This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Batch dataprocessing — historically known as ETL — is extremely challenging. In this post, we’ll explore how applying the functional programming paradigm to data engineering can bring a lot of clarity to the process. It’s time-consuming, brittle, and often unrewarding.
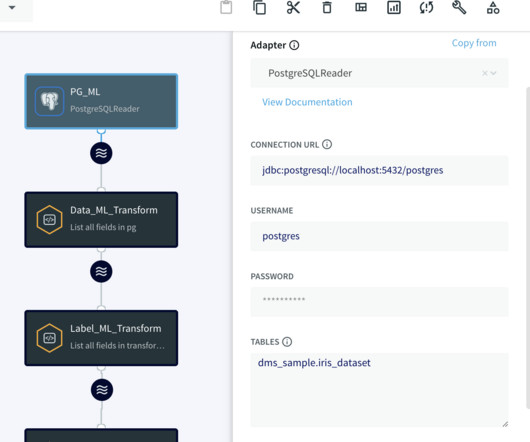
Data Management A tutorial on how to use VDK to perform batch dataprocessing Photo by Mika Baumeister on Unsplash Versatile Data Ki t (VDK) is an open-source data ingestion and processing framework designed to simplify data management complexities. The following figure shows a snapshot of VDK UI.
The Race For Data Quality In A Medallion Architecture The Medallion architecture pattern is gaining traction among data teams. It is a layered approach to managing and transforming data. By systematically moving data through these layers, the Medallion architecture enhances the data structure in a data lakehouse environment.
What is Data Transformation? Data transformation is the process of converting rawdata into a usable format to generate insights. It involves cleaning, normalizing, validating, and enriching data, ensuring that it is consistent and ready for analysis.
The result of these batch operations in the data warehouse is a set of comma delimited text files containing the unfiltered rawdata logs for each user. We do this by passing the rawdata through various renderers, discussed in more detail in the next section.
Over a decade after the inception of the Hadoop project, the amount of unstructured data available to modern applications continues to increase. Moreover, despite forecasts to the contrary, SQL remains the lingua franca of dataprocessing; today's NoSQL and Big Data infrastructure platform usage often involves some form of SQL-based querying.
Rawdata, however, is frequently disorganised, unstructured, and challenging to work with directly. Dataprocessing analysts can be useful in this situation. Let’s take a deep dive into the subject and look at what we’re about to study in this blog: Table of Contents What Is DataProcessing Analysis?
These scalable models can handle millions of records, enabling you to efficiently build high-performing NLP data pipelines. However, scaling LLM dataprocessing to millions of records can pose data transfer and orchestration challenges, easily addressed by the user-friendly SQL functions in Snowflake Cortex.
Real-time dataprocessing in the world of machine learning allows data scientists and engineers to focus on model development and monitoring. Striim’s strength lies in its capacity to connect to over 150 data sources, enabling real-time data acquisition from virtually any location and simplifying data transformations.
In the age of AI, enterprises are increasingly looking to extract value from their data at scale but often find it difficult to establish a scalable data engineering foundation that can process the large amounts of data required to build or improve models.
Think of it as the “slow and steady wins the race” approach to dataprocessing. Stream Processing Pattern Now, imagine if instead of waiting to do laundry once a week, you had a magical washing machine that could clean each piece of clothing the moment it got dirty. The data lakehouse has got you covered!
The data industry has a wide variety of approaches and philosophies for managing data: Inman data factory, Kimball methodology, s tar schema , or the data vault pattern, which can be a great way to store and organize rawdata, and more. Data mesh does not replace or require any of these.
On the dataprocessing side there is Polars, a DataFrame library that could replace pandas. How to land a job in progressive data — If you want to use your skills to Do Good you have to look at Brittany's post about progressive data. Let's have a quick look at it. seed round.
The open dataprocessing pipeline. IoT is expected to generate a volume and variety of data greatly exceeding what is being experienced today, requiring modernization of information infrastructure to realize value. The post Building an Open DataProcessing Pipeline for IoT appeared first on Cloudera Blog.
The year 2024 saw some enthralling changes in volume and variety of data across businesses worldwide. The surge in data generation is only going to continue. Foresighted enterprises are the ones who will be able to leverage this data for maximum profitability through dataprocessing and handling techniques.
Snowflake’s platform can power a variety of workloads all on top of Iceberg: data engineering, artificial intelligence (AI), machine learning (ML), business intelligence (BI) and more. Supporting Iceberg as a storage format for Dynamic Tables will simplify dataprocessing for data lakes and lakehouses.
Balancing the edge: Understanding the right balance between dataprocessing at the edge and in the cloud is a challenge, and this is why the entire data lifecycle needs to be considered. Data Collection Using Cloudera Data Platform. STEP 1: Collecting the rawdata.
In this context, managing the data, especially when it arrives late, can present a substantial challenge! In this three-part blog post series, we introduce you to Psyberg , our incremental dataprocessing framework designed to tackle such challenges! Rawdata for hours 3 and 6 arrive. Let’s dive in!
Ripple's Journey and Challenges with the Legacy System Our legacy system was once at the forefront of big dataprocessing, but as our operations grew, we faced a tangle of complexities. High maintenance costs and a system that struggled to meet the real-time demands of our data-driven initiatives.
Schedule data ingestion, processing, model training and insight generation to enhance efficiency and consistency in your dataprocesses. Access Snowflake platform capabilities and data sets directly within your notebooks.
