This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this guide, we’ll explore the patterns that can help you design data pipelines that actually work. Table of Contents Common Data Pipeline Design Patterns Explained 1. Batch Processing Pattern 2. Stream Processing Pattern 3. LambdaArchitecture Pattern 4. Kappa Architecture Pattern 5.
In this blog post, I will describe the Aggregator Leaf Tailer architecture and its advantages for low-latency dataprocessing and analytics. To mitigate the delays inherent in MapReduce, the Lambdaarchitecture was conceived to supplement batch results from a MapReduce system with a real-time stream of updates.
An AdTech company in the US provides processing, payment, and analytics services for digital advertisers. Dataprocessing and analytics drive their entire business. Data streamed in is queryable immediately, in an optimal manner. Data Model. Conventional enterprise data types. General Purpose RTDW.
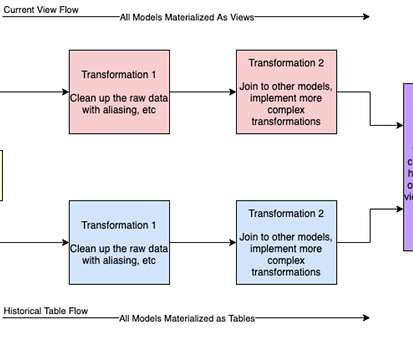
When your data is small enough, this is the preferred approach, however it isn’t scalable. Because dbt is primarily designed for batch-based dataprocessing, you should not schedule your dbt jobs to run continuously. Lambda views are a simple and readily available solution that is tool agnostic and SQL based.
Now, you might ask, “How is this different from data stack architecture, or dataarchitecture?” ” Data Stack Architecture : Your data stack architecture defines the technology and tools used to handle data, like databases, dataprocessing platforms, analytic tools, and programming languages.
In this type of data ingestion, data moves in batches at regular intervals from source to destination. Some data teams will leverage micro-batch strategies for time sensitive use cases. These involve data pipelines that will ingest data every few hours or even minutes.
Within no time, most of them are either data scientists already or have set a clear goal to become one. Nevertheless, that is not the only job in the data world. And, out of these professions, this blog will discuss the data engineering job role. to accumulate data over a given period for better analysis.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













Let's personalize your content