This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Apache Kafka is an open-source publish-subscribe messaging application initially developed by LinkedIn in early 2011. It is a famous Scala-coded dataprocessing tool that offers low latency, extensive throughput, and a unified platform to handle the data in real-time.
Fluss is a compelling new project in the realm of real-time dataprocessing. It addresses many of Kafka's challenges in analytical infrastructure. The combination of Kafka and Flink is not a perfect fit for real-time analytics; the integration of Kafka and Lakehouse is very shallow.
And hence, there is a need to understand the concept of “stream processing “and the technology behind it. Spark Streaming Vs Kafka Stream Now that we have understood high level what these tools mean, it’s obvious to have curiosity around differences between both the tools. 7 Kafka stores data in Topic i.e., in a buffer memory.
Back in May 2017, we laid out why we believe that Kafka Streams is better off without a concept of watermarks or triggers , and instead opts for a continuous refinement model. By continuous refinement , I mean that Kafka Streams emits new results whenever records are updated. It is important for the operational characteristics, though.
In the early days, many companies simply used Apache Kafka ® for data ingestion into Hadoop or another data lake. However, Apache Kafka is more than just messaging. Some Kafka and Rockset users have also built real-time e-commerce applications , for example, using Rockset’s Java, Node.js
This data pipeline is a great example of a use case for Apache Kafka ®. The dataprocessing pipeline characterizes these objects, deriving key parameters such as brightness, color, ellipticity, and coordinate location, and broadcasts this information in alert packets. The case for Apache Kafka.
With the release of Apache Kafka ® 2.1.0, Kafka Streams introduced the processor topology optimization framework at the Kafka Streams DSL layer. This framework opens the door for various optimization techniques from the existing data stream management system (DSMS) and data stream processing literature.
How to Stream and Apply Real-Time Prediction Models on High-Throughput Time-Series Data Photo by JJ Ying on Unsplash Most of the stream processing libraries are not python friendly while the majority of machine learning and data mining libraries are python based. This design enables the re-reading of old messages.
A key challenge, however, is integrating devices and machines to process the data in real time and at scale. Apache Kafka ® and its surrounding ecosystem, which includes Kafka Connect, Kafka Streams, and KSQL, have become the technology of choice for integrating and processing these kinds of datasets.
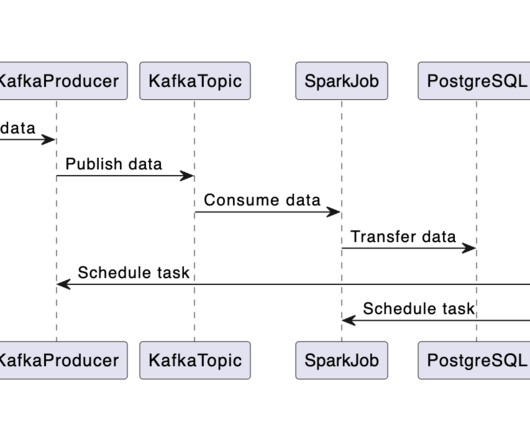
Ideal for those new to data systems or language model applications, this project is structured into two segments: This initial article guides you through constructing a data pipeline utilizing Kafka for streaming, Airflow for orchestration, Spark for data transformation, and PostgreSQL for storage. Image by the author.
CDC allows applications to respond to these changes in real-time, making it an essential component for data integration, replication, and synchronization. Real-Time DataProcessing : CDC enables real-time dataprocessing by capturing changes as they happen. Why is CDC Important?
Data consistency, feature reliability, processing scalability, and end-to-end observability are key drivers to ensuring business as usual (zero disruptions) and a cohesive customer experience. With our new dataprocessing framework, we were able to observe a multitude of benefits, including 99.9%
Kafka can continue the list of brand names that became generic terms for the entire type of technology. Similar to Google in web browsing and Photoshop in image processing, it became a gold standard in data streaming, preferred by 70 percent of Fortune 500 companies. What is Kafka? What Kafka is used for.
Organizations increasingly rely on streaming data sources not only to bring data into the enterprise but also to perform streaming analytics that accelerate the process of being able to get value from the data early in its lifecycle.
What are the use cases for Pravega and how does it fit into the data ecosystem? How does it compare with systems such as Kafka and Pulsar for ingesting and persisting unbounded data? One of the compelling aspects of Pravega is the automatic sharding and resource allocation for variations in data patterns.
