This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It provides high-level APIs in Java, Scala, Python, and R and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools, including Spark SQL for SQL and structureddataprocessing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming.
Both traditional and AI data engineers should be fluent in SQL for managing structureddata, but AI data engineers should be proficient in NoSQL databases as well for unstructured data management.
It has in-memory computing capabilities to deliver speed, a generalized execution model to support various applications, and Java, Scala, Python, and R APIs. Spark Streaming enhances the core engine of Apache Spark by providing near-real-time processing capabilities, which are essential for developing streaming analytics applications.
Hadoop and Spark are the two most popular platforms for Big Dataprocessing. They both enable you to deal with huge collections of data no matter its format — from Excel tables to user feedback on websites to images and video files. Obviously, Big Dataprocessing involves hundreds of computing units.
To store and process even only a fraction of this amount of data, we need Big Data frameworks as traditional Databases would not be able to store so much data nor traditional processing systems would be able to process this data quickly. Spark can be used interactively also for dataprocessing.
PySpark is used to process real-time data with Kafka and Streaming, and this exhibits low latency. Multi-Language Support PySpark platform is compatible with various programming languages, including Scala, Java, Python, and R. Because of its interoperability, it is the best framework for processing large datasets.
Certain roles like Data Scientists require a good knowledge of coding compared to other roles. Data Science also requires applying Machine Learning algorithms, which is why some knowledge of programming languages like Python, SQL, R, Java, or C/C++ is also required.
It provides high-level APIs in Java, Scala, Python, and R and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools, including Spark SQL for SQL and structureddataprocessing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming.
A machine learning engineer should be an expert in popular programming languages such as C++, Java , and Python. Data-related expertise. Data is at the core of machine learning. So, a good machine learning engineer is well versed in datastructures, data modeling, and database management systems.
Pinterest’s real-time metrics asynchronous dataprocessing pipeline, powering Pinterest’s time series database Goku, stood at the crossroads of opportunity. The mission was clear: identify bottlenecks, innovate relentlessly, and propel our real-time analytics processing capabilities into an era of unparalleled efficiency.
Pig hadoop and Hive hadoop have a similar goal- they are tools that ease the complexity of writing complex java MapReduce programs. Generally data to be stored in the database is categorized into 3 types namely StructuredData, Semi StructuredData and Unstructured Data.
It is a crucial tool for data scientists since it enables users to create, retrieve, edit, and delete data from databases.SQL (Structured Query Language) is indispensable when it comes to handling structureddata stored in relational databases. Data scientists use SQL to query, update, and manipulate data.
Apache Hive and Apache Spark are the two popular Big Data tools available for complex dataprocessing. To effectively utilize the Big Data tools, it is essential to understand the features and capabilities of the tools. Spark SQL, for instance, enables structureddataprocessing with SQL.
Data Engineers are engineers responsible for uncovering trends in data sets and building algorithms and data pipelines to make raw data beneficial for the organization. This job requires a handful of skills, starting from a strong foundation of SQL and programming languages like Python , Java , etc.
Here are some essential skills for data engineers when working with data engineering tools. Strong programming skills: Data engineers should have a good grasp of programming languages like Python, Java, or Scala, which are commonly used in data engineering.
Announced at Summit, we’ve recently added to Snowpark the ability to process files programmatically, with Python in public preview and Java generally available. California Air Resources Board has been exploring processing atmospheric data delivered from four different remote locations via instruments that produce netCDF files.
In this article, we will discuss the 10 most popular Hadoop tools which can ease the process of performing complex data transformations. Hadoop is an open-source framework that is written in Java. It incorporates several analytical tools that help improve the data analytics process. What is Hadoop?
Choose Amazon S3 for cost-efficient storage to store and retrieve data from any cluster. It provides an efficient and flexible way to manage the large computing clusters that you need for dataprocessing, balancing volume, cost, and the specific requirements of your big data initiative.
Whether you're working with semi-structured, structured, streaming, or machine learning data, Apache Spark is a fast, easy-to-use framework that allows you to solve various complex data issues. The Java API contains several convenience classes that help define DStream transformations, as we will see along the way.
Apache Hadoop is an open-source Java-based framework that relies on parallel processing and distributed storage for analyzing massive datasets. Developed in 2006 by Doug Cutting and Mike Cafarella to run the web crawler Apache Nutch, it has become a standard for Big Data analytics. Low speed and no real-time dataprocessing.
Hadoop Sqoop and Hadoop Flume are the two tools in Hadoop which is used to gather data from different sources and load them into HDFS. Sqoop in Hadoop is mostly used to extract structureddata from databases like Teradata, Oracle, etc., Sqoop makes data analysis efficient.
In this blog on “Azure data engineer skills”, you will discover the secrets to success in Azure data engineering with expert tips, tricks, and best practices Furthermore, a solid understanding of big data technologies such as Hadoop, Spark, and SQL Server is required. Contents: Who is an Azure Data Engineer?
What is DataStructure? Datastructure is a method for effectively accessing and manipulating data by arranging and storing it in a computer's memory. DataStructure: Memory Representation Data Type Data types define the type of data a variable can hold.
Data Storage: The next step after data ingestion is to store it in HDFS or a NoSQL database such as HBase. HBase storage is ideal for random read/write operations, whereas HDFS is designed for sequential processes. DataProcessing: This is the final step in deploying a big data model. How to avoid the same.
