programming Certification Oracle MySQL Database Administration Training and Certification (CMDBA) CCA Spark and Hadoop Developer 1.
Summary A majority of the scalable dataprocessing platforms that we rely on are built as distributed systems. Kyle Kingsbury created the Jepsen framework for testing the guarantees of distributed dataprocessing systems and identifying when and why they break.
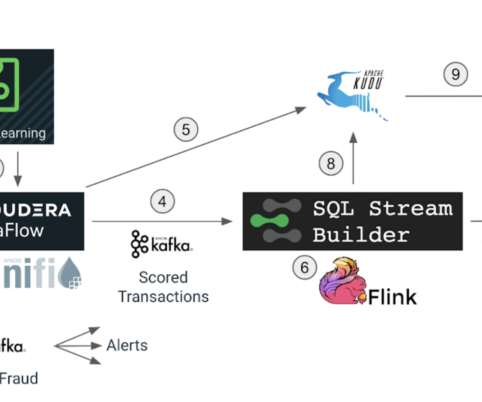
In this blog we will explore how we can use Apache Flink to get insights from data at a lightning-fast speed, and we will use Cloudera SQL Stream Builder GUI to easily create streaming jobs using only SQL language (no Java/Scala coding required). Flink is a “streaming first” modern distributed system for dataprocessing.
Snowpark is the set of libraries and runtimes that enables data engineers, data scientists and developers to build data engineering pipelines, ML workflows, and data applications in Python, Java, and Scala. Now users with USAGE privilege on the CHATGPT function can call this UDF.
Hadoop and Spark are the two most popular platforms for Big Dataprocessing. They both enable you to deal with huge collections of data no matter its format — from Excel tables to user feedback on websites to images and video files. Obviously, Big Dataprocessing involves hundreds of computing units.
0 — Quick Review Quickly, let’s review what spark does… Spark is a big dataprocessing engine. It takes python/java/scala/R/SQL and converts that code into a highly optimized set of transformations. At it’s lowest level, spark creates tasks, which are parallelizable transformations on data partitions.
Figure 2: Questions answered by precision medicine Snowflake and FAIR in the world of precision medicine and biomedical research Cloud-based big data technologies are not new for large-scale dataprocessing. A conceptual architecture illustrating this is shown in Figure 3.
Keep reading to know more about the data science coding languages. ScalaScala has become one of the most popular languages for AI and data science use cases. In addition, Scala has many features that make it an attractive choice for data scientists, including functional programming, concurrency, and high performance.
In this article, we’ll explore what Snowflake Snowpark is, the unique functionalities it brings to the table, why it is a game-changer for developers, and how to leverage its capabilities for more streamlined and efficient dataprocessing. What Is Snowflake Snowpark?
PySpark is used to process real-time data with Kafka and Streaming, and this exhibits low latency. Multi-Language Support PySpark platform is compatible with various programming languages, including Scala, Java, Python, and R. Because of its interoperability, it is the best framework for processing large datasets.
Apache Spark is the most efficient, scalable, and widely used in-memory data computation tool capable of performing batch-mode, real-time, and analytics operations. The next evolutionary shift in the dataprocessing environment will be brought about by Spark due to its exceptional batch and streaming capabilities.
Big data is a term that refers to the massive volume of data that organizations generate every day. In the past, this data was too large and complex for traditional dataprocessing tools to handle. There are a variety of big dataprocessing technologies available, including Apache Hadoop, Apache Spark, and MongoDB.
It provides high-level APIs in Java, Scala, Python, and R and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools, including Spark SQL for SQL and structured dataprocessing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming.
It can be used for web scraping, machine learning, and natural language processing. JavaJava, a general-purpose language, has found a niche in big data analytics. Libraries like Hadoop and Apache Flink, written in Java, are extensively used for dataprocessing in distributed computing environments.
But with the start of the 21st century, when data started to become big and create vast opportunities for business discoveries, statisticians were rightfully renamed into data scientists. Data scientists today are business-oriented analysts who know how to shape data into answers, often building complex machine learning models.
Proficiency in programming languages Even though in most cases data architects don’t have to code themselves, proficiency in several popular programming languages is a must. The candidates for this certification should be able to transform, integrate and consolidate both structured and unstructured data.