Third-Party Data: External data sources that your company does not collect directly but integrates to enhance insights or support decision-making. These data sources serve as the starting point for the pipeline, providing the rawdata that will be ingested, processed, and analyzed.
Right now we’re focused on rawdata quality and accuracy because it’s an issue at every organization and so important for any kind of analytics or day-to-day business operation that relies on data — and it’s especially critical to the accuracy of AI solutions, even though it’s often overlooked.
Animesh Kundera, co-founder and CTO of The Modern Data Company, distills these ideas down to “the four horsemen of data debt.” Administrators can govern data access through attribute-based controls, and IT users can get behind the scenes to build the apps and tools the company needs for big dataprocessing.
Figure 3: An expanded metric detail view showing historical trend and dimensional breakdown (note all data is mocked) Finally, we link to a dedicated dashboard for each metric with further slicing and dicing capabilities, and access to the individual data points. rawdata path, column mappings, aggregation function to be used, etc.)
This platform afforded more scalability and agility for Bank Mandiri to ramp up their daily dataprocessing to 10 million records each day while shortening the time to processdata from 7 days to just hours. million) of transactions per week at each of the bank’s branches.
VDK helps you easily perform complex operations, such as data ingestion and processing from different sources, using SQL or Python. You can use VDK to build data lakes and ingest rawdata extracted from different sources, including structured, semi-structured, and unstructured data.
Businesses benefit at large with these data collection and analysis as they allow organizations to make predictions and give insights about products so that they can make informed decisions, backed by inferences from existing data, which, in turn, helps in huge profit returns to such businesses. What is the role of a Data Engineer?
In other words, it acted as an input data source, taking much of the work on dataprocessing and transferring within Power BI. Power Query will automatically execute Query Folding under the following conditions: A data source is an object that can process query requests, just like a database used in most cases.
Data science uses machine learning algorithms like Random Forests, K-nearest Neighbors, Naive Bayes, Regression Models, etc. They can categorize and cluster rawdata using algorithms, spot hidden patterns and connections in it, and continually learn and improve over time. These large data sets are referred to as "Big Data."
In today’s data-driven world, businesses collect and store vast amounts of data from various sources. However, rawdata is often unstructured, inconsistent, and may not be immediately usable for analysis or decision-making. That’s where data transformation comes into play.
Integration Layer : Where your data transformations and business logic are applied. Stage Layer: The Foundation The Stage Layer serves as the foundation of a data warehouse. Its primary purpose is to ingest and store rawdata with minimal modifications, preserving the original format and content of incoming data.
A data engineer is an engineer who creates solutions from rawdata. A data engineer develops, constructs, tests, and maintains data architectures. Let’s review some of the big picture concepts as well finer details about being a data engineer. Earlier we mentioned ETL or extract, transform, load.
Keep the table of columns where the data is being aggregated to a minimum. Use proactive caching and computation groups to avoid time-consuming dataprocessing. Employing suitable data modeling will help you process less data. Still have questions?
7 Data Pipeline Examples: ETL, Data Science, eCommerce, and More Joseph Arnold July 6, 2023 What Are Data Pipelines? Data pipelines are a series of dataprocessing steps that enable the flow and transformation of rawdata into valuable insights for businesses.
In today’s data-driven era, you have more rawdata than ever before. However, to leverage the power of big data, you need to convert rawdata into valuable insights for informed decision-making. ” While they may sound […]
L1 is usually the raw, unprocessed data ingested directly from various sources; L2 is an intermediate layer featuring data that has undergone some form of transformation or cleaning; and L3 contains highly processed, optimized, and typically ready for analytics and decision-making processes.
The emergence of cloud data warehouses, offering scalable and cost-effective data storage and processing capabilities, initiated a pivotal shift in data management methodologies. How ELT Works The process of ELT can be broken down into the following three stages: 1. What Is ELT? So, what exactly is ELT?
An AdTech company in the US provides processing, payment, and analytics services for digital advertisers. Dataprocessing and analytics drive their entire business. But an important caveat is that ingest speed, semantic richness for developers, data freshness, and query latency are paramount. General Purpose RTDW.
It enables displaying characteristics of audio files, creating all types of audio data visualizations and extracting features from them, to name just a few capabilities. Audio Toolbox by MathWorks offers numerous instruments for audio dataprocessing and analysis, from labeling to estimating signal metrics to extracting certain features.
DataOps uses a wide range of technologies such as machine learning, artificial intelligence, and various data management tools to streamline dataprocessing, testing, preparing, deploying, and monitoring. This results in a system that gives organizations control over the data flow so that anomalies can be spotted automatically.
Imagine you’re tasked with managing a critical data pipeline in Snowflake that processes and transforms large datasets. This pipeline consists of several sequential tasks: Task A: Loads rawdata into a staging table. Task B: Transforms the data in the staging table.
Transforming Data Complexity into Strategic Insight At first glance, the process of transforming rawdata into actionable insights can seem daunting. The journey from data collection to insight generation often feels like operating a complex machine shrouded in mystery and uncertainty.
® , Go, and Python SDKs where an application can use SQL to query rawdata coming from Kafka through an API (but that is a topic for another blog). Apache Kafka is an event streaming platform that combines messages, storage, and dataprocessing. Apache Kafka as an event streaming platform for real-time analytics.
Data engineering design patterns are repeatable solutions that help you structure, optimize, and scale dataprocessing, storage, and movement. They make data workflows more resilient and easier to manage when things inevitably go sideways. Thats why solid design patterns matter. Which One Should You Choose?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content