After raw events are collected into a centralized queue, a custom event extractor processes this data to identify and extract all impression events. This refined output is then structured using an Avro schema, establishing a definitive source of truth for Netflixs impression data.
It means that there is a high risk of data loss but Apache Kafka solves this because it is distributed and can easily scale horizontally and other servers can take over the workload seamlessly. It offers a unified solution to real-time data needs any organisation might have. This is where Apache Kafka comes in.
To access real-time data, organizations are turning to stream processing. There are two main dataprocessing paradigms: batch processing and stream processing. Your electric consumption is collected during a month and then processed and billed at the end of that period.
Architectural Patterns for Data Quality Now we understand the trade-off between speed & correctness and the difference between data testing and observability. Let’s talk about the dataprocessing types. Two-Phase WAP The Two-Phase WAP, as the name suggests, follows two copy processes.
Setting the context, why would a customer want to use Apache NiFi, Apache Kafka, and Apache HBase? Because, they’ll be able to store massive amounts of data, process this data in real-time or batch, and serve the data to other applications.
Kafka, while not in the top 5 most in demand skills, was still the most requested buffer technology requested which makes it worthwhile to include it. I'll use Python and Spark because they are the top 2 requested skills in Toronto.
“Big data Analytics” is a phrase that was coined to refer to amounts of datasets that are so large traditional dataprocessing software simply can’t manage them. For example, big data is used to pick out trends in economics, and those trends and patterns are used to predict what will happen in the future.
Authors: Bingfeng Xia and Xinyu Liu Background At LinkedIn, Apache Beam plays a pivotal role in stream processing infrastructures that process over 4 trillion events daily through more than 3,000 pipelines across multiple production data centers.
The blog posts How to Build and Deploy Scalable Machine Learning in Production with Apache Kafka and Using Apache Kafka to Drive Cutting-Edge Machine Learning describe the benefits of leveraging the Apache Kafka ® ecosystem as a central, scalable and mission-critical nervous system. For now, we’ll focus on Kafka.
Did you know thousands of businesses, including over 80% of the Fortune 100, use Apache Kafka to modernize their data strategies? Apache Kafka is the most widely used open-source stream-processing solution for gathering, processing, storing, and analyzing large amounts of data. What is Apache Kafka Used For?
Think of it as the “slow and steady wins the race” approach to dataprocessing. Stream Processing Pattern Now, imagine if instead of waiting to do laundry once a week, you had a magical washing machine that could clean each piece of clothing the moment it got dirty.
Distributed transactions are very hard to implement successfully, which is why we’ll introduce a log-inspired system such as Apache Kafka ®. Building an indexing pipeline at scale with Kafka Connect. Moving data into Apache Kafka with the JDBC connector. Setting up the connector.
Photo by Leon S on Unsplash By: Jing Li Summary This article articulates the challenges, innovation and success of the Kafka implementation in Afterpay’s Global Payments Platform in the PCI zone. Context The asynchronous processing capability that Kafka offers opens up numerous innovation opportunities to interact with other services.
Confluent Cloud, a fully managed event cloud-native streaming service that extends the value of Apache Kafka ® , is simple, resilient, secure, and performant, allowing you to focus on what is important—building contextual event-driven applications, not infrastructure. KSQL and Kafka Connect example. and Helm/Tiller 2.8.2+
Overall Architecture The Data Mesh system can be divided into the control plane (Data Mesh Controller) and the data plane (Data Mesh Pipeline). Once deployed, the pipeline performs the actual heavy lifting dataprocessing work. Connectors A source connector is a Data Mesh managed producer.
Query your data in Kafka using SQL — This is a post that compares Flink, ksqlDB, Trino, Materialize, RisingWave and timeplus (the authors) in order to query Kafka. Even if it's vendor oriented this is a good starting point to have an overview of what you can expect from these tools.
Features of PySpark Features that contribute to PySpark's immense popularity in the industry- Real-Time Computations PySpark emphasizes in-memory processing, which allows it to perform real-time computations on huge volumes of data. PySpark is used to process real-time data with Kafka and Streaming, and this exhibits low latency.