More advanced datastructures, such as B-trees, are used to index objects stored in databases. Characteristics of DataStructuresDatastructures are frequently classed by their properties. This attribute indicates if all data items in a given repository are of the same type. Static or dynamic.
MapReduce Apache Spark Only batch-wise dataprocessing is done using MapReduce. Apache Spark can handle data in both real-time and batch mode. The data is stored in HDFS (Hadoop Distributed File System), which takes a long time to retrieve. MEMORY AND DISK: On the JVM, the RDDs are saved as deserialized Java objects.
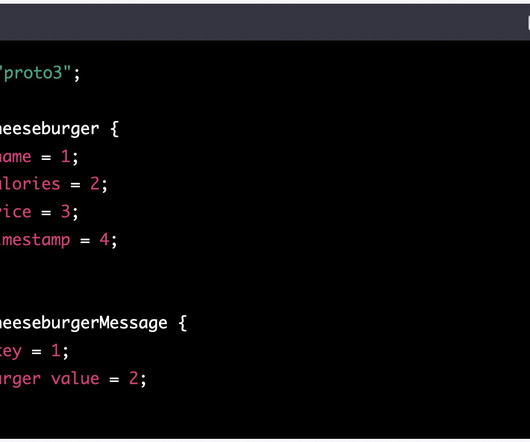
Example message: x16cheeseburgerx02xdcx07x9ax99x19x41x12xcdxccx0cx40xcexfax8excax1f Protocol buffers (usually called protobuf) Protobuf is a compact binary format that, like Avro, is designed for efficient serialization and deserialization of structureddata.
Applications of queue datastructure in computer science range from task scheduling and job management to print spooling and network data packet handling. They play a crucial role in facilitating organized and sequential dataprocessing. How Does It Work? Elements are enqueued i.e added to the end, and dequeued i.e
The growth in data has been so abrupt that even the existing warehousing platforms are unable to absorb, aggregate, transform and analyze it within the resource constraints. Once you learn Hadoop, you discover that it is a one stop, open source solution to the existing solutions related to unstructured data, process time and scalability.
Confused over which framework to choose for big dataprocessing - Hadoop MapReduce vs. Apache Spark. This blog helps you understand the critical differences between two popular big data frameworks. Hadoop and Spark are popular apache projects in the big data ecosystem. It allows you to process just a batch of stored data.
Data engineering is a new and ever-evolving field that can withstand the test of time and computing developments. Companies frequently hire certified Azure Data Engineers to convert unstructured data into useful, structureddata that data analysts and data scientists can use.
As MapReduce can run on low cost commodity hardware-it reduces the overall cost of a computing cluster but coding MapReduce jobs is not easy and requires the users to have knowledge of Java programming. To perform simple tasks like getting the average value or the count-users had to write complex Java based MapReduce programs.
Data preparation: Because of flaws, redundancy, missing numbers, and other issues, data gathered from numerous sources is always in a raw format. After the data has been extracted, data analysts must transform the unstructured data into structureddata by fixing data errors, removing unnecessary data, and identifying potential data.
Big data tools are used to perform predictive modeling, statistical algorithms and even what-if analyses. Some important big dataprocessing platforms are: Microsoft Azure. Why Is Big Data Analytics Important? Let's check some of the best big data analytics tools and free big data analytics tools.
Software engineers use software development processes to create software applications to meet requirements. Examples of such languages are C++, PHP, Java, HTML, Python, etc. It's known for being straightforward and readable and provides capabilities that cope with massive dataprocessing and large-scale programming.
To execute pipelines, beam supports numerous distributed processing back-ends, including Apache Flink, Apache Spark , Apache Samza, Hazelcast Jet, Google Cloud Dataflow, etc. With SQL, machine learning, real-time data streaming, graph processing, and other features, this leads to incredibly rapid big dataprocessing.
In 2010, a transformative concept took root in the realm of data storage and analytics — a data lake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. Structureddata sources.
As a result, there is a difference in the Big Data Engineer's salary by the skill-set. Datastructures, data modeling, and programming skills, for instance, are usually essential to work well as a Big Data Engineer. Real-time traffic analysis is another project for data professionals to explore.
Snowflake Data Marketplace gives users rapid access to various third-party data sources. Moreover, numerous sources offer unique third-party data that is instantly accessible when needed. Snowflake's machine learning partners transfer most of their automated feature engineering down into Snowflake's cloud data platform.
Skills The skills, roles, and responsibilities of a big data specialist in an organization vary; thus, there is a difference in the salary by the skill set. Datastructures, data modeling, and programming skills are essential.
Hadoop projects make optimum use of ever-increasing parallel processing capabilities of processors and expanding storage spaces to deliver cost-effective, reliable solutions. Owned by Apache Software Foundation, Apache Spark is an open-source dataprocessing framework. Why Apache Spark?
Big Data Hadoop Interview Questions and Answers These are Hadoop Basic Interview Questions and Answers for freshers and experienced. Hadoop vs RDBMS Criteria Hadoop RDBMS Datatypes Processes semi-structured and unstructured data. Processesstructureddata. are all examples of unstructured data.
Explore real-world examples, emphasizing the importance of statistical thinking in designing experiments and drawing reliable conclusions from data. Programming A minimum of one programming language, such as Python, SQL, Scala, Java, or R, is required for the data science field.
Random Job Distribution Coordinate resource management Self managed resources and worker ProcessStructured and Semi-StructuredData. Process Unstructured Data. InputSplit is a Java class that points to start and end location in the block. Related Posts How much Java is required to learn Hadoop?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content