This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Most organizations find it challenging to manage data from diverse sources efficiently. Amazon Web Services (AWS) enables you to address this challenge with Amazon RDS, a scalable relationaldatabase service for Microsoft SQL Server (MS SQL). However, simply storing the data isn’t enough.
Business transactions captured in relationaldatabases are critical to understanding the state of business operations. Since the value of data quickly drops over time, organizations need a way to analyze data as it is generated. The final step of ETL involves loading data into the target destination.
Hadoop and Spark are the two most popular platforms for Big Dataprocessing. They both enable you to deal with huge collections of data no matter its format — from Excel tables to user feedback on websites to images and video files. Obviously, Big Dataprocessing involves hundreds of computing units.
PySpark SQL and Dataframes A dataframe is a shared collection of organized or semi-structured data in PySpark. This collection of data is kept in Dataframe in rows with named columns, similar to relationaldatabase tables. With PySparkSQL, we can also use SQL queries to perform data extraction.
Introduction Data Engineer is responsible for managing the flow of data to be used to make better business decisions. A solid understanding of relationaldatabases and SQL language is a must-have skill, as an ability to manipulate large amounts of data effectively.
With the collective power of the open-source community, Open Table Formats remain at the cutting edge of data architecture, evolving to support emerging trends and addressing the limitations of previous systems. Amazon S3, Azure Data Lake, or Google Cloud Storage).
Summary At the foundational layer many databases and dataprocessing engines rely on key/value storage for managing the layout of information on the disk. As these systems are scaled to larger volumes of data and higher throughputs the RocksDB engine can become a bottleneck for performance.
Big data is a term that refers to the massive volume of data that organizations generate every day. In the past, this data was too large and complex for traditional dataprocessing tools to handle. There are a variety of big dataprocessing technologies available, including Apache Hadoop, Apache Spark, and MongoDB.
Using SQL to run your search might be enough for your use case, but as your project requirements grow and more advanced features are needed—for example, enabling synonyms, multilingual search, or even machine learning—your relationaldatabase might not be enough. relationaldatabases) and storing them in an intermediate broker.
NoSQL Databases NoSQL databases are non-relationaldatabases (that do not store data in rows or columns) more effective than conventional relationaldatabases (databases that store information in a tabular format) in handling unstructured and semi-structured data.
Big Data NoSQL databases were pioneered by top internet companies like Amazon, Google, LinkedIn and Facebook to overcome the drawbacks of RDBMS. RDBMS is not always the best solution for all situations as it cannot meet the increasing growth of unstructured data. professionals often debate the merits of SQL vs. .”-said
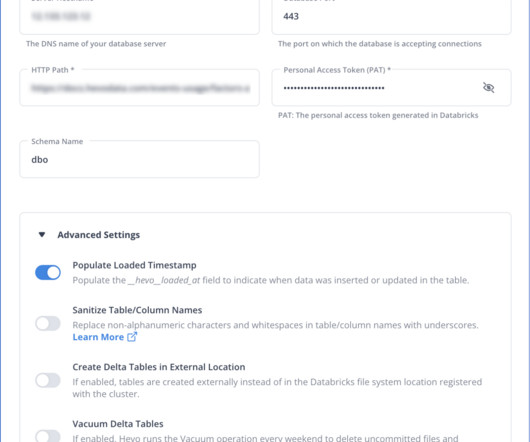
Amazon RDS, with its support for the PostgreSQL database, is a popular choice for businesses looking for reliable relationaldatabase services. However, the increasing need for advanced analytics and large-scale dataprocessing requires migrating data to more efficient platforms like Databricks.
Integrating MySQL on Amazon RDS to Azure Synapse can offer a seamless data pipeline, enabling you to leverage the strengths of both for enhanced dataprocessing and analytics. Amazon RDS offers a fully-managed and scalable relationaldatabase service, providing seamless deployment.
In the modern data-driven business landscape, extracting actionable insights from available data helps improve performance and growth. Amazon RDS (RelationalDatabase Service) is a popular choice for a fully-managed cloud environment to manage MySQL databases. Let’s look […]
What’s forgotten is that the rise of this paradigm was driven by a particular type of human-facing application in which a user looks at a UI and initiates actions that are translated into database queries. Our goal at Confluent is to help make this happen. Jay Kreps is the CEO of Confluent as well as one of the co-creators of Apache Kafka.
Furthermore, Striim also supports real-time data replication and real-time analytics, which are both crucial for your organization to maintain up-to-date insights. By efficiently handling data ingestion, this component sets the stage for effective dataprocessing and analysis. Are we using all the data or just a subset?
It also has strong querying capabilities, including a large number of operators and indexes that allow for quick data retrieval and analysis. Database Software- Other NoSQL: NoSQL databases cover a variety of database software that differs from typical relationaldatabases. Columnar Database (e.g.-
An AdTech company in the US provides processing, payment, and analytics services for digital advertisers. Dataprocessing and analytics drive their entire business. But an important caveat is that ingest speed, semantic richness for developers, data freshness, and query latency are paramount. General Purpose RTDW.
What are the Different Types of Database Implementations? RelationalDatabases A relationaldatabase organizes data into tables that contain links between data elements that define their relationships. This allows quick access to information based on the connections between data elements.
This involves connecting to multiple data sources, using extract, transform, load ( ETL ) processes to standardize the data, and using orchestration tools to manage the flow of data so that it’s continuously and reliably imported – and readily available for analysis and decision-making.
