This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the global data volume projected to surge from 120 zettabytes in 2023 to 181 zettabytes by 2025, PySpark's popularity is soaring as it is an essential tool for efficient large scale data processing and analyzing vast datasets. Resilient Distributed Datasets (RDDs) are the fundamental data structure in Apache Spark.
You can produce code, discover the dataschema, and modify it. Smooth Integration with other AWS tools AWS Glue is relatively simple to integrate with data sources and targets like Amazon Kinesis , Amazon Redshift, Amazon S3, and Amazon MSK. For analyzing huge datasets, they want to employ familiar Python primitive types.
The transformation of unstructured data into a structured format is a methodical process that involves a thorough analysis of the data to understand its formats, patterns, and potential challenges. Master Data Engineering at your Own Pace with Project-Based Online Data Engineering Course !
Kovid wrote an article that tries to explain what are the ingredients of a data warehouse. A data warehouse is a piece of technology that acts on 3 ideas: the data modeling, the datastorage and processing engine. Modeling is often lead by the dimensional modeling but you can also do 3NF or data vault.
So, let’s dive into the list of the interview questions below - List of the Top Amazon Data Engineer Interview Questions Explore the following key questions to gauge your knowledge and proficiency in AWS Data Engineering. Become a Job-Ready Data Engineer with Complete Project-Based Data Engineering Course !
There are three steps involved in the deployment of a big data model: Data Ingestion: This is the first step in deploying a big data model - Data ingestion, i.e., extracting data from multiple data sources. Data Variety Hadoop stores structured, semi-structured and unstructured data.
Increased Efficiency: Cloud data warehouses frequently split the workload among multiple servers. As a result, these servers handle massive volumes of data rapidly and effectively. Handle Big Data: Storage in cloud-based data warehouses may increase independently of computational resources. What is Data Purging?
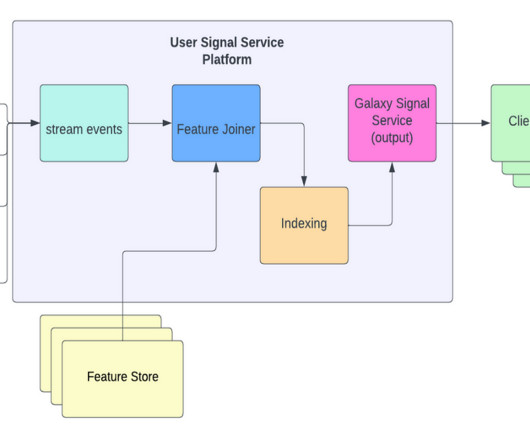
We set up a separate dataset for each event type indexed by our system, because we want to have the flexibility to scale these datasets independently. In particular, we wanted our KV store datasets to have the following properties: Allows inserts. We need each dataset to store the last N events for a user.
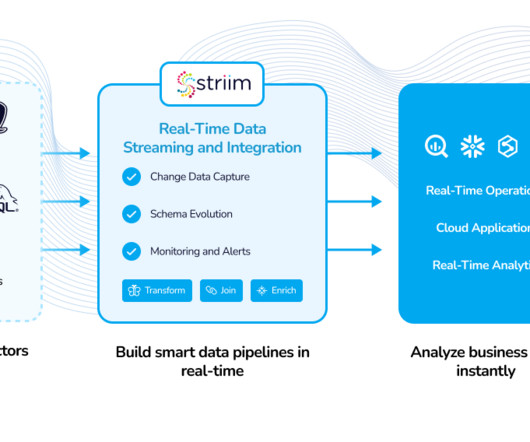
Striim, for instance, facilitates the seamless integration of real-time streaming data from various sources, ensuring that it is continuously captured and delivered to big datastorage targets. DatastorageDatastorage follows.
You can produce code, discover the dataschema, and modify it. Smooth Integration with other AWS tools AWS Glue is relatively simple to integrate with data sources and targets like Amazon Kinesis, Amazon Redshift, Amazon S3, and Amazon MSK. For analyzing huge datasets, they want to employ familiar Python primitive types.
