This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction In today’s data-driven world, organizations across industries are dealing with massive volumes of data, complex pipelines, and the need for efficient dataprocessing.
I've always considered horizontal scaling as the single true scaling policy for elastic dataprocessing pipelines. The "vertical scaling" has caught my attention a few times already when I have been reading about cloud updates. Have I been wrong?
Behind the scenes, hundreds of ML engineers iteratively improve a wide range of recommendation engines that power Pinterest, processing petabytes of data and training thousands of models using hundreds of GPUs. In some cases, petabytes of data are streamed into training jobs to train a model.
Summary Dataprocessing technologies have dramatically improved in their sophistication and raw throughput. Unfortunately, the volumes of data that are being generated continue to double, requiring further advancements in the platform capabilities to keep up.
Real-time dataprocessing can satisfy the ever-increasing demand for… Read more The post 5 Real-Time DataProcessing and Analytics Technologies – And Where You Can Implement Them appeared first on Seattle Data Guy.
Data Management A tutorial on how to use VDK to perform batch dataprocessing Photo by Mika Baumeister on Unsplash Versatile Data Ki t (VDK) is an open-source data ingestion and processing framework designed to simplify data management complexities.
By Abhinaya Shetty , Bharath Mummadisetty In the inaugural blog post of this series, we introduced you to the state of our pipelines before Psyberg and the challenges with incremental processing that led us to create the Psyberg framework within Netflix’s Membership and Finance data engineering team.
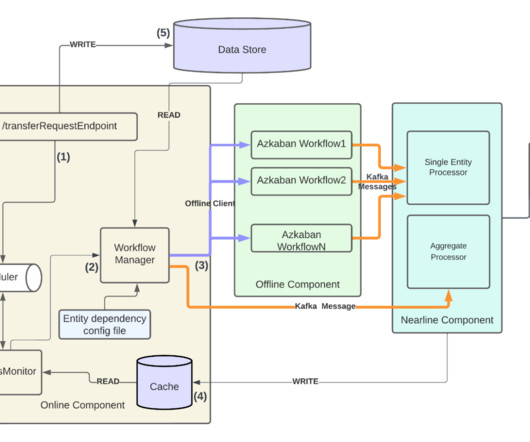
This multi-entity handover process involves huge amounts of data updating and cloning. Data consistency, feature reliability, processing scalability, and end-to-end observability are key drivers to ensuring business as usual (zero disruptions) and a cohesive customer experience. Push for eventual success of the request.
Unlocking Data Team Success: Are You Process-Centric or Data-Centric? Over the years of working with data analytics teams in large and small companies, we have been fortunate enough to observe hundreds of companies. We want to share our observations about data teams, how they work and think, and their challenges.
StreamNative, a leading Apache Pulsar-based real-time data platform solutions provider, and Databricks, the Data Intelligence Platform, are thrilled to announce the enhanced Pulsar-Spark.
Summary Streaming dataprocessing enables new categories of data products and analytics. Unfortunately, reasoning about stream processing engines is complex and lacks sufficient tooling. Support Data Engineering Podcast Summary Streaming dataprocessing enables new categories of data products and analytics.
Data and process automation used to be seen as luxury but those days are gone. Lets explore the top challenges to data and process automation adoption in more detail. Almost half of respondents (47%) reported a medium level of automation adoption, meaning they currently have a mix of automated and manual SAP processes.
Let’s learn what… Continue reading on Towards Data Science » In this first article, we’re exploring Apache Beam, from a simple pipeline to a more complicated one, using GCP Dataflow.
What is Real-Time Stream Processing? In today’s fast-moving world, companies need to glean insights from data as soon as it’s generated. To access real-time data, organizations are turning to stream processing. To access real-time data, organizations are turning to stream processing.
Authors: Bingfeng Xia and Xinyu Liu Background At LinkedIn, Apache Beam plays a pivotal role in stream processing infrastructures that process over 4 trillion events daily through more than 3,000 pipelines across multiple production data centers.