The data engineers are responsible for creating conversational chatbots with the Azure Bot Service and automating metric calculations using the Azure Metrics Advisor. Data engineers must know data management fundamentals, programming languages like Python and Java, cloud computing and have practical knowledge on data technology.
PySpark, for instance, optimizes distributed data operations across clusters, ensuring faster dataprocessing. Here’s how Python stacks up against SQL, Java, and Scala based on key factors: Feature Python SQL JavaScala Performance Offers good performance which can be enhanced using libraries like NumPy and Cython.
Certain roles like Data Scientists require a good knowledge of coding compared to other roles. Data Science also requires applying Machine Learning algorithms, which is why some knowledge of programming languages like Python, SQL, R, Java, or C/C++ is also required.
Data engineers design, manage, test, maintain, store, and work on the data infrastructure that allows easy access to structured and unstructured data. Data engineers need to work with large amounts of data and maintain the architectures used in various data science projects. Technical Data Engineer Skills 1.Python
Consumers in this context are anything that requests data; they could be stream processors, Java or.NET applications or KSQL server nodes. It’s more in line with a dataprocessing approach, where the incoming stream represents events. Horizontal scaling is achieved via partitions.
Apache Hive and Apache Spark are the two popular Big Data tools available for complex dataprocessing. To effectively utilize the Big Data tools, it is essential to understand the features and capabilities of the tools. Spark SQL, for instance, enables structured dataprocessing with SQL.
They are skilled in working with tools like MapReduce, Hive, and HBase to manage and process huge datasets, and they are proficient in programming languages like Java and Python. Using the Hadoop framework, Hadoop developers create scalable, fault-tolerant Big Data applications. What do they do?
As per Apache, “ Apache Spark is a unified analytics engine for large-scale dataprocessing ” Spark is a cluster computing framework, somewhat similar to MapReduce but has a lot more capabilities, features, speed and provides APIs for developers in many languages like Scala, Python, Java and R.
Whether you're working with semi-structured, structured, streaming, or machine learning data, Apache Spark is a fast, easy-to-use framework that allows you to solve various complex data issues. The Java API contains several convenience classes that help define DStream transformations, as we will see along the way.
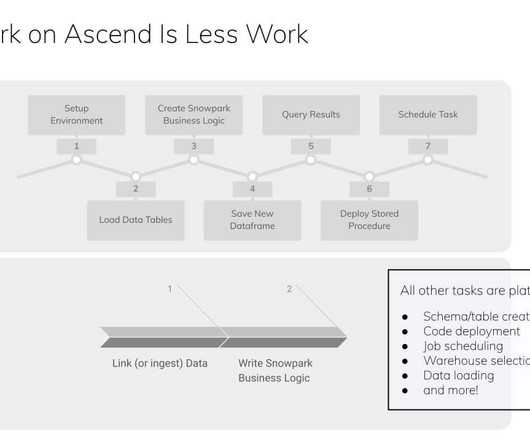
It empowers them to tap into the familiar terrain of languages like Scala, Java, and Python, but with the unique advantage of not having to move data out of Snowflake. Yet, the innovation doesn’t stop there. When you pair Snowpark with Ascend, the landscape changes entirely.
Here are some essential skills for data engineers when working with data engineering tools. Strong programming skills: Data engineers should have a good grasp of programming languages like Python, Java, or Scala, which are commonly used in data engineering.
Python Unstructured DataProcessing (PuPr) – Unstructured dataprocessing is now natively supported with Python. A few recent additions and libraries that will be landing soon include: langchain, implicit, imbalanced-learn, rapidfuzz, rdkit, mlforecast, statsforecast, scikit-optimize, scikit-surprise and more.
Announced at Summit, we’ve recently added to Snowpark the ability to process files programmatically, with Python in public preview and Java generally available. California Air Resources Board has been exploring processing atmospheric data delivered from four different remote locations via instruments that produce netCDF files.
This speed brings new efficiencies to tesa’s internal processes, and allows the company to experiment freely with an eye to improving the efficiency of its production. With dataprocessing and analytics, you sometimes want to fail fast to answer your most pressing production questions. That view can accelerate time to market.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content