

Last Mile Data Processing with Ray
Pinterest Engineering
SEPTEMBER 12, 2023
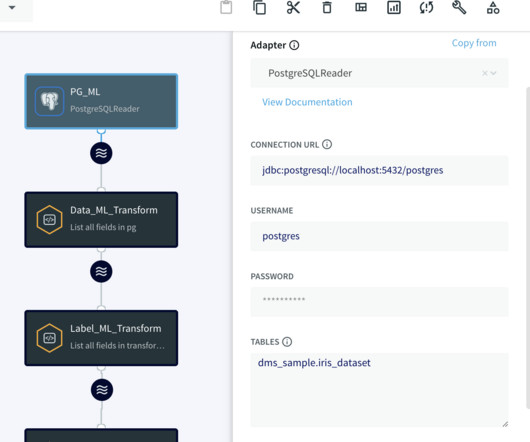
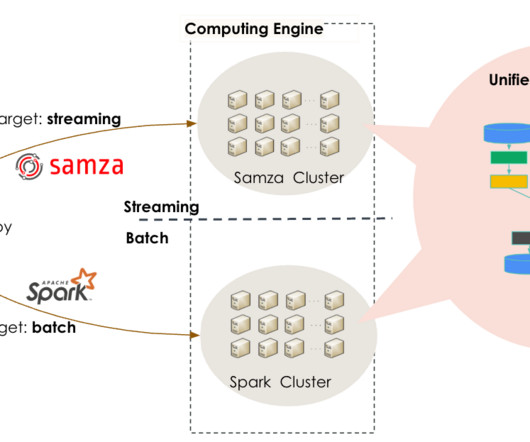
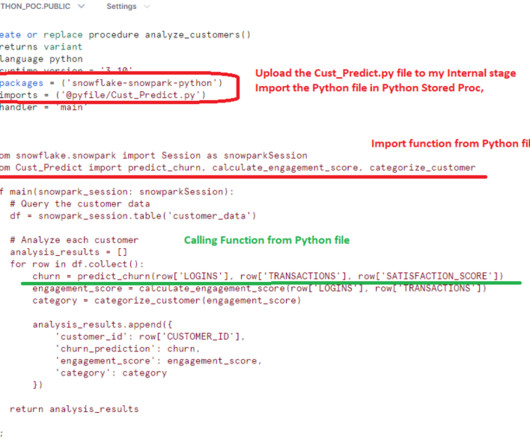
Behind the scenes, hundreds of ML engineers iteratively improve a wide range of recommendation engines that power Pinterest, processing petabytes of data and training thousands of models using hundreds of GPUs. In some cases, petabytes of data are streamed into training jobs to train a model.










































Let's personalize your content