Balancing correctness, latency, and cost in unbounded dataprocessing Image created by the author. Intro Google Dataflow is a fully managed dataprocessing service that provides serverless unified stream and batch dataprocessing. Apache Beam lets users define processing logic based on the Dataflow model.
A collaborative and interactive workspace allows users to perform big dataprocessing and machine learning tasks easily. Introduction Azure Databricks is a fast, easy, and collaborative Apache Spark-based analytics platform that is built on top of the Microsoft Azure cloud.
Iceberg is a high-performance open table format for huge analytic data sets. It allows multiple dataprocessing engines, such as Flink, NiFi, Spark, Hive, and Impala to access and analyze data in simple, familiar SQL tables. This enables you to maximize utilization of streaming data at scale. Try it out yourself!
How to Stream and Apply Real-Time Prediction Models on High-Throughput Time-Series Data Photo by JJ Ying on Unsplash Most of the stream processing libraries are not python friendly while the majority of machine learning and data mining libraries are python based.
Discover the insights he gained from academia and industry, his perspective on the future of dataprocessing and the story behind building a next-generation graph database. Semih explains how Kuzu addresses the challenges of large graph analytics, the benefits of embeddability, and its potential for applications in AI and beyond.
Building efficient data pipelines with DuckDB 4.1. Use DuckDB to processdata, not for multiple users to access data 4.2. Cost calculation: DuckDB + Ephemeral VMs = dirt cheap dataprocessing 4.3. Processingdata less than 100GB? Introduction 2. Project demo 3. Use DuckDB 4.4.
Introduction Data engineering is the field of study that deals with the design, construction, deployment, and maintenance of dataprocessing systems. The goal of this domain is to collect, store, and processdata efficiently and efficiently so that it can be used to support business decisions and power data-driven applications.
Introduction Every data scientist demands an efficient and reliable tool to process this big unstoppable data. Today we discuss one such tool called Delta Lake, which data enthusiasts use to make their dataprocessing pipelines more efficient and reliable.
Introduction Big Data is a large and complex dataset generated by various sources and grows exponentially. It is so extensive and diverse that traditional dataprocessing methods cannot handle it. The volume, velocity, and variety of Big Data can make it difficult to process and analyze.
Introduction Big dataprocessing is crucial today. Big data analytics and learning help corporations foresee client demands, provide useful recommendations, and more. Hadoop, the Open-Source Software Framework for scalable and scattered computation of massive data sets, makes it easy.
However, we found that many of our workloads were bottlenecked by reading multiple terabytes of input data. To remove this bottleneck, we built AvroTensorDataset , a TensorFlow dataset for reading, parsing, and processing Avro data. If greater than one, records in files are processed in parallel.
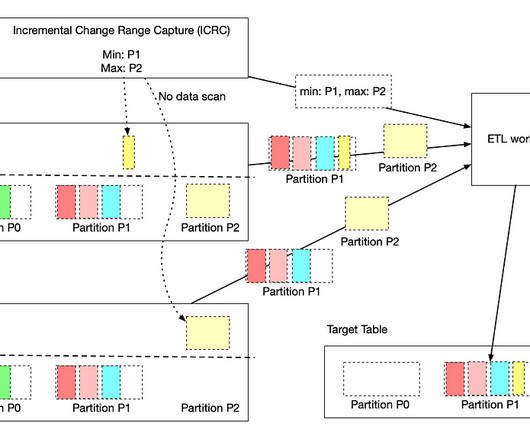
by Jun He , Yingyi Zhang , and Pawan Dixit Incremental processing is an approach to process new or changed data in workflows. The key advantage is that it only incrementally processesdata that are newly added or updated to a dataset, instead of re-processing the complete dataset.
When dealing with large-scale data, we turn to batch processing with distributed systems to complete high-volume jobs. In this blog, we explore the evolution of our in-house batch processing infrastructure and how it helps Robinhood work smarter. Why Batch Processing is Integral to Robinhood Why is batch processing important?
