This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this last installment, we’ll discuss a demo application that uses PySpark.ML to make a classification model based off of training data stored in both Cloudera’s Operational Database (powered by Apache HBase) and Apache HDFS. Training Data in HBase and HDFS. Below is a simple screen recording of the demo application.
Instagram maps on Android Actus (from Meta’s New Product Experimentation team) Facebook Crisis Response Facebook check-ins Mapillary ( iOS , Android , Web ) Meta Quest Pro demo finder WhatsApp business directory on Android Fast rendering and up-to-date data We’re now serving several basemaps.
Rather than scrubbing or redacting sensitive fields — or worse, creating rules to generate “realistic” data from the ground up —you simply point our app at your production schema, train one of the included models, and generate as much synthetic data as you like. It’s basically an “easy button” for synthetic data.
Data integration As a Snowflake Native App, AI Decisioning leverages the existing data within an organization’s AI Data Cloud, including customer behaviors and product and offer details. During a one-time setup, your data owner maps your existing dataschemas within the UI, which fuels AI Decisioning’s models.
Pre-filter and pre-aggregate data at the source level to optimize the data pipeline’s efficiency. Adapt to Changing DataSchemas: Data sources aren’t static; they evolve. Account for potential changes in dataschemas and structures.
A data observability tool Monte Carlo , for example, uses AI to continuously monitor data pipelines, automatically detecting anomalies and inconsistencies. By analyzing patterns and trends in the data, AI can identify issues such as missing or duplicate data, schema changes, and unexpected data values.
Therefore, not restricting access to the Schema Registry might allow an unauthorized user to mess with the service in such a way that client applications can no longer be served schemas to deserialize their data. Allow end user REST API calls to Schema Registry over HTTPS instead of the default HTTP.
And by leveraging distributed storage and open-source technologies, they offer a cost-effective solution for handling large data volumes. In other words, the data is stored in its raw, unprocessed form, and the structure is imposed when a user or an application queries the data for analysis or processing.
And by leveraging distributed storage and open-source technologies, they offer a cost-effective solution for handling large data volumes. In other words, the data is stored in its raw, unprocessed form, and the structure is imposed when a user or an application queries the data for analysis or processing.
And by leveraging distributed storage and open-source technologies, they offer a cost-effective solution for handling large data volumes. In other words, the data is stored in its raw, unprocessed form, and the structure is imposed when a user or an application queries the data for analysis or processing.
Strimmer: To build the data pipeline for our Strimmer service, we’ll use Striim’s streaming ETL data processing capabilities, allowing us to clean and format the data before it’s stored in the data store. Schedule a demo today to discover how Striim can transform your data management strategy.
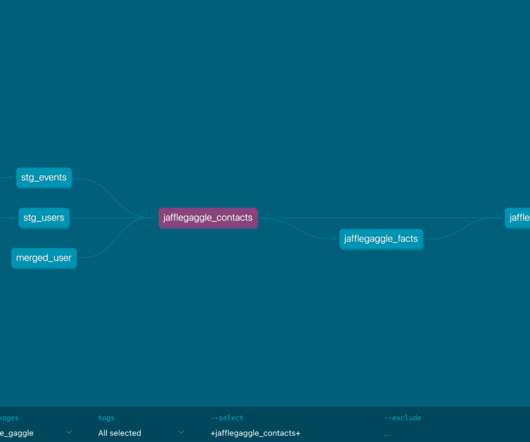
It includes a set of demo CSV files, which you can use as dbt seeds to test Donny's project for yourself. If not, I’d recommend taking a second to look at Claire Carroll’s README for the original Jaffle Shop demo project (otherwise this playbook is probably going to be a little weird, but still useful, to read).
Unbeknownst to you, the training data contains a table with aggregated visitor website data with columns that haven’t been updated in a month. It turns out the marketing operations team upgraded to Google Analytics 4 to get ahead of the July 2023 deadline which changed the dataschema.
Although the Kafka Streams library is “dataschema agnostic” today and therefore cannot leverage many standard techniques from the query processing literature, such as predicate pushdown, there is still a large optimization room on structural topology formation for it to explore. Bill has been a software engineer for over 15 years.
Compare and sync servers, data, schema, and other components of the database Transaction Rollback Functionality that mitigates the need for short-term backup. You can check to see if they have a free version and give it a shot first with some dummy data. Some SQL tool providers also offer limited demo versions.
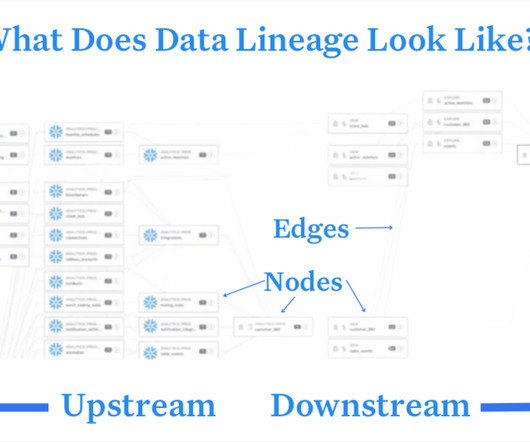
A few tips for a safe migration using data lineage: Document current dataschema and lineage. This will be important for when you have to cross-reference your old data ecosystem with your new one. Analyze your current schema and lineage.
But just to be safe, here are a few tips: Document your current dataschema and lineage. This will be important when you have to cross-reference your old data ecosystem with your new one. But with the right planning—and a few best practices—you’ll be on your way to leveraging a shiny dew cloud data warehouse in no time (ish).
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content