This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Batch dataprocessing — historically known as ETL — is extremely challenging. In this post, we’ll explore how applying the functional programming paradigm to data engineering can bring a lot of clarity to the process. It’s time-consuming, brittle, and often unrewarding.
Understanding the nature of the late-arriving data and processing requirements will help decide which pattern is most appropriate for a use case. Stateful DataProcessing : This pattern is useful when the output depends on a sequence of events across one or more input streams.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Missing data? Atlan is the metadata hub for your data ecosystem. Missing data? Stale dashboards?
This is where multimodal analysis unlocks its true potential by combining traditional structured data with these rich visual insights, creating a more comprehensive business understanding. In manufacturing, facilities are able to prevent costly defects by linking visual inspection data with production specifications.
Metadata is the information that provides context and meaning to data, ensuring it’s easily discoverable, organized, and actionable. It enhances data quality, governance, and automation, transforming raw data into valuable insights. This is what managing data without metadata feels like. Chaos, right?
Data consistency, feature reliability, processing scalability, and end-to-end observability are key drivers to ensuring business as usual (zero disruptions) and a cohesive customer experience. With our new dataprocessing framework, we were able to observe a multitude of benefits, including 99.9%
This approach is exemplified in the following code snippet: During runtime execution, Privacy Probes does the following: Capturing payloads : It captures source and sink payloads in memory on a sampled basis, along with supplementary metadata such as event timestamps, asset identifiers, and stack traces as evidence for the data flow.
Examples include “reduce dataprocessing time by 30%” or “minimize manual data entry errors by 50%.” It aims to streamline and automate data workflows, enhance collaboration and improve the agility of data teams. How effective are your current data workflows?
First, we create an Iceberg table in Snowflake and then insert some data. Then, we add another column called HASHKEY , add more data, and locate the S3 file containing metadata for the iceberg table. In the screenshot below, we can see that the metadata file for the Iceberg table retains the snapshot history.
Obviously not all tools are made with the same use case in mind, so we are planning to add more code samples for other (than classical batch ETL) dataprocessing purposes, e.g. Machine Learning model building and scoring. The main workflow definition file holds the logic of a single run, in this case one day-worth of data.
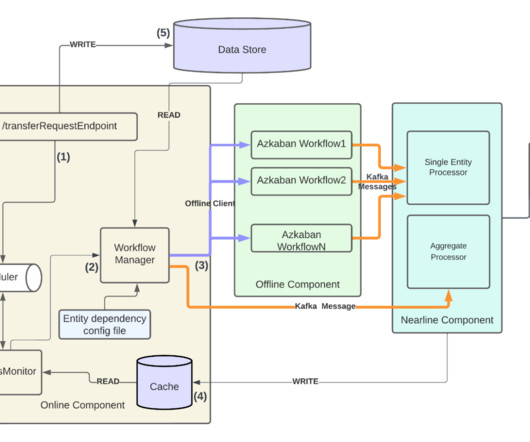
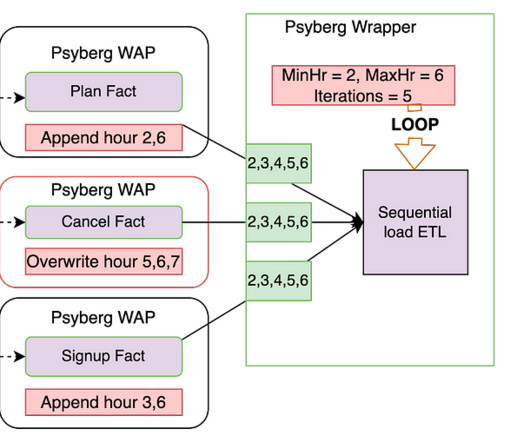
In this context, managing the data, especially when it arrives late, can present a substantial challenge! In this three-part blog post series, we introduce you to Psyberg , our incremental dataprocessing framework designed to tackle such challenges! Let’s dive in! To solve these problems, we came up with Psyberg!
Behind the scenes, Snowpark ML parallelizes dataprocessing operations by taking advantage of Snowflake’s scalable computing platform. For Snowpark ML Operations, the Snowpark Model Registry allows customers to securely manage and execute models in Snowflake, regardless of origin.