SQL Structured Query Language, or SQL, is used to manage and work with relationaldatabases. It is a crucial tool for data scientists since it enables users to create, retrieve, edit, and delete data from databases.SQL (Structured Query Language) is indispensable when it comes to handling structured data stored in relationaldatabases.
Based on the needs of your application, Azure SQL Databases can be deployed using various methods. In this article, I will cover the various aspects of Azure SQL Database. What is Azure SQL Database? It is compatible with spatial, JSON, XML, and relationaldata structures. Let's get right to it.
AWS Glue is a widely-used serverless data integration service that uses automated extract, transform, and load ( ETL ) methods to prepare data for analysis. It offers a simple and efficient solution for dataprocessing in organizations. where it can be used to facilitate business decisions. You can use Glue's G.1X
And most of this data has to be handled in real-time or near real-time. Variety is the vector showing the diversity of Big Data. This data isn’t just about structured data that resides within relationaldatabases as rows and columns. For that purpose, different dataprocessing options exist.
While AWS RDS Oracle offers a robust relationaldatabase solution over the cloud, Databricks simplifies big dataprocessing with features such as automated scheduling and optimized Spark clusters.
It allows businesses to construct event-driven architectures and microservices in which functions are invoked by events like file uploads, database changes, or HTTP requests. Lambda usage includes real-time dataprocessing, communication with IoT devices, and execution of automated tasks.
Supports numerous data sources It connects to and fetches data from a variety of data sources using Tableau and supports a wide range of data sources, including local files, spreadsheets, relational and non-relationaldatabases, data warehouses, big data, and on-cloud data.
The major difference between Sqoop and Flume is that Sqoop is used for loading data from relationaldatabases into HDFS while Flume is used to capture a stream of moving data. Table of Contents Hadoop ETL tools: Sqoop vs Flume-Comparison of the two Best Data Ingestion Tools What is Sqoop in Hadoop?
The future of SQL (Structured Query Language) is a scalding subject among professionals in the data-driven world. As data generation continues to skyrocket, the demand for real-time decision-making, dataprocessing, and analysis increases. According to recent studies, the global database market will grow from USD 63.4
Using Snowball helps users access large-scale data transmissions and cut down on network costs, long transfer times, and security concerns. Database Amazon RelationalDatabase Service (RDS) Amazon RelationalDatabase Service (RDS) is easy to establish and run on a relationaldatabase in the cloud.
Big Data is a collection of large and complex semi-structured and unstructured data sets that have the potential to deliver actionable insights using traditional data management tools. Big data operations require specialized tools and techniques since a relationaldatabase cannot manage such a large amount of data.
This feature eliminates code to parse data, lowers our technical debt, and shortens our development time. A Unified View for Operational Data We kept most of our operational data in relationaldatabases, like MySQL. Fig 2: An overview of BigQuery’s disaggregation of storage, memory, and compute[13].
Most scenarios require a reliable, scalable, and secure end-to-end integration that enables bidirectional communication and dataprocessing in real time. Confluent Platform and Confluent Cloud are already used in many IoT deployments, both in Consumer IoT and Industrial IoT (IIoT).
Challenges of Legacy Data Architectures Some of the main challenges associated with legacy data architectures include: Lack of flexibility: Traditional data architectures are often rigid and inflexible, making it difficult to adapt to changing business needs and incorporate new data sources or technologies.
These fundamentals will give you a solid foundation in data and datasets. Knowing SQL means you are familiar with the different relationaldatabases available, their functions, and the syntax they use. Have knowledge of regular expressions (RegEx) It is essential to be able to use regular expressions to manipulate data.
BI (Business Intelligence) Strategies and systems used by enterprises to conduct data analysis and make pertinent business decisions. Big Data Large volumes of structured or unstructured data. Big Query Google’s cloud data warehouse. Cassandra A database built by the Apache Foundation.
This comes with the advantages of reduction of redundancy, data integrity and consequently, less storage usage. Photo by Shubham Dhage on Unsplash While data normalization holds merit in traditional relationaldatabases, the paradigm shifts when dealing with modern analytics platforms like BigQuery.
It is designed to support business intelligence (BI) and reporting activities, providing a consolidated and consistent view of enterprise data. Data warehouses are typically built using traditional relationaldatabase systems, employing techniques like Extract, Transform, Load (ETL) to integrate and organize data.
NoSQL This database management system has been designed in a way that it can store and handle huge amounts of semi-structured or unstructured data. HBase Overview : HBase is a Java-based, non-relational, column-oriented, NoSQL distributed database management system that works on top of HDFS.
The data source is the location of the data that the processing will consume for dataprocessing functions. This can be the point of origin of the data, the place of its creation. Alternatively, this can be data generated by another process and then made available for subsequent processing.
They are also accountable for communicating data trends. Let us now look at the three major roles of data engineers. Generalists They are typically responsible for every step of the dataprocessing, starting from managing and making analysis and are usually part of small data-focused teams or small companies.
Understanding SQL You must be able to write and optimize SQL queries because you will be dealing with enormous datasets as an Azure Data Engineer. To be an Azure Data Engineer, you must have a working knowledge of SQL (Structured Query Language), which is used to extract and manipulate data from relationaldatabases.
With this module, you’ll be able to: Leverage capabilities from across our data portfolio – meaning access to solutions you already know and rely on in a SaaS-based design infrastructure. Design in the cloud, deploy anywhere – with an array of deployment options for complex dataprocesses. Bigger, better results.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content