This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Apache Kafka is an open-source publish-subscribe messaging application initially developed by LinkedIn in early 2011. It is a famous Scala-coded dataprocessing tool that offers low latency, extensive throughput, and a unified platform to handle the data in real-time.
And hence, there is a need to understand the concept of “stream processing “and the technology behind it. Spark Streaming Vs Kafka Stream Now that we have understood high level what these tools mean, it’s obvious to have curiosity around differences between both the tools. 7 Kafka stores data in Topic i.e., in a buffer memory.
The term Scala originated from “Scalable language” and it means that Scala grows with you. In recent times, Scala has attracted developers because it has enabled them to deliver things faster with fewer codes. Developers are now much more interested in having Scala training to excel in the big data field.
Kafka can continue the list of brand names that became generic terms for the entire type of technology. Similar to Google in web browsing and Photoshop in image processing, it became a gold standard in data streaming, preferred by 70 percent of Fortune 500 companies. What is Kafka? What Kafka is used for.
The thought of learning Scala fills many with fear, its very name often causes feelings of terror. The truth is Scala can be used for many things; from a simple web application to complex ML (Machine Learning). The name Scala stands for “scalable language.” So what companies are actually using Scala?
“Big data Analytics” is a phrase that was coined to refer to amounts of datasets that are so large traditional dataprocessing software simply can’t manage them. For example, big data is used to pick out trends in economics, and those trends and patterns are used to predict what will happen in the future.
In addition, AI data engineers should be familiar with programming languages such as Python , Java, Scala, and more for data pipeline, data lineage, and AI model development.
Enjoy the Data News. Polars—Pandas are freezing Recently influencers are betting that Rust will be the de-facto language in data engineering. The history repeat, we've seen it with Scala, Go or even Julia at some scale. On the dataprocessing side there is Polars, a DataFrame library that could replace pandas.
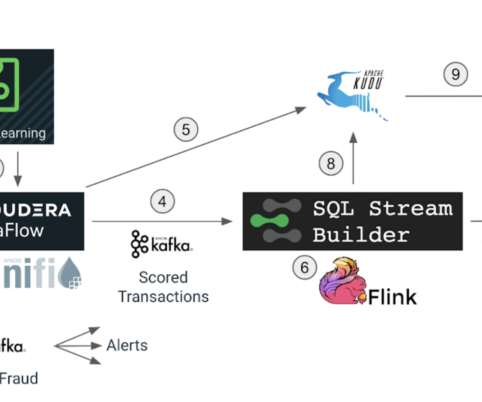
In this blog we will explore how we can use Apache Flink to get insights from data at a lightning-fast speed, and we will use Cloudera SQL Stream Builder GUI to easily create streaming jobs using only SQL language (no Java/Scala coding required). Flink is a “streaming first” modern distributed system for dataprocessing.
This article is all about choosing the right Scala course for your journey. How should I get started with Scala? Do you have any tips to learn Scala quickly? How to Learn Scala as a Beginner Scala is not necessarily aimed at first-time programmers. Which course should I take?
Spark offers over 80 high-level operators that make it easy to build parallel apps and one can use it interactively from the Scala, Python, R, and SQL shells. Cluster Computing: Efficient processing of data on Set of computers (Refer commodity hardware here) or distributed systems.
It has in-memory computing capabilities to deliver speed, a generalized execution model to support various applications, and Java, Scala, Python, and R APIs. Spark Streaming enhances the core engine of Apache Spark by providing near-real-time processing capabilities, which are essential for developing streaming analytics applications.
Features of PySpark Features that contribute to PySpark's immense popularity in the industry- Real-Time Computations PySpark emphasizes in-memory processing, which allows it to perform real-time computations on huge volumes of data. PySpark is used to process real-time data with Kafka and Streaming, and this exhibits low latency.
Use cases like fraud detection, network threat analysis, manufacturing intelligence, commerce optimization, real-time offers, instantaneous loan approvals, and more are now possible by moving the dataprocessing components up the stream to address these real-time needs. . What is Kafka blindness? Who is affected?
