This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this guide, we’ll explore the patterns that can help you design data pipelines that actually work. Table of Contents Common Data Pipeline Design Patterns Explained 1. Batch Processing Pattern 2. Stream Processing Pattern 3. LambdaArchitecture Pattern 4. Kappa Architecture Pattern 5.
Aggregator Leaf Tailer (ALT) is the dataarchitecture favored by web-scale companies, like Facebook, LinkedIn, and Google, for its efficiency and scalability. In this blog post, I will describe the Aggregator Leaf Tailer architecture and its advantages for low-latency dataprocessing and analytics.
What are the prevailing architectural and technological patterns that are being used to manage these systems? The Lambdaarchitecture has largely been abandoned, so what is the answer for today’s data lakes? What are the challenges presented by streaming approaches to data transformations?
Balancing correctness, latency, and cost in unbounded dataprocessing Image created by the author. Intro Google Dataflow is a fully managed dataprocessing service that provides serverless unified stream and batch dataprocessing. Table of contents Before we move on Introduction from the paper.
Fluss is a compelling new project in the realm of real-time dataprocessing. Confluent Tableflow can bridge Kafka and Iceberg data, but that is just a data movement that data integration tools like Fivetran or Airbyte can also achieve.
Authors: Bingfeng Xia and Xinyu Liu Background At LinkedIn, Apache Beam plays a pivotal role in stream processing infrastructures that process over 4 trillion events daily through more than 3,000 pipelines across multiple production data centers.
Co-Authors: Yuhong Cheng , Shangjin Zhang , Xinyu Liu, and Yi Pan Efficient dataprocessing is crucial in reducing learning curves, simplifying maintenance efforts, and decreasing operational complexity. A PTransform represents a dataprocessing operation, or a step, in the pipeline.
An AdTech company in the US provides processing, payment, and analytics services for digital advertisers. Dataprocessing and analytics drive their entire business. Data streamed in is queryable immediately, in an optimal manner. Data Model. Conventional enterprise data types. General Purpose RTDW.
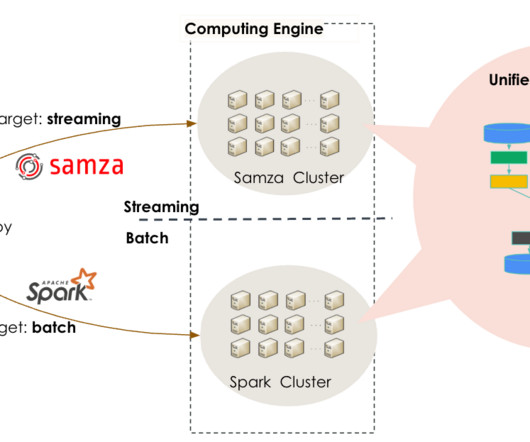
🤺🤺🤺🤺🤺🤺 [link] LinkedIn: Unified Streaming And Batch Pipelines At LinkedIn: Reducing Processing time by 94% with Apache Beam One of the curses of adopting LambdaArchitecture is the need for rewriting business logic in both streaming and batch pipelines.
Database makers have experimented with different designs to scale for bursts of data traffic without sacrificing speed, features or cost. LambdaArchitecture: Too Many Compromises A decade ago, a multitiered database architecture called Lambda began to emerge. Google and other web-scale companies also use ALT.
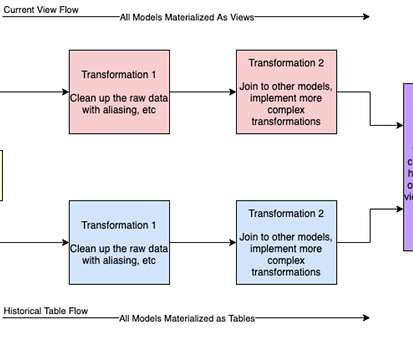
When your data is small enough, this is the preferred approach, however it isn’t scalable. Because dbt is primarily designed for batch-based dataprocessing, you should not schedule your dbt jobs to run continuously. Lambda views are a simple and readily available solution that is tool agnostic and SQL based.
Now, you might ask, “How is this different from data stack architecture, or dataarchitecture?” ” Data Stack Architecture : Your data stack architecture defines the technology and tools used to handle data, like databases, dataprocessing platforms, analytic tools, and programming languages.
[link] Sponsored: [Webinar] How to Scale Data Reliability Learn how Blend, a cloud infrastructure platform powering digital experiences for some of the world’s largest financial institutions, combined cloud-based data transformations and data observability to deliver trustworthy insights faster.
In this type of data ingestion, data moves in batches at regular intervals from source to destination. Some data teams will leverage micro-batch strategies for time sensitive use cases. These involve data pipelines that will ingest data every few hours or even minutes.
As per Apache, “ Apache Spark is a unified analytics engine for large-scale dataprocessing ” Spark is a cluster computing framework, somewhat similar to MapReduce but has a lot more capabilities, features, speed and provides APIs for developers in many languages like Scala, Python, Java and R. billion (2019 - 2022).
to accumulate data over a given period for better analysis. There are many more aspects to it and one can learn them better if they work on a sample data aggregation project. Project Idea: Explore what is real-time dataprocessing, the architecture of a big data project, and data flow by working on a sample of big data.
[link] Alibaba: The Thinking and Design of a Quasi-Real-Time Data Warehouse with Stream and Batch Integration Time interval dataprocessing is the foundation of data engineering; regardless it’s batch or real-time. Each architectural pattern has its limitation.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content