This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It is a famous Scala-coded dataprocessing tool that offers low latency, extensive throughput, and a unified platform to handle the data in real-time. Introduction Apache Kafka is an open-source publish-subscribe messaging application initially developed by LinkedIn in early 2011.
It often requires a long process that touches many languages and frameworks. ML engineers have to write new jobs in scala / PySpark and test them. This is not an interactive process, and often bugs are not found until later. This is what we commonly refer to as Last Mile DataProcessing.
The term Scala originated from “Scalable language” and it means that Scala grows with you. In recent times, Scala has attracted developers because it has enabled them to deliver things faster with fewer codes. Developers are now much more interested in having Scala training to excel in the big data field.
In the age of AI, enterprises are increasingly looking to extract value from their data at scale but often find it difficult to establish a scalable data engineering foundation that can process the large amounts of data required to build or improve models. The tool serves two primary functions: assessment and conversion.
Apache Spark is one of the hottest and largest open source project in dataprocessing framework with rich high-level APIs for the programming languages like Scala, Python, Java and R. It realizes the potential of bringing together both Big Data and machine learning.
Obviously not all tools are made with the same use case in mind, so we are planning to add more code samples for other (than classical batch ETL) dataprocessing purposes, e.g. Machine Learning model building and scoring. A large number of our data users employ SparkSQL, pyspark, and Scala. scala-workflow ? ???
The thought of learning Scala fills many with fear, its very name often causes feelings of terror. The truth is Scala can be used for many things; from a simple web application to complex ML (Machine Learning). The name Scala stands for “scalable language.” So what companies are actually using Scala?
This article is all about choosing the right Scala course for your journey. How should I get started with Scala? Do you have any tips to learn Scala quickly? How to Learn Scala as a Beginner Scala is not necessarily aimed at first-time programmers. Which course should I take?
If you search top and highly effective programming languages for Big Data on Google, you will find the following top 4 programming languages: Java Scala Python R Java Java is one of the oldest languages of all 4 programming languages listed here. Scala is a highly Scalable Language. Scala is the native language of Spark.
“Big data Analytics” is a phrase that was coined to refer to amounts of datasets that are so large traditional dataprocessing software simply can’t manage them. For example, big data is used to pick out trends in economics, and those trends and patterns are used to predict what will happen in the future.
Most cutting-edge technology organizations like Netflix, Apple, Facebook, and Uber have massive Spark clusters for dataprocessing and analytics. Also, there is no interactive mode available in MapReduce Spark has APIs in Scala, Java, Python, and R for all basic transformations and actions.
It has in-memory computing capabilities to deliver speed, a generalized execution model to support various applications, and Java, Scala, Python, and R APIs. Spark Streaming enhances the core engine of Apache Spark by providing near-real-time processing capabilities, which are essential for developing streaming analytics applications.
Previous posts have looked at Algebraic Data Types with Java Variance, Phantom and Existential types in Java and Scala Intersection and Union Types with Java and Scala In this post we will combine some ideas from functional programming with strong typing to produce robust expressive code that is more reusable. n" , Thread.
Spark offers over 80 high-level operators that make it easy to build parallel apps and one can use it interactively from the Scala, Python, R, and SQL shells. Cluster Computing: Efficient processing of data on Set of computers (Refer commodity hardware here) or distributed systems.
7 Kafka stores data in Topic i.e., in a buffer memory. Spark uses RDD to store data in a distributed manner (i.e., cache, local space) 8 It supports multiple languages such as Java, Scala, R, and Python. RDDs can include any kind of Python, Java, or Scala object, including classes that the user has specified. Dataflow 4.
In addition, AI data engineers should be familiar with programming languages such as Python , Java, Scala, and more for data pipeline, data lineage, and AI model development.
