This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
And as the data produced by indexing can become large, we want to make it available over the network through a query interface rather than having to download it. Therefore: Glean doesnt decide for you what data you can store. The data is ultimately stored using RocksDB , providing good scalability and efficient retrieval.
Instead, when a particular client application is launched, the location of its JAR file is passed using an environment variable, and that JAR is downloaded during initialization in entrypoint.sh: #!/bin/bash bin/bash set -eo pipefail # This variable will also be used in the SparkSession builder within # the application code.
Pre-filter and pre-aggregate data at the source level to optimize the data pipeline’s efficiency. Adapt to Changing DataSchemas: Data sources aren’t static; they evolve. Account for potential changes in dataschemas and structures. Download Docker Desktop from here as a prerequisite.
A schemaless system appears less imposing for application developers that are producing the data, as it (a) spares them from the burden of planning and future-proofing the structure of their data and, (b) enables them to evolve data formats with ease and to their liking. This is depicted in Figure 1.
The data from these detections are then serialized into Avro binary format. The Avro alert dataschemas for ZTF are defined in JSON documents and are published to GitHub for scientists to use when deserializing data upon receipt. Interested in more? Armed with a Ph.D.
These playbooks describe how to notify people and give them time to download their data, how to disable the product safely, and when to eventually delete the underlying code and data. The interconnected nature of features within a large product like Facebook makes this a very real possibility. How did we solve this?
You can produce code, discover the dataschema, and modify it. Smooth Integration with other AWS tools AWS Glue is relatively simple to integrate with data sources and targets like Amazon Kinesis, Amazon Redshift, Amazon S3, and Amazon MSK. Then Redshift can be used as a data warehousing tool for this.
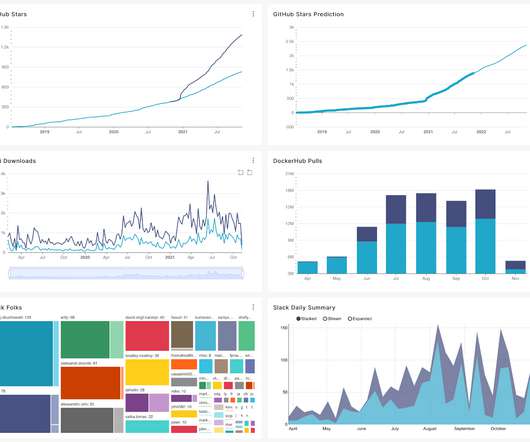
I can visit the GitHub page for a project and see the number of stars, or look at a package on PyPI when I need to know how many downloads it's gotten. You need to collect the data that's important to your business and study how it changes over time. It used to be that when you wanted to consume a bit of tech, you'd download a file.
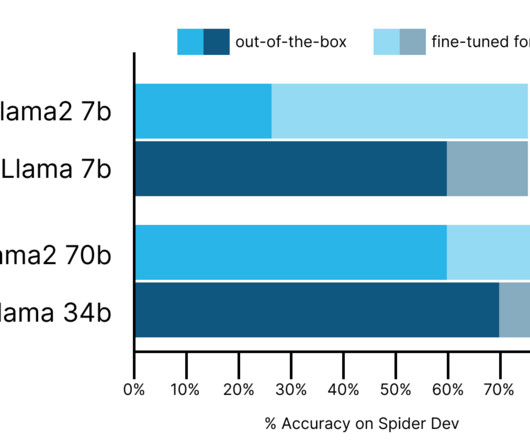
On Hugging Face alone , the Llama2 family was downloaded over 1.4 Snowflake is leveraging our SQL expertise to provide the best text-to-SQL capabilities that combine syntactically correct SQL with a deep understanding of customers’ sophisticated dataschemas, governed and protected by their existing rights, roles and access controls.
spark.jars.packages: Downloads the required JAR files from the Maven repository. One of its neat features is the ability to store data in a compressed format, with snappy compression being the go-to choice. Another cool aspect of Parquet is its flexible approach to dataschemas. io.delta:delta-spark_2.12:3.0.0").config("spark.hadoop.fs.s3a.endpoint",
Understanding Power BI Requirements As I have mentioned before, Power BI is a revolutionary, remarkable program that enables high-speed data integration and the creation of plenty of reports. This is made possible by automated data extraction from servers, computers, and clouds.
Compare and sync servers, data, schema, and other components of the database Transaction Rollback Functionality that mitigates the need for short-term backup. Key Features: It allows low-volume downloads – as small as 25MB. It supports multiple data entry formats like SQL INSERT, HTML, XML, JSON, and CSV, XML.
Rising Demand: Recent industry reports state that the adoption of MongoDB has been increasing, and the database has attracted over 40 million download users from thousands of organizations. This exponential growth highlights the increasing need for MongoDB skills across many sectors, such as finance, healthcare, e-commerce, and technology.
Hadoop vs RDBMS Criteria Hadoop RDBMS Datatypes Processes semi-structured and unstructured data. Processes structured data. SchemaSchema on Read Schema on Write Best Fit for Applications Data discovery and Massive Storage/Processing of Unstructured data. are all examples of unstructured data.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content