This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Batch dataprocessing — historically known as ETL — is extremely challenging. In this post, we’ll explore how applying the functional programming paradigm to data engineering can bring a lot of clarity to the process. It’s time-consuming, brittle, and often unrewarding.
Introduction Setup SQL tips 1. Handy functions for common dataprocessing scenarios 1.1. STRUCT data types are sorted based on their keys from left to right 1.4. Need to filter on WINDOW function without CTE/Subquery use QUALIFY 1.2. Need the first/last row in a partition, use DISTINCT ON 1.3.
Summary Dataprocessing technologies have dramatically improved in their sophistication and raw throughput. Unfortunately, the volumes of data that are being generated continue to double, requiring further advancements in the platform capabilities to keep up.
In this edition, we talk to Richard Meng, co-founder and CEO of ROE AI , a startup that empowers data teams to extract insights from unstructured, multimodal data including documents, images and web pages using familiar SQL queries. Whats the coolest thing youre doing with data? What inspires you as a founder?
These scalable models can handle millions of records, enabling you to efficiently build high-performing NLP data pipelines. However, scaling LLM dataprocessing to millions of records can pose data transfer and orchestration challenges, easily addressed by the user-friendly SQL functions in Snowflake Cortex.
Data Management A tutorial on how to use VDK to perform batch dataprocessing Photo by Mika Baumeister on Unsplash Versatile Data Ki t (VDK) is an open-source data ingestion and processing framework designed to simplify data management complexities.
These stages propagate through various systems including function-based systems that load, process, and propagate data through stacks of function calls in different programming languages (e.g., For simplicity, we will demonstrate these for the web, the data warehouse, and AI, per the diagram below. Hack, C++, Python, etc.)
Using nested data types effectively 3.1. Using nested data types in dataprocessing 3.3.1. STRUCT enables more straightforward data schema and data access 3.3.2. Nested data types can be sorted 3.3.3. Use STRUCT for one-to-one & hierarchical relationships 3.2.
Atlan is a collaborative workspace for data-driven teams, like Github for engineering or Figma for design teams. What are the techniques/technologies that teams might use to optimize or scale out their dataprocessing workflows? Can you describe what Bodo is and the story behind it?
The typical pharmaceutical organization faces many challenges which slow down the data team: Raw, barely integrated data sets require engineers to perform manual , repetitive, error-prone work to create analyst-ready data sets. Cloud computing has made it much easier to integrate data sets, but that’s only the beginning.
Atlan is a collaborative workspace for data-driven teams, like Github for engineering or Figma for design teams. Atlan is a collaborative workspace for data-driven teams, like Github for engineering or Figma for design teams. Can you describe what Fugue is and the story behind it?
Event-driven and streaming architectures enable complex processing on market events as they happen, making them a natural fit for financial market applications. Flink SQL is a dataprocessing language that enables rapid prototyping and development of event-driven and streaming applications. You can view the code here.
It employs Snowpark Container Services to build scalable AI/ML models for satellite dataprocessing and Snowflake AI/ML functions to enable advanced analytics and predictive insights for satellite operators. Sherloq aims to change this by offering a collaborative platform for managing and documenting data analytics workflows.
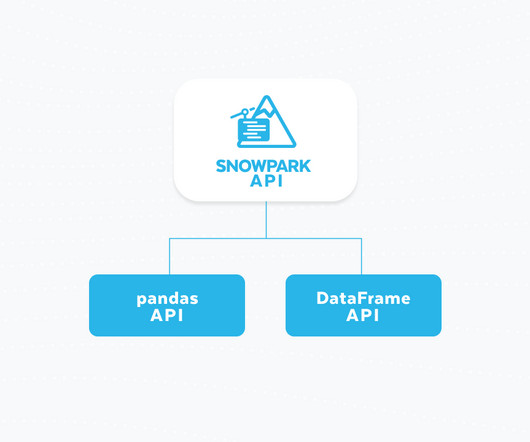
With Snowpark’s existing DataFrame API , users have access to a robust framework for lazily evaluated, relational operations on data, closely resembling Spark’s conventions. pandas is the go-to dataprocessing library for millions worldwide, including countless Snowflake users. Why introduce a distributed pandas API?
Fluss is a compelling new project in the realm of real-time dataprocessing. I spoke with Jark Wu , who leads the Fluss and Flink SQL team at Alibaba Cloud, to understand its origins and potential. Among the 20,000 Flink SQL jobs at Alibaba, only 49% of columns of Kafka data are read on average.
Atlan is a collaborative workspace for data-driven teams, like Github for engineering or Figma for design teams. Atlan is a collaborative workspace for data-driven teams, like Github for engineering or Figma for design teams.
To access real-time data, organizations are turning to stream processing. There are two main dataprocessing paradigms: batch processing and stream processing. Your electric consumption is collected during a month and then processed and billed at the end of that period.
link] QuantumBlack: Solving data quality for gen AI applications Unstructured dataprocessing is a top priority for enterprises that want to harness the power of GenAI. It brings challenges in dataprocessing and quality, but what data quality means in unstructured data is a top question for every organization.
Snowflake offers a secure, streamlined approach to developing across data workloads, reducing costs and reliance on external tools. This means faster development and happier data teams. Explore and experiment with data, visualize results, share insights — all in one place. Let’s dive deeper into what we announced.
It’s not a must for data scientist to have skill in data engineering before they can analyze dataprocessed by data engineer or before they can move uniformly with other group (involving data engineer) for the progress of the company. Data scientists should acquire some basic SQL functionality.
Snowflake Notebooks aim to provide a convenient, easy-to-use interactive environment that seamlessly blends Python, SQL and Markdown, as well as integrations with key Snowflake offerings, like Snowpark ML, Streamlit, Cortex and Iceberg tables. Discover valuable business insights through exploratory data analysis.
