This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the global data volume projected to surge from 120 zettabytes in 2023 to 181 zettabytes by 2025, PySpark's popularity is soaring as it is an essential tool for efficient large scale data processing and analyzing vast datasets. Resilient Distributed Datasets (RDDs) are the fundamental data structure in Apache Spark.
You can produce code, discover the dataschema, and modify it. Smooth Integration with other AWS tools AWS Glue is relatively simple to integrate with data sources and targets like Amazon Kinesis , Amazon Redshift, Amazon S3, and Amazon MSK. For analyzing huge datasets, they want to employ familiar Python primitive types.
Various sources, including Structured Data Files, Hive Tables, external databases, existing RDDs, etc., The PySpark Partition method divides a large dataset into smaller datasets using one or more partition keys. When transformations on partitioned data run more quickly, execution performance is improved.
The transformation of unstructured data into a structured format is a methodical process that involves a thorough analysis of the data to understand its formats, patterns, and potential challenges. Master Data Engineering at your Own Pace with Project-Based Online Data Engineering Course !
Modeling is often lead by the dimensional modeling but you can also do 3NF or data vault. When it comes to storage it's mainly a row-based vs. a column-based discussion, which in the end will impact how the engine will process data. The end-game dataset. This is probably the concept I liked the most from the video.
DBT (Data Build Tool) can handle incremental data loads by leveraging the incremental model , which allows only new or changed data to be processed and transformed rather than reprocessing the entire dataset. What techniques do you use to minimize run times when dealing with large datasets?
As the paved path for moving data to key-value stores, Bulldozer provides a scalable and efficient no-code solution. Users only need to specify the data source and the destination cluster information in a YAML file. Bulldozer provides the functionality to auto-generate the dataschema which is defined in a protobuf file.
Although within a big data context, Apache Spark’s MLLib tends to overperform scikit-learn due to its fit for distributed computation, as it is designed to run on Spark. Datasets containing attributes of Airbnb listings in 10 European cities ¹ will be used to create the same Pipeline in scikit-learn and MLLib. Source: The author.
Confluent enhances Kafka's capabilities with tools such as the Confluent Control Center for monitoring clusters, the Confluent Schema Registry for managing dataschemas, and Confluent KSQL for stream processing using SQL -like queries. Find datasets to stream into Kafka, such as weather data or e-commerce transactions.
Rather than scrubbing or redacting sensitive fields — or worse, creating rules to generate “realistic” data from the ground up —you simply point our app at your production schema, train one of the included models, and generate as much synthetic data as you like. It’s basically an “easy button” for synthetic data.
Managing data quality issues in ETL (Extract, Transform, Load) processes is crucial for ensuring the reliability of the transformed data. This involves a systematic approach that begins with data profiling to understand and identify anomalies in the dataset, including outliers and missing values.
You can produce code, discover the dataschema, and modify it. Smooth Integration with other AWS tools AWS Glue is relatively simple to integrate with data sources and targets like Amazon Kinesis, Amazon Redshift, Amazon S3, and Amazon MSK. For analyzing huge datasets, they want to employ familiar Python primitive types.
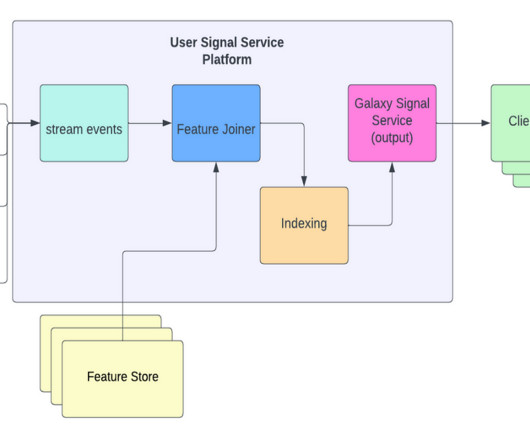
We set up a separate dataset for each event type indexed by our system, because we want to have the flexibility to scale these datasets independently. In particular, we wanted our KV store datasets to have the following properties: Allows inserts. We need each dataset to store the last N events for a user.
Indeed, datalakes can store all types of data including unstructured ones and we still need to be able to analyse these datasets. What I like about it is that it makes it really easy to work with various data file formats, i.e. SQL, XML, XLS, CSV and JSON. You can change these # to conform to your data. Datalake example.
MapReduce is a Hadoop framework used for processing large datasets. Another name for it is a programming model that enables us to process big datasets across computer clusters. This program allows for distributed data storage, simplifying complex processing and vast amounts of data. What is MapReduce in Hadoop?
Streamline Data Volume for Efficiency: While Snowflake is capable of handling large datasets, it’s essential to be mindful of data volume. Focus on sending relevant, necessary data to Snowflake to prevent overwhelming the integration process. Account for potential changes in dataschemas and structures.
Source: LinkedIn Pydantic AI vs Crew AI Pydantic AI focuses on robust data validation and parsing for Python applications. Built on Pydantic, it simplifies handling complex dataschemas with automatic type validation and error handling.
Some of the top features of Redshift are: Redshift offers fast query performance on datasets ranging from gigabytes to exabytes in size. Redshift uses data compression, zone maps, and columnar storage to reduce the amount of I/O required for query execution. This format enables the creation and operation of big datasets.
It supports SQL-based queries for precise data retrieval, batch analytics for processing large datasets, and reporting dashboards for visualizing key metrics and trends. Additionally, it facilitates machine learning applications, allowing for advanced data analysis and predictive insights.
