This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Usually Data scientists and engineers write Extract-Transform-Load (ETL) jobs and pipelines using big data compute technologies, like Spark or Presto , to process this data and periodically compute key information for a member or a video. The processed data is typically stored as datawarehouse tables in AWS S3.
Today’s customers have a growing need for a faster end to end data ingestion to meet the expected speed of insights and overall business demand. This ‘need for speed’ drives a rethink on building a more modern datawarehouse solution, one that balances speed with platform cost management, performance, and reliability.
How self-service data warehousing frees IT resources. Cloudera DataWarehouse (CDW) is a cloud service and an integral part of the newly released Cloudera Data Platform (CDP). Key features are: Highly scalable and performant open-source engines for BI and data warehousing workloads. Simplified provisioning.
Two popular approaches that have emerged in recent years are datawarehouse and big data. While both deal with large datasets, but when it comes to datawarehouse vs big data, they have different focuses and offer distinct advantages.
So, you’re planning a cloud datawarehouse migration. But be warned, a warehouse migration isn’t for the faint of heart. As you probably already know if you’re reading this, a datawarehouse migration is the process of moving data from one warehouse to another. A worthy quest to be sure.
I'll speak about "How to build the data dream team" Let's jump onto the news. Ingredients of a DataWarehouse Going back to basics. Kovid wrote an article that tries to explain what are the ingredients of a datawarehouse. And he does it well.
In this article, Chad Sanderson , Head of Product, Data Platform , at Convoy and creator of Data Quality Camp , introduces a new application of data contracts: in your datawarehouse. In the last couple of posts , I’ve focused on implementing data contracts in production services.
In this blog, we’ll explore the significance of schema evolution using real-world examples with CSV, Parquet, and JSON data formats. Schema evolution allows for the automatic adjustment of the schema in the datawarehouse as new data is ingested, ensuring data integrity and avoiding pipeline failures.
The approach to this processing depends on the data pipeline architecture, specifically whether it employs ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) processes. This method is advantageous when dealing with structured data that requires pre-processing before storage. In what format will the final data be stored?
Meet Airbyte, the data magician that turns integration complexities into child’s play. In this digital era, businesses thrive on data, and making this data dance harmoniously with your analytics tools is crucial. Pre-filter and pre-aggregate data at the source level to optimize the data pipeline’s efficiency.
Often it is a datawarehouse solution (DWH) in the central part of our infrastructure. Datawarehouse exmaple. What I like about it is that it makes it really easy to work with various data file formats, i.e. SQL, XML, XLS, CSV and JSON. It will be a great tool for those with minimal Python knowledge.
Before going into further details on Delta Lake, we need to remember the concept of Data Lake, so let’s travel through some history. The main player in the context of the first data lakes was Hadoop, a distributed file system, with MapReduce, a processing paradigm built over the idea of minimal data movement and high parallelism.
It offers users a data integration tool that organizes data from many sources, formats it, and stores it in a single repository, such as data lakes, datawarehouses, etc., Glue uses ETL jobs for extracting data from various AWS cloud services and integrating it into datawarehouses and lakes.
A schemaless system appears less imposing for application developers that are producing the data, as it (a) spares them from the burden of planning and future-proofing the structure of their data and, (b) enables them to evolve data formats with ease and to their liking. This is depicted in Figure 1.
Data lakes, datawarehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing. However, datawarehouses can experience limitations and scalability challenges.
Data lakes, datawarehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing. However, datawarehouses can experience limitations and scalability challenges.
Data lakes, datawarehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing. However, datawarehouses can experience limitations and scalability challenges.
Using the SQL AI Assistant, we can dramatically improve our work by having an intelligent SQL expert by our side, one that also knows our dataschema very well. We can save time finding the right data, building the right syntax, and getting any new query started, with the generate feature.
Data, a driving force for business performance In light of such massive growth, data management has steadily become more complex, to the point of introducing tangible risks. ” The migration from the existing datawarehouse to the Snowflake platform took six months, with both being run in parallel during the last month.
A Beginner’s Guide [SQ] Niv Sluzki July 19, 2023 ELT is a data processing method that involves extracting data from its source, loading it into a database or datawarehouse, and then later transforming it into a format that suits business needs. The data is loaded as-is, without any transformation.
Vimeo employs more than 35 data engineers across data platform, video analytics, enterprise analytics, BI, and DataOps teams. In 2021, Vimeo moved from a process involving big complicated ETL pipelines and datawarehouse transformations to one focused on data consumer defined schemas and managed self-service analytics.
Since then, Databricks has aggressively moved toward allowing users to add more structure to their data. Features like the Delta Lake and Unity Catalog , help combine the best of both the data lake and datawarehouse worlds (see: data lakehouse ).
Exploratory data analysis Because your company is dashboard crazy and it’s easier than ever for the data engineering team to pipe in data to accommodate ad-hoc requests, discovery was challenging. The datawarehouse is a mess and devoid of semantic meaning. Most can be better at clearing out legacy datasets.