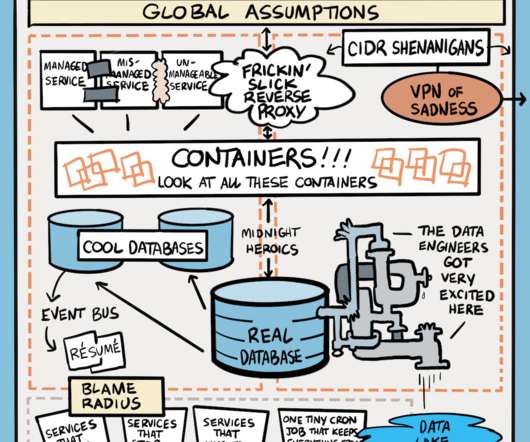
Either they have to build rigid architecture for the highest maximum data surge, or build a system that is elastic and scalable. The business’s dilemma is balancing the need for high-performance dataprocessing with the associated compute costs. Organizational Access. A rare breed.
PySpark is used to process real-time data with Kafka and Streaming, and this exhibits low latency. Multi-Language Support PySpark platform is compatible with various programming languages, including Scala, Java, Python, and R. Because of its interoperability, it is the best framework for processing large datasets.
Enjoy the Data News. Polars—Pandas are freezing Recently influencers are betting that Rust will be the de-facto language in data engineering. The history repeat, we've seen it with Scala, Go or even Julia at some scale. On the dataprocessing side there is Polars, a DataFrame library that could replace pandas.
Figure 2: Questions answered by precision medicine Snowflake and FAIR in the world of precision medicine and biomedical research Cloud-based big data technologies are not new for large-scale dataprocessing. A conceptual architecture illustrating this is shown in Figure 3.
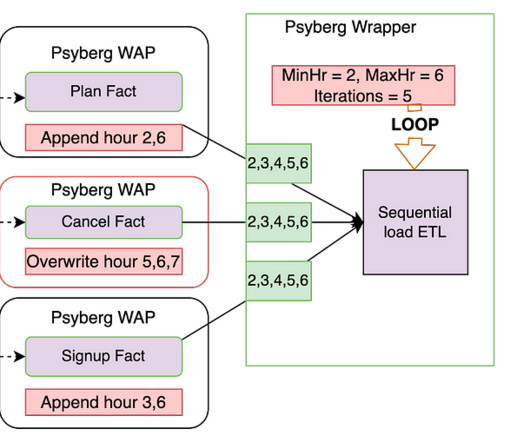
In the previous installments of this series, we introduced Psyberg and delved into its core operational modes: Stateless and Stateful DataProcessing. Pipelines After Psyberg Let’s explore how different modes of Psyberg could help with a multistep data pipeline. This is compatible with both Python and Scala Spark.
The open dataprocessing pipeline. IoT is expected to generate a volume and variety of data greatly exceeding what is being experienced today, requiring modernization of information infrastructure to realize value. The post Building an Open DataProcessing Pipeline for IoT appeared first on Cloudera Blog.
Summary A majority of the scalable dataprocessing platforms that we rely on are built as distributed systems. Kyle Kingsbury created the Jepsen framework for testing the guarantees of distributed dataprocessing systems and identifying when and why they break.
AWS Glue is a widely-used serverless data integration service that uses automated extract, transform, and load ( ETL ) methods to prepare data for analysis. It offers a simple and efficient solution for dataprocessing in organizations. where it can be used to facilitate business decisions. You can use Glue's G.1X
It provides high-level APIs in Java, Scala, Python, and R and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools, including Spark SQL for SQL and structured dataprocessing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming.
Snowpark is the set of libraries and runtimes that enables data engineers, data scientists and developers to build data engineering pipelines, ML workflows, and data applications in Python, Java, and Scala. Now users with USAGE privilege on the CHATGPT function can call this UDF.
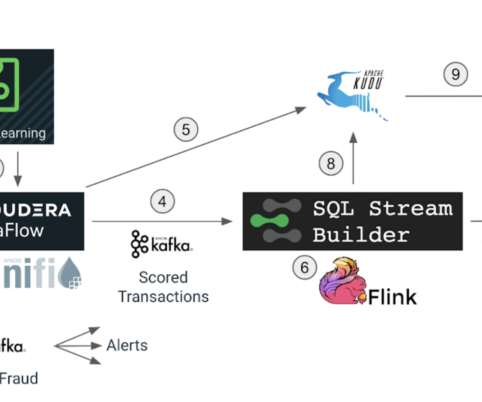
In this blog we will explore how we can use Apache Flink to get insights from data at a lightning-fast speed, and we will use Cloudera SQL Stream Builder GUI to easily create streaming jobs using only SQL language (no Java/Scala coding required). Flink is a “streaming first” modern distributed system for dataprocessing.