If you want to break into the field of data engineering but don't yet have any expertise in the field, compiling a portfolio of data engineering projects may help. Data pipeline best practices should be shown in these initiatives. Source Code: Stock and Twitter Data Extraction Using Python, Kafka, and Spark 2.
Apache Kafka is breaking barriers and eliminating the slow batch processing method that is used by Hadoop. This is just one of the reasons why Apache Kafka was developed in LinkedIn. Kafka was mainly developed to make working with Hadoop easier. This data is constantly changing, and is voluminous.
The open dataprocessing pipeline. IoT is expected to generate a volume and variety of data greatly exceeding what is being experienced today, requiring modernization of information infrastructure to realize value. The Enterprise Data Hub. Telemetry data routed to the Cloudera Enterprise Data Hub flows into Apache Kafka.
It serves as a foundation for the entire data management strategy and consists of multiple components including data pipelines; , on-premises and cloud storage facilities – data lakes , data warehouses , data hubs ;, data streaming and Big Data analytics solutions ( Hadoop , Spark , Kafka , etc.);
Apache Spark is the most efficient, scalable, and widely used in-memory data computation tool capable of performing batch-mode, real-time, and analytics operations. The next evolutionary shift in the dataprocessing environment will be brought about by Spark due to its exceptional batch and streaming capabilities.
Big data is a term that refers to the massive volume of data that organizations generate every day. In the past, this data was too large and complex for traditional dataprocessing tools to handle. There are a variety of big dataprocessing technologies available, including Apache Hadoop, Apache Spark, and MongoDB.
Hadoop and Spark are the two most popular platforms for Big Dataprocessing. They both enable you to deal with huge collections of data no matter its format — from Excel tables to user feedback on websites to images and video files. Obviously, Big Dataprocessing involves hundreds of computing units.
Apache Spark Streaming Use Cases Spark Streaming Architecture: Discretized Streams Spark Streaming Example in Java Spark Streaming vs. Structured Streaming Spark Streaming Structured Streaming What is Kafka Streaming? Kafka Stream vs. Spark Streaming What is Spark streaming? live logs, IoT device data, system telemetry data, etc.)
Data engineers design, manage, test, maintain, store, and work on the data infrastructure that allows easy access to structured and unstructured data. Data engineers need to work with large amounts of data and maintain the architectures used in various data science projects. Technical Data Engineer Skills 1.Python
As per Apache, “ Apache Spark is a unified analytics engine for large-scale dataprocessing ” Spark is a cluster computing framework, somewhat similar to MapReduce but has a lot more capabilities, features, speed and provides APIs for developers in many languages like Scala, Python, Java and R.
Source: The Data Team’s Guide to the Databricks Lakehouse Platform Integrating with Apache Spark and other analytics engines, Delta Lake supports both batch and stream dataprocessing. Besides that, it’s fully compatible with various data ingestion and ETL tools. Databricks two-plane infrastructure.
Here are some essential skills for data engineers when working with data engineering tools. Strong programming skills: Data engineers should have a good grasp of programming languages like Python, Java, or Scala, which are commonly used in data engineering.
Your search for Apache Kafka interview questions ends right here! Let us now dive directly into the Apache Kafka interview questions and answers and help you get started with your Big Data interview preparation! How to study for Kafka interview? What is Kafka used for? What are main APIs of Kafka?
But with the start of the 21st century, when data started to become big and create vast opportunities for business discoveries, statisticians were rightfully renamed into data scientists. Data scientists today are business-oriented analysts who know how to shape data into answers, often building complex machine learning models.
The team has also added the ability to run Scala for the SparkSQL engine. Kafka was the first, and soon enough, everybody was trying to grab their own share of the market. Flink 1.15.0 – What I like about this release of Flink, a top framework for streaming dataprocessing, is that it comes with quality documentation.
The team has also added the ability to run Scala for the SparkSQL engine. Kafka was the first, and soon enough, everybody was trying to grab their own share of the market. Flink 1.15.0 – What I like about this release of Flink, a top framework for streaming dataprocessing, is that it comes with quality documentation.