They operate one of the most sophisticated and robust data platforms in media. “We We have a couple of datawarehouses with about a petabyte in Snowflake, 1.5 petabytes in BigQuery, and about half a petabyte in Apache HBase,” said Lior Solomon, former VP of Engineering, Data, at Vimeo.
Our plan — the same plan I would have used if I had not known about Rockset — was to build an ETL package, extract the data from the document database, then transform it into a format that would be stored in a datawarehouse. From there, the data could be ingested by any standard reporting tool.
Traditionally, product engineers need to be exposed to the infra complexity, including dataschema, resource provisions, and storage allocations, which involves multiple teams. To explore life at Pinterest, visit our Careers page.
Adopting a cloud datawarehouse like Snowflake is an important investment for any organization that wants to get the most value out of their data. Most data teams, especially those early in their Snowflake journey, have yet to fully unlock full potential and value from this key investment. as well as reliability.
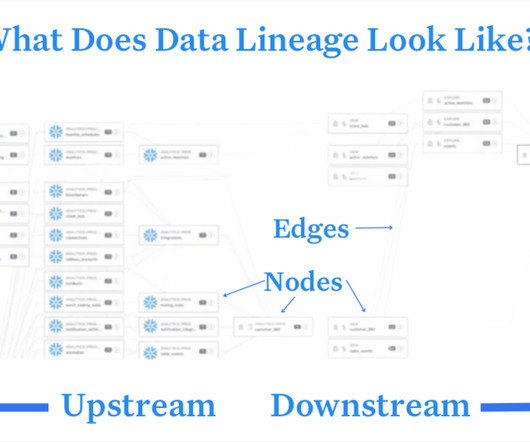
Solutions with automated data lineage capabilities constantly update these graphs and illustrate them as nodes and edges, or in other words, the objects through which the data travels and the relationship between them. This is one of the most frequent data lineage use cases leveraged by Vox. Data lineage can help!
Disclaimer: Rockset is a real-time analytics database and one of the pieces in the modern real-time data stack So What is Real-Time Data (And Why Can’t the Modern Data Stack Handle It)? Every layer in the modern data stack was built for a batch-based world. The problem? Out-of-order event streams.
Over the last several years, Databricks has given users the ability to add more structure to the data inside their data lake. Monte Carlo can automatically monitor and alert for dataschema, volume, freshness, and distribution anomalies within the data lake environment.
This aggregation process requires an analytics warehouse, as all of these things need to be synced together outside of the application database itself to incorporate other data sources (billing / events information, past touchpoints in the CRM, etc).
Consequently, we needed a data backend with the following characteristics: Scale With ~50 commits per working day (and thus at least 50 pull request updates per day) and each commit running over one million tests, you can imagine the storage/computation required to upload and process all our data.
For example, you can learn about how JSONs are integral to non-relational databases – especially dataschemas, and how to write queries using JSON. You’ll learn how to load, query, and process your data. Have experience with the JSON format It’s good to have a working knowledge of JSON.
During data ingestion, raw data is extracted from sources and ferried to either a staging server for transformation or directly into the storage level of your data stack—usually in the form of a datawarehouse or data lake. There are two primary types of raw data.
Step 5: Data Validation This is the last step involved in the process of data preparation. In this step, automated procedures are used for the data to verify its accuracy, consistency, and completeness. The prepared data is then stored in a datawarehouse or a similar repository.
Hadoop vs RDBMS Criteria Hadoop RDBMS Datatypes Processes semi-structured and unstructured data. Processes structured data. SchemaSchema on Read Schema on Write Best Fit for Applications Data discovery and Massive Storage/Processing of Unstructured data. are all examples of unstructured data.
Platform and datawarehouse migrations aren’t something you do everyday or even every few years, but they’re becoming much more frequent as organizations seek to modernize their data infrastructure with the new capabilities being offered by Snowflake, Databricks, Google, AWS, and others. Editor’s note: We agree.
Here’s how a composable CDP might incorporate the modeling approaches we’ve discussed: Data Storage and Processing : This is your foundation. You might choose a cloud datawarehouse like the Snowflake AI Data Cloud or BigQuery. It’s like turning your datawarehouse into a data distribution center.
Metaphor takes a modern approach to metadata by creating a social environment for data consumption, from the use of social hashtags in the data, social posts to share information, to automating a live wiki to access documentation.
Pig vs Hive Criteria Pig Hive Type of Data Apache Pig is usually used for semi structured data. Used for Structured DataSchemaSchema is optional. Hive requires a well-defined Schema. Language It is a procedural data flow language. Hcatalog can be used to share data structures with external systems.
Otherwise you may produce more data anomalies than you prevent. Data Contracts Image courtesy of Andrew Jones. You can think of data contracts as circuit breakers, but for dataschemas instead of the data itself.
Perhaps the dev environment is a small warehouse with different settings, or uses stubbed external sources that behave differently than real ones. For data teams, environment parity means your transformations, libraries, and even dataschemas should mirror production as closely as possible in test environments.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content