Apache Kafka ® and its uses. The founders of Confluent originally created the open source project Apache Kafka while working at LinkedIn, and over recent years Kafka has become a foundational technology in the movement to event streaming. In retail, companies like Walmart , Target , and Nordstrom have adopted Kafka.
This episode promises invaluable insights into the shift from batch to real-time dataprocessing, and the practical applications across multiple industries that make this transition not just beneficial but necessary. Explore the intricate challenges and groundbreaking innovations in data storage and streaming.
This module can ingest live data streams from multiple sources, including Apache Kafka , Apache Flume , Amazon Kinesis , or Twitter, splitting them into discrete micro-batches. Netflix leverages Spark Streaming and Kafka for near real-time movie recommendations. Big dataprocessing.
On the dataprocessing side there is Polars, a DataFrame library that could replace pandas. How to land a job in progressive data — If you want to use your skills to Do Good you have to look at Brittany's post about progressive data. Let's have a quick look at it. I did not read it yet but it looks great.
Balancing the edge: Understanding the right balance between dataprocessing at the edge and in the cloud is a challenge, and this is why the entire data lifecycle needs to be considered. To keep the example simple, the following data attribute tags were chosen for each part generated by the factories: .
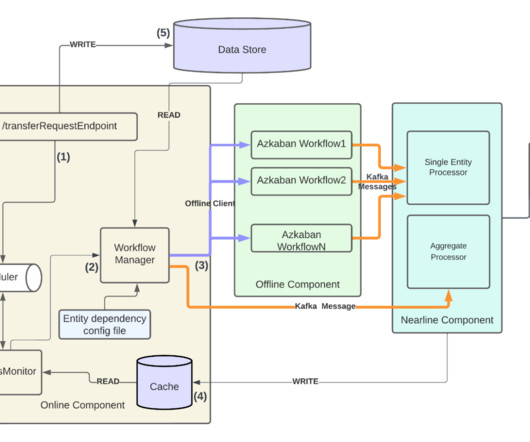
A data mesh can be defined as a collection of “nodes”, typically referred to as Data Products, each of which can be uniquely identified using four key descriptive properties: . The Value Proposition of CDF in Data Mesh Implementations.
I finally found a good critique that discusses its flaws, such as multi-hop architecture, inefficiencies, high costs, and difficulties maintaining data quality and reusability. The article advocates for a "shift left" approach to dataprocessing, improving data accessibility, quality, and efficiency for operational and analytical use cases.
How much configuration do you provide to the end user in terms of the captured data, such as sampling rate or additional context? I understand that your original architecture used RabbitMQ as your ingest mechanism, which you then migrated to Kafka. For someone who wants to start using ThreatStack, what does the setup process look like?
Pinterest’s real-time metrics asynchronous dataprocessing pipeline, powering Pinterest’s time series database Goku, stood at the crossroads of opportunity. The mission was clear: identify bottlenecks, innovate relentlessly, and propel our real-time analytics processing capabilities into an era of unparalleled efficiency.
Recently, we announced enhanced multi-function analytics support in Cloudera Data Platform (CDP) with Apache Iceberg. Iceberg is a high-performance open table format for huge analytic data sets. The post Streaming Ingestion for Apache Iceberg With Cloudera Stream Processing appeared first on Cloudera Blog.
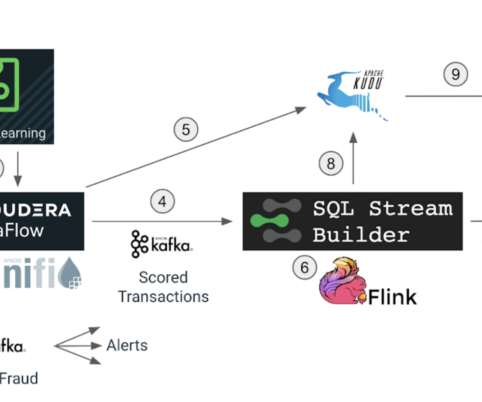
The streaming analytics process that we will implement in this blog aims to identify potentially fraudulent transactions by checking for transactions that happen at distant geographical locations within a short period of time. Flink is a “streaming first” modern distributed system for dataprocessing. Registering catalogs.
An AdTech company in the US provides processing, payment, and analytics services for digital advertisers. Dataprocessing and analytics drive their entire business. But an important caveat is that ingest speed, semantic richness for developers, data freshness, and query latency are paramount. Data Hub – .
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content