This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The appropriate Spark dependencies (spark-core/spark-sql or spark-connect-client-jvm) will be provided later in the Java classpath, depending on the run mode. java -cp "/app/*" com.joom.analytics.sc.client.S3Downloader ${MAIN_APPLICATION_FILE_S3_PATH} ${SPARK_CONNECT_MAIN_APPLICATION_FILE_PATH} # Launch the client application.
They can be represented in OOP languages (Java, C++, etc.), Whereas the author illustrates his examples using JavaScript and Java, this article attempts to demonstrate the ideas in Python. Unlike Java, there is no compilation step in Python, which means there is no compiler optimization when it comes to accessing a class member.
Therefore, not restricting access to the Schema Registry might allow an unauthorized user to mess with the service in such a way that client applications can no longer be served schemas to deserialize their data. Allow end user REST API calls to Schema Registry over HTTPS instead of the default HTTP.
The alleviation of infrastructure and computational constraints associated with solely on-premises data platforms; Data Products can now use different deployment models (e.g., Deep Java Learning, Apache Spark 3.x, hybrid or public, multi-cloud) and advanced analytical frameworks (e.g.,
An engineer needs to delete their mobile code (Java, Objective-C) in order to free up and delete their server-side GraphQL definitions. Deleting those GraphQL definitions makes it possible to delete business logic; deleting business logic makes it possible to delete dataschema definitions, which in turn allows unused data to be deleted.
For example, you can learn about how JSONs are integral to non-relational databases – especially dataschemas, and how to write queries using JSON. Some good options are Python (because of its flexibility and being able to handle many data types), as well as Java, Scala, and Go. Rely on the real information to guide you.
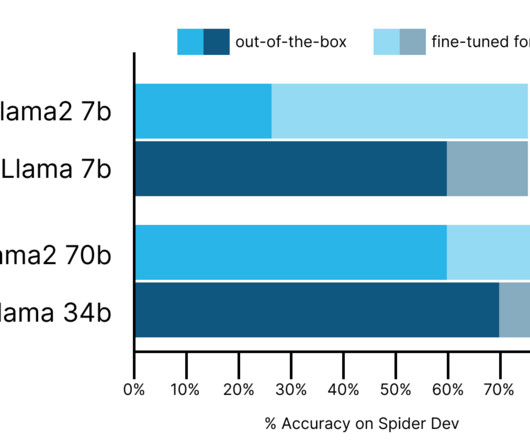
Along with the model release, Meta published Code Llama performance benchmarks on HumanEval and MBPP for common coding languages such as Python, Java, and JavaScript. On August 24, Meta released Code Llama , a new series of Llama2 models fine-tuned for code generation.
com.amazonaws:aws-java-sdk-bundle:1.11.1026,org.apache.spark:spark-avro_2.12:3.5.0,io.delta:delta-spark_2.12:3.0.0").config("spark.hadoop.fs.s3a.endpoint", One of its neat features is the ability to store data in a compressed format, with snappy compression being the go-to choice. io.delta:delta-spark_2.12:3.0.0").config("spark.hadoop.fs.s3a.endpoint",
show(truncate=False) #Drop duplicates on selected columns dropDisDF = df.dropDuplicates(["department","salary"]) print("Distinct count of department salary : "+str(dropDisDF.count())) dropDisDF.show(truncate=False) } Get FREE Access to Data Analytics Example Codes for Data Cleaning, Data Munging, and Data Visualization Q6.
Web developers need to be proficient in back-end programming languages like PHP, Java, Ruby, and.NET. They must understand SEO terms like meta data, schema, indexing and more. They enable the creation of dynamic websites that may communicate with databases and offer users individualized experiences.
Versatility: The versatile nature of MongoDB enables it to easily deal with a broad spectrum of data types , structured and unstructured, and therefore, it is perfect for modern applications that need flexible dataschemas. Good Hold on MongoDB and data modeling. Experience with ETL tools and data integration techniques.
Map tasks deal with mapping and data splitting, whereas Reduce tasks shuffle and reduce data. Hadoop can execute MapReduce applications in various languages, including Java, Ruby, Python, and C++. Each daemon runs in a separate Java process in this mode, and all the master and slave services run on a single node.
Hadoop vs RDBMS Criteria Hadoop RDBMS Datatypes Processes semi-structured and unstructured data. Processes structured data. SchemaSchema on Read Schema on Write Best Fit for Applications Data discovery and Massive Storage/Processing of Unstructured data. are all examples of unstructured data.
Pig vs Hive Criteria Pig Hive Type of Data Apache Pig is usually used for semi structured data. Used for Structured DataSchemaSchema is optional. Hive requires a well-defined Schema. Language It is a procedural data flow language. Follows SQL Dialect and is a declarative language.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content