Big data is a term that refers to the massive volume of data that organizations generate every day. In the past, this data was too large and complex for traditional dataprocessing tools to handle. There are a variety of big dataprocessing technologies available, including Apache Hadoop, Apache Spark, and MongoDB.
In this article, we’ll explore what Snowflake Snowpark is, the unique functionalities it brings to the table, why it is a game-changer for developers, and how to leverage its capabilities for more streamlined and efficient dataprocessing. What Is Snowflake Snowpark?
0 — Quick Review Quickly, let’s review what spark does… Spark is a big dataprocessing engine. It takes python/java/scala/R/SQL and converts that code into a highly optimized set of transformations. At it’s lowest level, spark creates tasks, which are parallelizable transformations on data partitions. Let’s dive in!
Parallel computation: Optimal use of parallel hardware to execute computation quickly Division into subproblems Mainly concerns about: Speed Mainly used for: Algorithmic problems, numeric computation, Big Dataprocessing Concurrent programming: May or may not offer multiple execution starts at the same time Mainly concerns about: Convenience, better (..)
Apache Spark is the most efficient, scalable, and widely used in-memory data computation tool capable of performing batch-mode, real-time, and analytics operations. The next evolutionary shift in the dataprocessing environment will be brought about by Spark due to its exceptional batch and streaming capabilities.
Source: The Data Team’s Guide to the Databricks Lakehouse Platform Integrating with Apache Spark and other analytics engines, Delta Lake supports both batch and stream dataprocessing. Besides that, it’s fully compatible with various data ingestion and ETL tools. Databricks two-plane infrastructure.
It is recommended to take part in a data science bootcamp and get a hands-on approach to building data science projects with Java. Importance of Java for Data Science: When it comes to data science, Java delivers a host of data science methods such as dataprocessing, data analysis, data visualization statistical analysis, and NLP.
It can be used for web scraping, machine learning, and natural language processing. Java Java, a general-purpose language, has found a niche in big data analytics. Libraries like Hadoop and Apache Flink, written in Java, are extensively used for dataprocessing in distributed computing environments.
Keep reading to know more about the data science coding languages. ScalaScala has become one of the most popular languages for AI and data science use cases. In addition, Scala has many features that make it an attractive choice for data scientists, including functional programming, concurrency, and high performance.
Hadoop and Spark are the two most popular platforms for Big Dataprocessing. They both enable you to deal with huge collections of data no matter its format — from Excel tables to user feedback on websites to images and video files. Obviously, Big Dataprocessing involves hundreds of computing units.
Oracle University designed this course for database administrators who want to validate their skills with developing performance, blending business processes, and accomplishing dataprocessing work. Big Data is the term used to describe enormous volumes of data.
You ought to be able to create a data model that is performance- and scalability-optimized. Programming and Scripting Skills Building dataprocessing pipelines requires knowledge of and experience with coding in programming languages like Python, Scala, or Java. The certification cost is $165 USD.
As per Apache, “ Apache Spark is a unified analytics engine for large-scale dataprocessing ” Spark is a cluster computing framework, somewhat similar to MapReduce but has a lot more capabilities, features, speed and provides APIs for developers in many languages like Scala, Python, Java and R.
Hands-on experience with a wide range of data-related technologies The daily tasks and duties of a data architect include close coordination with data engineers and data scientists. The candidates for this certification should be able to transform, integrate and consolidate both structured and unstructured data.
But instead of the spoon, there's Scala. Let me deconstruct this workshop title for you: The “type level” part is implying that it’s concerned with operating on the types of values used by computations of your Scala programs, in opposition to the regular value level meaning.
Here are some essential skills for data engineers when working with data engineering tools. Strong programming skills: Data engineers should have a good grasp of programming languages like Python, Java, or Scala, which are commonly used in data engineering.
It provides high-level APIs in Java, Scala, Python, and R and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools, including Spark SQL for SQL and structured dataprocessing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content