For example, it’s good to be familiar with the different data types in the field, including: variables varchar int char prime numbers int numbers Also, named pairs and their storage in SQL structures are important concepts. These fundamentals will give you a solid foundation in data and datasets.
On-chain data has to be tied back to relevant off-chain datasets, which can require complex JOIN operations which lead to increased data latency. Image Source There are several companies that enable users to analyze on-chain data, such as Dune Analytics, Nansen, Ocean Protocol, and others.
In the modern data-driven landscape, organizations continuously explore avenues to derive meaningful insights from the immense volume of information available. Two popular approaches that have emerged in recent years are data warehouse and big data. Big data offers several advantages.
What's the difference between an RDD, a DataFrame, and a DataSet? RDDs contain all datasets and dataframes. If a similar arrangement of data needs to be calculated again, RDDs can be efficiently reserved. It's useful when you need to do low-level transformations, operations, and control on a dataset. count())) df2.show(truncate=False)
There are three steps involved in the deployment of a big data model: Data Ingestion: This is the first step in deploying a big data model - Data ingestion, i.e., extracting data from multiple data sources. Data Variety Hadoop stores structured, semi-structured and unstructured data.
Real-time data update is possible here, too, along with complete integration with all the top-notch data science tools and programming environments like Python, R, and Jupyter to ease your data manipulation analysis work. Why Use MongoDB for Data Science? Quickly pull (fetch), filter, and reduce data.
Additionally, the decentralized datastorage model reduces the time to value for data consumers by eliminating the need to transport data to a central store to power analytics. Marketing teams should have easy access to the analytical data they need for campaigns.
Versatility: The versatile nature of MongoDB enables it to easily deal with a broad spectrum of data types , structured and unstructured, and therefore, it is perfect for modern applications that need flexible dataschemas. Writing efficient and scalable MongoDB queries. Integrating MongoDB with front-end and backend systems.
Consequently, we needed a data backend with the following characteristics: Scale With ~50 commits per working day (and thus at least 50 pull request updates per day) and each commit running over one million tests, you can imagine the storage/computation required to upload and process all our data.
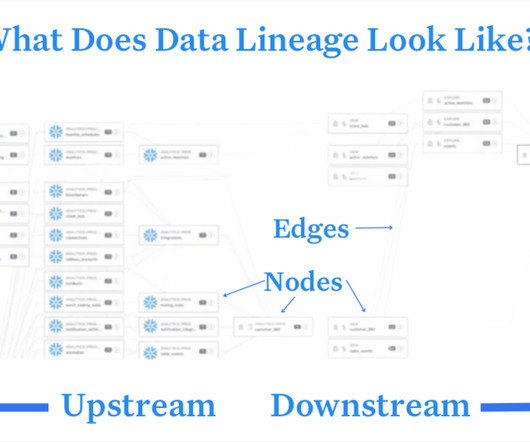
This is where data lineage can help you scope and plan your migration waves. Data lineage can also help if you are specifically looking to migrate to Snowflake like a boss. Unlike other data warehouses or datastorage repositories, Snowflake does not support partitions or indexes.
Hadoop vs RDBMS Criteria Hadoop RDBMS Datatypes Processes semi-structured and unstructured data. Processes structured data. SchemaSchema on Read Schema on Write Best Fit for Applications Data discovery and Massive Storage/Processing of Unstructured data. are all examples of unstructured data.
Hadoop vs RDBMS Criteria Hadoop RDBMS Datatypes Processes semi-structured and unstructured data. Processes structured data. SchemaSchema on Read Schema on Write Best Fit for Applications Data discovery and Massive Storage/Processing of Unstructured data. are all examples of unstructured data.
It’s like building your own data Avengers team, with each component bringing its own superpowers to the table. Here’s how a composable CDP might incorporate the modeling approaches we’ve discussed: DataStorage and Processing : This is your foundation. A good data catalog will find them in seconds.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content