Also, the associated business metadata for omics, which make it findable for later use, are dynamic and complex and need to be captured separately. Additionally, the fact that they need to be standardized makes the data discovery effort challenging for downstream analysis.
Examples include “reduce dataprocessing time by 30%” or “minimize manual data entry errors by 50%.” It aims to streamline and automate data workflows, enhance collaboration and improve the agility of data teams. How effective are your current data workflows?
In the previous installments of this series, we introduced Psyberg and delved into its core operational modes: Stateless and Stateful DataProcessing. Pipelines After Psyberg Let’s explore how different modes of Psyberg could help with a multistep data pipeline. Audit Run various quality checks on the staged data.
Once the batch has been queued for processing, we copy the list of user IDs who have made requests in that batch into a new Hive table. For each data logs table, we initiate a new worker task that fetches the relevant metadata describing how to correctly query the data.
Application Logic: Application logic refers to the type of dataprocessing, and can be anything from analytical or operational systems to data pipelines that ingest data inputs, apply transformations based on some business logic and produce data outputs.
Fluss is a compelling new project in the realm of real-time dataprocessing. A Fluss cluster consists of two main processes: the CoordinatorServer and the TabletServer. It maintains metadata, manages tablet allocation, lists nodes, and handles permissions.
Engineers from across the company came together to share best practices on everything from DataProcessing Patterns to Building Reliable Data Pipelines. The result was a series of talks which we are now sharing with the rest of the Data Engineering community!
The fact that ETL tools evolved to expose graphical interfaces seems like a detour in the history of dataprocessing, and would certainly make for an interesting blog post of its own. Sure, there’s a need to abstract the complexity of dataprocessing, computation and storage.
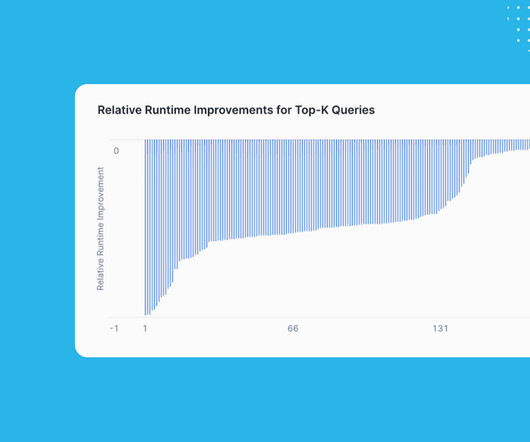
Algorithmic perspective: From an algorithmic perspective, we implemented a way to process partitions in a smart order, which further reduces the number of I/Os. Before Snowflake starts executing the query, we look at the metadata of the partitions to determine whether the contents of a given partition are likely to end up in the final result.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. RudderStack helps you build a customer data platform on your warehouse or data lake.
link] Gradient Flow: Paradigm Shifts in DataProcessing for the Generative AI Era dataprocessing pipelines haven't kept pace with the rapid advancement of AI models The article highlights the growing importance of preprocessing data pipelines, but the pipeline processing techniques do not match the demand.
CDC allows applications to respond to these changes in real-time, making it an essential component for data integration, replication, and synchronization. Real-Time DataProcessing : CDC enables real-time dataprocessing by capturing changes as they happen. Why is CDC Important?
Metadata and evolution support : We’ve added structured-type schema evolution for flexibility as source systems or business reporting needs change. Get better Iceberg ecosystem interoperability with Primary Key information added to Iceberg table metadata.
The author emphasizes the importance of mastering state management, understanding "local first" dataprocessing (prioritizing single-node solutions before distributed systems), and leveraging an asset graph approach for data pipelines.
Collecting raw impression events Filtering & Enriching Raw Impressions Once the raw impression events are queued, a stateless Apache Flink job takes charge, meticulously processing this data. This refined output is then structured using an Avro schema, establishing a definitive source of truth for Netflixs impression data.
We all know that data freshness plays a critical role in the performance of Lakehouse. If we can place the metadata, indexing, and recent data files in Express One, we can potentially build a Snowflake-style performant architecture in Lakehouse. Apache Hudi, for example, introduces an indexing technique to Lakehouse.
It allows data scientists to analyze large datasets and interactively run jobs on them from the R shell. Big dataprocessing. When transformations are applied to RDDs, Spark records the metadata to build up a DAG, which reflects the sequence of computations performed during the execution of the Spark job.