Most organizations find it challenging to manage data from diverse sources efficiently. Amazon Web Services (AWS) enables you to address this challenge with Amazon RDS, a scalable relational database service for Microsoft SQL Server (MS SQL). However, simply storing the data isn’t enough.
In addition to log files, sensors, and messaging systems, Striim continuously ingests real-time data from cloud-based or on-premises data warehouses and databases such as Oracle, Oracle Exadata, Teradata, Netezza, Amazon Redshift, SQL Server, HPE NonStop, MongoDB, and MySQL.
Introduction Data engineering is the field of study that deals with the design, construction, deployment, and maintenance of dataprocessing systems. The goal of this domain is to collect, store, and processdata efficiently and efficiently so that it can be used to support business decisions and power data-driven applications.
To add this metric to DJ, they need to provide two pieces of information: The fact table that the metric comesfrom: SELECT account_id, country_iso_code, streaming_hours FROM streaming_fact_table The metric expression: `SUM(streaming_hours)` Then metric consumers throughout the organization can call DJ to request either the SQL or the resulting data.
“Big data Analytics” is a phrase that was coined to refer to amounts of datasets that are so large traditional dataprocessing software simply can’t manage them. For example, big data is used to pick out trends in economics, and those trends and patterns are used to predict what will happen in the future.
Should that be the case, Azure SQL Database might be your best bet. Microsoft SQL Server's functionalities are fully included in Azure SQL Database, a cloud-based database service that also offers greater flexibility and scalability. In this article, I will cover the various aspects of Azure SQL Database.
To achieve this, we’re integrating AI into various aspects of our product, such as natural language data queries, text-to-SQL, and chart suggestions. Focusing on the text-to-SQL use case specifically, GPT-4 is exceptional at writing code and highly proficient in SQL. However, to perform optimally, GPT requires context.
Change Data Capture (CDC) has emerged as an ideal solution for near real-time movement of data from relational databases (like SQL Server or Oracle) to data warehouses, data lakes or other databases. The final step of ETL involves loading data into the target destination.
Summary Real-time dataprocessing has steadily been gaining adoption due to advances in the accessibility of the technologies involved. To bring streaming data in reach of application engineers Matteo Pelati helped to create Dozer. Use SQL, Python, R, no-code and AI to find and share insights across your organization.
Snowflake’s latest ML announcements Develop interactively with SQL and Python in Snowflake Notebooks Snowflake Notebooks, in private preview, is a new development interface that offers an interactive, cell-based programming environment for Python and SQL users to explore, process and experiment with data in Snowpark.
Why Future-Proofing Your Data Pipelines Matters Data has become the backbone of decision-making in businesses across the globe. The ability to harness and analyze data effectively can make or break a company’s competitive edge. Set Up Auto-Scaling: Configure auto-scaling for your dataprocessing and storage resources.
link] Gradient Flow: Paradigm Shifts in DataProcessing for the Generative AI Era dataprocessing pipelines haven't kept pace with the rapid advancement of AI models The article highlights the growing importance of preprocessing data pipelines, but the pipeline processing techniques do not match the demand.
In the age of AI, enterprises are increasingly looking to extract value from their data at scale but often find it difficult to establish a scalable data engineering foundation that can process the large amounts of data required to build or improve models.
Define a Sundeck SQL post-hook that examines current load and time of day to suspend idle warehouses. Implement a Sundeck SQL post-hook that collects query activity and records that in a Snowflake table, which is then consulted in a SQL pre-hook to reject excessive consumers (unless a manager overrides).
Obviously not all tools are made with the same use case in mind, so we are planning to add more code samples for other (than classical batch ETL) dataprocessing purposes, e.g. Machine Learning model building and scoring. See below example of hooking the table creation SQL file into the main workflow definition. -
Iceberg is a high-performance open table format for huge analytic data sets. It allows multiple dataprocessing engines, such as Flink, NiFi, Spark, Hive, and Impala to access and analyze data in simple, familiar SQL tables. This enables you to maximize utilization of streaming data at scale.
The Critical Role of AI Data Engineers in a Data-Driven World How does a chatbot seamlessly interpret your questions? The answer lies in unstructured dataprocessing—a field that powers modern artificial intelligence (AI) systems. How does a self-driving car understand a chaotic street scene?
Behind the scenes, Snowpark ML parallelizes dataprocessing operations by taking advantage of Snowflake’s scalable computing platform. This is a first-class, schema-level Snowflake object that provides a versioned container of ML model artifacts with full role-based access control (RBAC) support, and APIs for Python and SQL.
For instance a small team of 2 analytics engineers will pay now $2400/year just to have a server running their SQL queries and a web IDE that is yet to perfect. Query your data in Kafka using SQL — This is a post that compares Flink, ksqlDB, Trino, Materialize, RisingWave and timeplus (the authors) in order to query Kafka.
Read Time: 6 Minute, 6 Second In modern data pipelines, handling data in various formats such as CSV, Parquet, and JSON is essential to ensure smooth dataprocessing. However, one of the most common challenges faced by data engineers is the evolution of schemas as new data comes in.
Meanwhile, Google BigQuery ML is a machine learning service provided by Google Cloud, allowing you to create and deploy machine learning models using SQL-like syntax directly within the BigQuery environment. ensuring the consistency and integrity of your data. ELSE data[1] END, data[2] = CASE WHEN data[2] IS NULL THEN TO_FLOAT(0.0)
Structured generative AI — Oren explains how you can constraint generative algorithms to produce structured outputs (like JSON or SQL—seen as an AST). This is super interesting because it details important steps of the generative process. SQLMesh is bringing fresh ideas to the SQL transformation landscape.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content