This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this edition, we talk to Richard Meng, co-founder and CEO of ROE AI , a startup that empowers data teams to extract insights from unstructured, multimodal data including documents, images and web pages using familiar SQL queries. I experienced the thrilling pace of AI data innovation firsthand.
From unstructureddata to boundless opportunities The potential applications for this technology are vast — from small financial firms to manufacturing conglomerates, from invoice reconciliation to evidence discovery. Learn more here about Snowflake Cortex AI and Snowflake Copilot.
These scalable models can handle millions of records, enabling you to efficiently build high-performing NLP data pipelines. However, scaling LLM dataprocessing to millions of records can pose data transfer and orchestration challenges, easily addressed by the user-friendly SQL functions in Snowflake Cortex.
The Critical Role of AI Data Engineers in a Data-Driven World How does a chatbot seamlessly interpret your questions? The answer lies in unstructureddataprocessing—a field that powers modern artificial intelligence (AI) systems. How does a self-driving car understand a chaotic street scene?
This major enhancement brings the power to analyze images and other unstructureddata directly into Snowflakes query engine, using familiar SQL at scale. Unify your structured and unstructureddata more efficiently and with less complexity. Start analyzing call center data with our easy Snowflake quickstart.
In today’s data-driven world, organizations amass vast amounts of information that can unlock significant insights and inform decision-making. A staggering 80 percent of this digital treasure trove is unstructureddata, which lacks a pre-defined format or organization. What is unstructureddata?
Astasia Myers: The three components of the unstructureddata stack LLMs and vector databases significantly improved the ability to process and understand unstructureddata. The blog is an excellent summary of the existing unstructureddata landscape.
Explore AI and unstructureddataprocessing use cases with proven ROI: This year, retailers and brands will face intense pressure to demonstrate tangible returns on their AI investments.
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts. Challenges Faced by AI Data Engineers Just because “AI” involved doesn’t mean all the challenges go away!
[link] QuantumBlack: Solving data quality for gen AI applications Unstructureddataprocessing is a top priority for enterprises that want to harness the power of GenAI. It brings challenges in dataprocessing and quality, but what data quality means in unstructureddata is a top question for every organization.
With the growing application of data formats such as graphs and vectors, what do you see as the role of Arrow and its ideas in those use cases? For workflows that rely on integrating structured and unstructureddata, what are the options for interaction with non-tabular data? images, documents, etc.)
Raw data, however, is frequently disorganised, unstructured, and challenging to work with directly. Dataprocessing analysts can be useful in this situation. Let’s take a deep dive into the subject and look at what we’re about to study in this blog: Table of Contents What Is DataProcessing Analysis?
With the collective power of the open-source community, Open Table Formats remain at the cutting edge of data architecture, evolving to support emerging trends and addressing the limitations of previous systems. They also support ACID transactions, ensuring data integrity and stored data reliability.
“California Air Resources Board has been exploring processing atmospheric data delivered from four different remote locations via instruments that produce netCDF files. Previously, working with these large and complex files would require a unique set of tools, creating data silos. ” U.S.
Customers can accelerate the procurement of data and apps with the ability to purchase directly via Snowflake Marketplace and can even use existing Snowflake capacity commitments. Interoperable storage: Snowflake enables customers to access and process structured, semi-structured and unstructureddata seamlessly, without silos or delays.
link] Gradient Flow: Paradigm Shifts in DataProcessing for the Generative AI Era dataprocessing pipelines haven't kept pace with the rapid advancement of AI models The article highlights the growing importance of preprocessing data pipelines, but the pipeline processing techniques do not match the demand.
[link] Sponsored: 7/25 Amazon Bedrock Data Integration Tech Talk Streamline & scale data integration to and from Amazon Bedrock for generative AI applications. Senior Solutions Architect at AWS) Learn about: Efficient methods to feed unstructureddata into Amazon Bedrock without intermediary services like S3.
A few highlights from the report Unstructureddata goes mainstream. Question to the readers, what do you think of the current state of real-time dataprocessing engines? link] Influx Data: How Good is Parquet for Wide Tables (Machine Learning Workloads) Really? AI-driven code development is going mainstream now.
We scored the highest in hybrid, intercloud, and multi-cloud capabilities because we are the only vendor in the market with a true hybrid data platform that can run on any cloud including private cloud to deliver a seamless, unified experience for all data, wherever it lies.
A robust, flexible architecture Snowflake’s unique architecture is designed to handle the full volume, velocity and variety of data without making manufacturers deal with downtime for upgrades or compute changes. In addition, Snowflake is cloud-agnostic and can be moved to and from different cloud environments.
Today, this first-party data mostly lives in two types of data repositories. If it is structured data then it’s often stored in a table within a modern database, data warehouse or lakehouse. If it’s unstructureddata, then it’s often stored as a vector in a namespace within a vector database.
BigGeo BigGeo accelerates geospatial dataprocessing by optimizing performance and eliminating challenges typically associated with big data. It deploys gen AI components as containers on Snowpark Container Services, close to the customer’s data.
Figure 2: Questions answered by precision medicine Snowflake and FAIR in the world of precision medicine and biomedical research Cloud-based big data technologies are not new for large-scale dataprocessing. A conceptual architecture illustrating this is shown in Figure 3.