These certifications have big data training courses where tutors help you gain all the knowledge required for the certification exam. Programming Languages : Good command on programming languages like Python, Java, or Scala is important as it enables you to handle data and derive insights from it. Cost: $400 USD 4.
They are also accountable for communicating data trends. Let us now look at the three major roles of data engineers. Generalists They are typically responsible for every step of the dataprocessing, starting from managing and making analysis and are usually part of small data-focused teams or small companies.
You ought to be able to create a data model that is performance- and scalability-optimized. Programming and Scripting Skills Building dataprocessing pipelines requires knowledge of and experience with coding in programming languages like Python, Scala, or Java. The certification cost is $165 USD.
PySpark, for instance, optimizes distributed data operations across clusters, ensuring faster dataprocessing. Here’s how Python stacks up against SQL, Java, and Scala based on key factors: Feature Python SQL Java Scala Performance Offers good performance which can be enhanced using libraries like NumPy and Cython.
Some good options are Python (because of its flexibility and being able to handle many data types), as well as Java, Scala, and Go. Soft skills for data engineering Problem solving using data-driven methods It’s key to have a data-driven approach to problem-solving. Rely on the real information to guide you.
Azure Databricks Spark is a managed Spark service that lets you simplify and streamline the process of dataprocessing and data analytics. It provides a unified data analytics platform for data engineers, data analysts, data scientists, and machine learning engineers.
They also make use of ETL tools, messaging systems like Kafka, and Big Data Tool kits such as SparkML and Mahout. To become a Big Data Engineer, knowledge of Algorithms and Distributed Computing is also desirable. They need deep expertise in technologies like SQL, Python, Scala, Java, or C++.
Organisations are constantly looking for robust and effective platforms to manage and derive value from their data in the constantly changing landscape of data analytics and processing. These platforms provide strong capabilities for dataprocessing, storage, and analytics, enabling companies to fully use their data assets.
Azure Data Engineering is a rapidly growing field that involves designing, building, and maintaining dataprocessing systems using Microsoft Azure technologies. The popular big data and cloud computing tools Apache Spark , Apache Hive, and Apache Storm are among these.
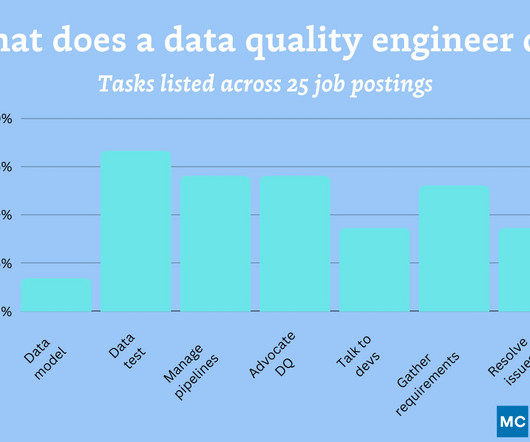
The skills, languages and tools of a data quality engineer Data quality engineers need to be highly skilled in multiple programming languages such as SQL (mentioned in 61% of postings), Python (56%), and Scala (13%). Document data quality issues, testing procedures, and resolutions for future reference and knowledge sharing.
We as Azure Data Engineers should have extensive knowledge of data modelling and ETL (extract, transform, load) procedures in addition to extensive expertise in creating and managing data pipelines, data lakes, and data warehouses.
Many top companies like Spotify, Uber, continue to use Java along with Python to host business-critical data science applications. Many data scientists tend to incline to Python and R for writing programs for analysis and processing of data. ND4J supports signal processing and linear algebra as well.
Here are some role-specific skills you should consider to become an Azure data engineer- Most data storage and processing systems use programming languages. Data engineers must thoroughly understand programming languages such as Python, Java, or Scala. Who should take the certification exam?
Here are some role-specific skills to consider if you want to become an Azure data engineer: Programming languages are used in the majority of data storage and processing systems. Data engineers must be well-versed in programming languages such as Python, Java, and Scala.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content