On the hardware side, the integration of specialized hardware like Graphics Processing Units (GPUs) and Tensor Processing Units (TPUs) into data processing pipelines has revolutionized the speed at which data can be analyzed. This proactive monitoring enables data teams to address problems before they impact business decisions.
release of Grouparoo is a huge step forward for data engineers using Grouparoo to reliably sync a variety of types of data to operational tools. Models enable Grouparoo to work with multiple dataschemas at once. Now with Models, we can be more sure that all of the Records are in the same dataset and give this option.
Imagine this You’re a data scientist with a swagger working on a predictive model to optimize a fast-growing company’s digital marketing spend. After diligent data exploration, you import a few datasets into your Python notebook. Model design You see the LinkedIn ad click data has.1% Image courtesy of Chad Sanderson.
What's the difference between an RDD, a DataFrame, and a DataSet? RDDs contain all datasets and dataframes. If a similar arrangement of data needs to be calculated again, RDDs can be efficiently reserved. It's useful when you need to do low-level transformations, operations, and control on a dataset. count())) df2.show(truncate=False)
This blog post explores the challenges and solutions associated with data ingestion monitoring, focusing on the unique capabilities of DataKitchen’s Open Source Data Observability software. This process is critical as it ensures data quality from the onset. Have all the source files/data arrived on time?
Let’s take a look at some of the datasets that we receive from hospitals. Biome Analytics receives two types of datasets from hospitals: financial and clinical datasets. The clinical dataset consists of all characteristics, treatments, and outcomes of cardiac disease patients. billion financial records and 8.3
DAY 2 On day 2, as I was learning a dataschema I had never seen before, I was able to write the SQL, with some amazing help from Rockset. I extracted a string value containing deeply nested JSON data with multiple arrays, subdocuments, sub arrays, etc.,
In the modern data-driven landscape, organizations continuously explore avenues to derive meaningful insights from the immense volume of information available. Two popular approaches that have emerged in recent years are data warehouse and big data. Big data offers several advantages.
BigQuery also offers native support for nested and repeated dataschema[4][5]. We take advantage of this feature in our ad bidding systems, maintaining consistent data views from our Account Specialists’ spreadsheets, to our Data Scientists’ notebooks, to our bidding system’s in-memory data.
On-chain data has to be tied back to relevant off-chain datasets, which can require complex JOIN operations which lead to increased data latency. Image Source There are several companies that enable users to analyze on-chain data, such as Dune Analytics, Nansen, Ocean Protocol, and others.
They allow for representing various types of data and content (dataschema, taxonomies, vocabularies, and metadata) and making them understandable for computing systems. So, in terms of a “graph of data”, a dataset is arranged as a network of nodes, edges, and labels rather than tables of rows and columns.
“There were a couple of challenges because it’s easy to break this type of pipeline and an analyst would work for quite a while to find the data he’s looking for.” It involves a contract with the client sending the data , schema registry, and pipeline owners responsible for fixing any issues.
Additionally, the decentralized data storage model reduces the time to value for data consumers by eliminating the need to transport data to a central store to power analytics. Data as a product This principle can be summarized as applying product thinking to data.
It streamlines the handling of various data formats and structures within ETL workflows. In the field of data engineering, DynamicFrame boosts Glue’s capability to manage complex and diverse datasets. AWS Data Engineer Interview Questions for Experienced 17.
For example, it’s good to be familiar with the different data types in the field, including: variables varchar int char prime numbers int numbers Also, named pairs and their storage in SQL structures are important concepts. These fundamentals will give you a solid foundation in data and datasets.
Skills Required for MongoDB for Data Science To excel in MongoDB for data science, you need a combination of technical and analytical skills: Database Querying: It is necessary to know how to write sophisticated queries using the query language of MongoDB. Quickly pull (fetch), filter, and reduce data.
Database SQL database Access database Oracle database IBM Netezza MySQL database Sybase database Power Platform Power BI dataset Dataflows 4. It will ingest the data through Power BI and leverage the complete power of machine learning for easy collaboration. Each row will have one or more values that are speared by common.
Why the Lakehouse Needs Data Observability Data lakes create a ton of unique challenges for data quality. Data lakes often contain larger datasets than what you’d find in a warehouse, including massive amounts of unstructured data that wouldn’t be possible in a warehouse environment.
Companies that embraced the modern data stack reaped the rewards, namely the ability to make even smarter decisions with even larger datasets. Now more than ten years old, the modern data stack is ripe for innovation. Real-time insights delivered straight to users, i.e. the modern real-time data stack.
A customer 360 is a fancy way of saying that you have a holistic dataset that lets understand your customers’ behavior. Make sure you check your dataset to see if this is a valid assumption. Oftentimes, in a CRM’s dataschema, there’s a built-in treatment for handling merged entities. What's a customer 360?
Consequently, we needed a data backend with the following characteristics: Scale With ~50 commits per working day (and thus at least 50 pull request updates per day) and each commit running over one million tests, you can imagine the storage/computation required to upload and process all our data.
Here are the tools I chose to use: Google Bigquery acts as the main database, holding all the source data, intermediate models, and data marts. This could just as easily have been Snowflake or Redshift, but I chose BigQuery because one of my data sources is already there as a public dataset.
MapReduce is a Hadoop framework used for processing large datasets. Another name for it is a programming model that enables us to process big datasets across computer clusters. This program allows for distributed data storage, simplifying complex processing and vast amounts of data. What is MapReduce in Hadoop?
Compare and sync servers, data, schema, and other components of the database Transaction Rollback Functionality that mitigates the need for short-term backup. Key Features: Ability to navigate and manage specific database objects like tables and views.
Versatility: The versatile nature of MongoDB enables it to easily deal with a broad spectrum of data types , structured and unstructured, and therefore, it is perfect for modern applications that need flexible dataschemas.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content