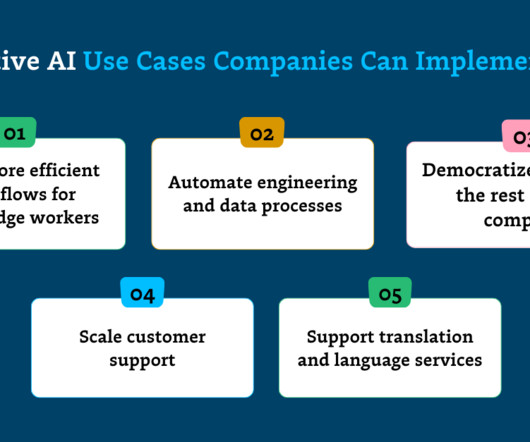
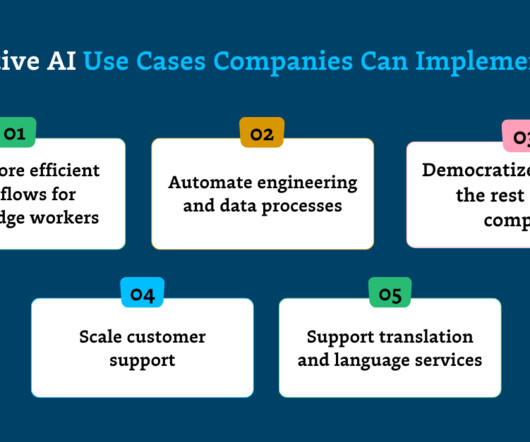
Build more efficient workflows for knowledge workers Across industries, companies are driving early generative AI use cases by automating and simplifying time-intensive processes for knowledge workers. Let’s explore how a few key sectors are putting gen AI to use.
Vector Search and UnstructuredDataProcessing Advancements in Search Architecture In 2024, organizations redefined search technology by adopting hybrid architectures that combine traditional keyword-based methods with advanced vector-based approaches.
select chatGPT('Create a SQL statement to find all the stores that have more than 100 customers per day in Washington'); How to get started You can get started with unstructureddataprocessing by following usage instructions in our documentation and quickstart guide, which includes step-by-step setup instructions.
Extraction of structured information Another strength of Generative AI is to understand unstructureddata and parse it into a more structured format. This reduces manual effort and improves the accuracy and speed of dataprocessing.
Cluster Computing: Efficient processing of data on Set of computers (Refer commodity hardware here) or distributed systems. It’s also called a Parallel Dataprocessing Engine in a few definitions. Spark is utilized for Big data analytics and related processing. Happy Learning!!!
The data driving the provider’s application is stored and processed in the provider’s own Snowflake account. Beyond delivering powerful analytical experiences, providers differentiate their products by offering live, ready-to-query data to their customers through the Snowflake Data Cloud.
The Rise of Data Observability Data observability has become increasingly critical as companies seek greater visibility into their dataprocesses. This growing demand has found a natural synergy with the rise of the data lake.
Hundreds of built-in processors make it easy to connect to any application and transform data structures or data formats as needed. Since it supports both structured and unstructureddata for streaming and batch integrations, Apache NiFi is quickly becoming a core component of modern data pipelines.
Relevance-based text search over unstructureddata (text, pdf,jpg, …). Ability to query high volumes of data (“big data”) in large clusters. Integration with Kudu for fast data and ranger for policies. Virtual private clusters. Automated wire encryption setup. Fine-grained RBAC for administrators.
VDK helps you easily perform complex operations, such as data ingestion and processing from different sources, using SQL or Python. You can use VDK to build data lakes and ingest raw data extracted from different sources, including structured, semi-structured, and unstructureddata.
We transform unstructureddata, such as text, images, and videos, into semantic fingerprints. From there, we can process information not unlike how humans do. The difference between semantha and humans is semantha processesdata in seconds instead of months.” As a Snowflake partner, it was another natural choice.
Open source frameworks such as Apache Impala, Apache Hive and Apache Spark offer a highly scalable programming model that is capable of processing massive volumes of structured and unstructureddata by means of parallel execution on a large number of commodity computing nodes. .
A data mesh can be defined as a collection of “nodes”, typically referred to as Data Products, each of which can be uniquely identified using four key descriptive properties: .
DDE also makes it much easier for application developers or data workers to self-service and get started with building insight applications or exploration services based on text or other unstructureddata (i.e. data best served through Apache Solr). What does DDE entail?
Comparison of Snowflake Copilot and Cortex Analyst Cortex Search: Deliver efficient and accurate enterprise-grade document search and chatbots Cortex Search is a fully managed search solution that offers a rich set of capabilities to index and query unstructureddata and documents.
Build more efficient workflows for knowledge workers Across industries, companies are driving early generative AI use cases by automating and simplifying time-intensive processes for knowledge workers. Let’s explore how a few key sectors are putting gen AI to use.
We’ll build a data architecture to support our racing team starting from the three canonical layers : Data Lake, Data Warehouse, and Data Mart. Data Lake A data lake would serve as a repository for raw and unstructureddata generated from various sources within the Formula 1 ecosystem: telemetry data from the cars (e.g.
Scalability and future-proofing: Modern data architecture offers robust data integration capabilities, allowing efficient and real-time data ingestion from various sources, including structured databases, unstructureddata, streaming data, and external data feeds.
Being a hybrid role, Data Engineer requires technical as well as business skills. They build scalable dataprocessing pipelines and provide analytical insights to business users. A Data Engineer also designs, builds, integrates, and manages large-scale dataprocessing systems.
Big data vs machine learning is indispensable, and it is crucial to effectively discern their dissimilarities to harness their potential. Big Data vs Machine Learning Big data and machine learning serve distinct purposes in the realm of data analysis. It focuses on collecting, storing, and processing extensive datasets.
Let’s dive into the responsibilities, skills, challenges, and potential career paths for an AI Data Quality Analyst today. Table of Contents What Does an AI Data Quality Analyst Do? Handling unstructureddata Many AI models are fed large amounts of unstructureddata, making data quality management complex.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content