Learn more about the impacts of global data sharing in this blog, The Ethics of Data Exchange. Before we jump into the data ingestion step, here is a quick overview of how Ozone manages its metadata namespace through volumes, buckets and keys. . Data ingestion through ‘s3’. Dataprocessing and visualization.
Airflow stores metadata in it (DAG runs, XComs, Task instances, etc. It is also essential to understand what Airflow is not – it’s neither a streaming solution nor a dataprocessing framework. The Meta database: Database compatible with SqlAlchemy.
The data engineering landscape is constantly changing but major trends seem to remain the same. How to Become a Data Engineer As a data engineer, I am tasked to design efficient dataprocesses almost every day. It was created by Spotify to manage massive dataprocessing workloads.
Architectural Patterns for Data Quality Now we understand the trade-off between speed & correctness and the difference between data testing and observability. Let’s talk about the dataprocessing types. Two-Phase WAP The Two-Phase WAP, as the name suggests, follows two copy processes.
Data users in these enterprises don’t know how data is derived and lack confidence in whether it’s the right source to use. . If data access policies and lineage aren’t consistent across an organization’s private cloud and public clouds, gaps will exist in audit logs. From Bad to Worse.
Question to the readers, what do you think of the current state of real-time dataprocessing engines? link] Influx Data: How Good is Parquet for Wide Tables (Machine Learning Workloads) Really? Are there enough usecases? Is parquet is still good enough for Machine Learning, Vector and Lake House workloads?
AWS Glue is a widely-used serverless data integration service that uses automated extract, transform, and load ( ETL ) methods to prepare data for analysis. It offers a simple and efficient solution for dataprocessing in organizations. Then, Glue writes the job's metadata into the embedded AWS Glue Data Catalog.
During the transformation phase, data is processed and converted into the appropriate format for the target destination. While legacy ETL has a slow transformation step, modern ETL platforms replace disk-based processing with in-memory processing to allow for real-time dataprocessing, enrichment, and analysis.
We recently announced Snowpark ML Modeling API (generally available soon), which enables the use of popular ML frameworks such as Scikit-learn and XGBoost for feature engineering and model training without moving data out of Snowflake. Snowpark ML enables intuitive model development using these frameworks through familiar Python APIs.
Hadoop and Spark are the two most popular platforms for Big Dataprocessing. They both enable you to deal with huge collections of data no matter its format — from Excel tables to user feedback on websites to images and video files. Obviously, Big Dataprocessing involves hundreds of computing units.
Matt Harrison is a Python expert with a long history of working with data who now spends his time on consulting and training. You can observe your pipelines with built in metadata search and column level lineage. What are some of the utility features that you have found most helpful for dataprocessing?
Having carefully built this feature to minimize attack surface and external dataprocessing, we are able to help protect users from not only unwanted contact, but also cyber attacks and spyware. Protect your IP address metadata in calls Two common methods of connecting call participants: peer-to-peer and via a relay.
The table information (such as schema, partition) is stored as part of the metadata (manifest) file separately, making it easier for applications to quickly integrate with the tables and the storage formats of their choice. Change data capture (CDC). 3: Open Performance.
With in-place table migration, you can rapidly convert to Iceberg tables since there is no need to regenerate data files. Only metadata will be regenerated. Newly generated metadata will then point to source data files as illustrated in the diagram below. . Data quality using table rollback. Metadata management .
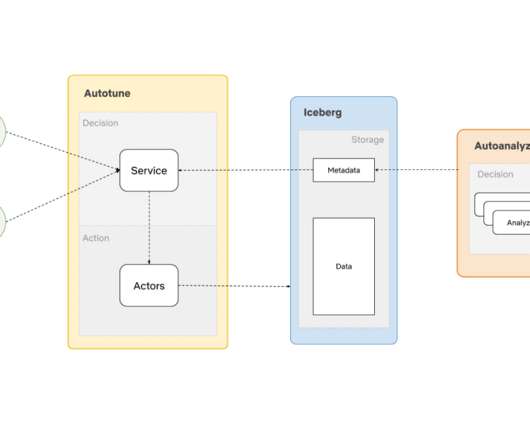
On the other hand, these optimizations themselves need to be sufficiently inexpensive to justify their own processing cost over the gains they bring. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content