This belief has led us to developing Privacy Aware Infrastructure (PAI) , which offers efficient and reliable first-class privacy constructs embedded in Meta infrastructure to address different privacy requirements, such as purpose limitation , which restricts the purposes for which data can be processed and used.
Introduction Data pipelines play a critical role in the processing and management of data in modern organizations. A well-designed data pipeline can help organizations extract valuable insights from their data, automate tedious manual processes, and ensure the accuracy of dataprocessing.
Process all your data where it already lives Fragmented data environments and complex cloud architectures impede efficiency and innovation. However, relying only on structured data for these models can overlook valuable signals present in unstructured sources like images, which influence user engagement.
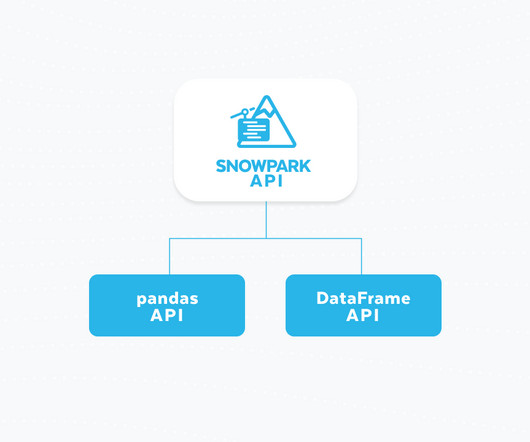
With Snowpark’s existing DataFrame API , users have access to a robust framework for lazily evaluated, relational operations on data, closely resembling Spark’s conventions. pandas is the go-to dataprocessing library for millions worldwide, including countless Snowflake users. Why introduce a distributed pandas API?
It is a famous Scala-coded dataprocessing tool that offers low latency, extensive throughput, and a unified platform to handle the data in real-time. Introduction Apache Kafka is an open-source publish-subscribe messaging application initially developed by LinkedIn in early 2011.
In this edition, we talk to Richard Meng, co-founder and CEO of ROE AI , a startup that empowers data teams to extract insights from unstructured, multimodal data including documents, images and web pages using familiar SQL queries. ROE AI solves unstructured data with zero embedding vectors. What inspires you as a founder?
Exponential Growth in AI-Driven Data Solutions This approach, known as data building, involves integrating AI-based processes into the services. As early as 2025, the integration of these processes will become increasingly significant. It lets you describe data more complexly and make predictions.
Why Future-Proofing Your Data Pipelines Matters Data has become the backbone of decision-making in businesses across the globe. The ability to harness and analyze data effectively can make or break a company’s competitive edge. Set Up Auto-Scaling: Configure auto-scaling for your dataprocessing and storage resources.
The Race For Data Quality In A Medallion Architecture The Medallion architecture pattern is gaining traction among data teams. It is a layered approach to managing and transforming data. By systematically moving data through these layers, the Medallion architecture enhances the data structure in a data lakehouse environment.
When they deploy Contextual AI as a Snowflake Native App , they get the peace of mind that comes with running the platform and the dataprocessing inside their own Snowflake environment, while Snowflake manages the infrastructure complexity, including server management, scaling and maintenance.
We identified this issue through firsthand experience, having worked for decades in food safety and quality management, where we consistently saw companies struggle with compliance and data transparency. Whats the coolest thing youre doing with data?
Here’s how Snowflake Cortex AI and Snowflake ML are accelerating the delivery of trusted AI solutions for the most critical generative AI applications: Natural language processing (NLP) for data pipelines: Large language models (LLMs) have a transformative potential, but they often batch inference integration into pipelines, which can be cumbersome.
But CTC was paying $800,000 a year just to move data from Snowflake to managed Spark for processing and back again. To overcome these hurdles, CTC moved its processing off of managed Spark and onto Snowflake, where it had already built its data foundation.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content