This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Usually Data scientists and engineers write Extract-Transform-Load (ETL) jobs and pipelines using big data compute technologies, like Spark or Presto , to process this data and periodically compute key information for a member or a video. The processed data is typically stored as datawarehouse tables in AWS S3.
Today’s customers have a growing need for a faster end to end data ingestion to meet the expected speed of insights and overall business demand. This ‘need for speed’ drives a rethink on building a more modern datawarehouse solution, one that balances speed with platform cost management, performance, and reliability.
How self-service data warehousing frees IT resources. Cloudera DataWarehouse (CDW) is a cloud service and an integral part of the newly released Cloudera Data Platform (CDP). Key features are: Highly scalable and performant open-source engines for BI and data warehousing workloads. Simplified provisioning.
In this article, Chad Sanderson , Head of Product, Data Platform , at Convoy and creator of Data Quality Camp , introduces a new application of data contracts: in your datawarehouse. In the last couple of posts , I’ve focused on implementing data contracts in production services.
It offers users a data integration tool that organizes data from many sources, formats it, and stores it in a single repository, such as data lakes, datawarehouses, etc., Glue uses ETL jobs for extracting data from various AWS cloud services and integrating it into datawarehouses and lakes.
Often it is a datawarehouse solution (DWH) in the central part of our infrastructure. Datawarehouse exmaple. What I like about it is that it makes it really easy to work with various data file formats, i.e. SQL, XML, XLS, CSV and JSON. It will be a great tool for those with minimal Python knowledge.
A fundamental requirement for any lasting data system is that it should scale along with the growth of the business applications it wishes to serve. NMDB is built to be a highly scalable, multi-tenant, media metadata system that can serve a high volume of write/read throughput as well as support near real-time queries.
Before going into further details on Delta Lake, we need to remember the concept of Data Lake, so let’s travel through some history. The main player in the context of the first data lakes was Hadoop, a distributed file system, with MapReduce, a processing paradigm built over the idea of minimal data movement and high parallelism.
Traditionally, data lakes held raw data in its native format and were known for their flexibility, speed, and open source ecosystem. By design, data was less structured with limited metadata and no ACID properties. Since then, Databricks has aggressively moved toward allowing users to add more structure to their data.
In the “assumptions” field, we see how the SQL AI Assistant looked over our data model; compared to what we’re looking for, it was able to find the right tables, columns, and joins needed to provide a query that will give us the list we’re looking for. And as a bonus, we even get the query written for us, saving us even more time!
Over the last several years, Databricks has given users the ability to add more structure to the data inside their data lake. Monte Carlo can automatically monitor and alert for dataschema, volume, freshness, and distribution anomalies within the data lake environment.
I can surface ownership metadata and alert the relevant owners to make sure the appropriate changes are made so these breakages never happen. And over time, we’ve invested effort into cleaning up our lineages, simplifying our logic,” said SeatGeek Director of Data Engineering, Brian London. Data lineage can help!
A data catalog is a constantly updated inventory of the universe of data assets within an organization. It uses metadata to create a picture of the data, as well as the relationships between data assets of diverse sources, and the processing that takes place as data moves through systems.
Otherwise you may produce more data anomalies than you prevent. Data Contracts Image courtesy of Andrew Jones. You can think of data contracts as circuit breakers, but for dataschemas instead of the data itself.
Why is HDFS only suitable for large data sets and not the correct tool for many small files? NameNode is often given a large space to contain metadata for large-scale files. The metadata should come from a single file for optimal space use and economic benefit. And storing these metadata in RAM will become problematic.
Here’s how a composable CDP might incorporate the modeling approaches we’ve discussed: Data Storage and Processing : This is your foundation. You might choose a cloud datawarehouse like the Snowflake AI Data Cloud or BigQuery. It’s like turning your datawarehouse into a data distribution center.
Hadoop vs RDBMS Criteria Hadoop RDBMS Datatypes Processes semi-structured and unstructured data. Processes structured data. SchemaSchema on Read Schema on Write Best Fit for Applications Data discovery and Massive Storage/Processing of Unstructured data. are all examples of unstructured data.
Pig vs Hive Criteria Pig Hive Type of Data Apache Pig is usually used for semi structured data. Used for Structured DataSchemaSchema is optional. Hive requires a well-defined Schema. Language It is a procedural data flow language. Hcatalog can be used to share data structures with external systems.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












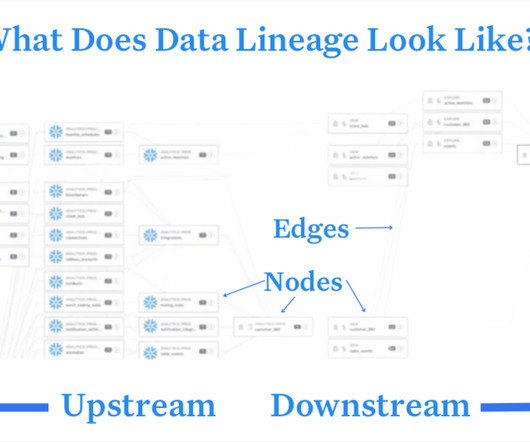

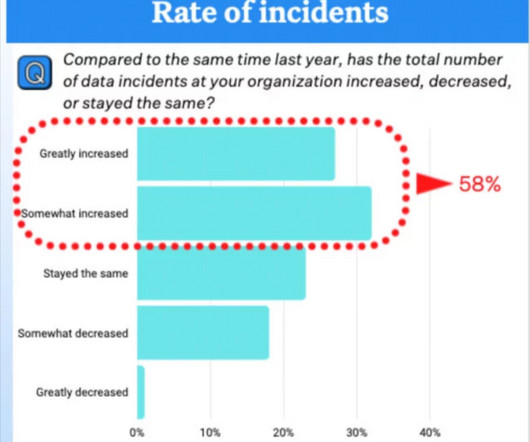










Let's personalize your content