This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
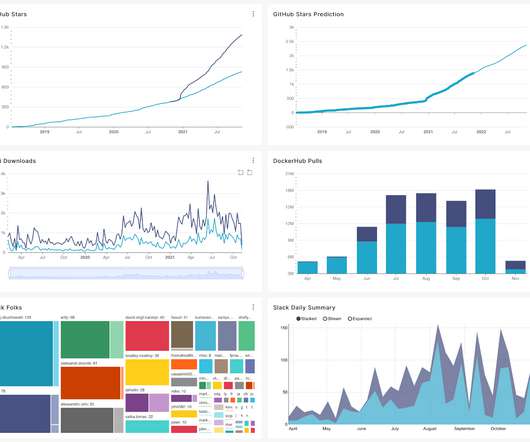
A fundamental requirement for any lasting data system is that it should scale along with the growth of the business applications it wishes to serve. NMDB is built to be a highly scalable, multi-tenant, media metadata system that can serve a high volume of write/read throughput as well as support near real-time queries.
When Glue receives a trigger, it collects the data, transforms it using code that Glue generates automatically, and then loads it into Amazon S3 or Amazon Redshift. Then, Glue writes the job's metadata into the embedded AWS Glue Data Catalog. You can produce code, discover the dataschema, and modify it.
What I like about it is that it makes it really easy to work with various data file formats, i.e. SQL, XML, XLS, CSV and JSON. Among other benefits, I like that it works well with semi-complex dataschemas. Pandas is an absolute beast in the world of data and there is no need to cover it’s capabilities in this story. .")
As the paved path for moving data to key-value stores, Bulldozer provides a scalable and efficient no-code solution. Users only need to specify the data source and the destination cluster information in a YAML file. Bulldozer provides the functionality to auto-generate the dataschema which is defined in a protobuf file.
Traditionally, data lakes held raw data in its native format and were known for their flexibility, speed, and open source ecosystem. By design, data was less structured with limited metadata and no ACID properties. Unity Catalog The Unity Catalog unifies metastores, catalogs, and metadata within Databricks.
Schema Management. Avro format messages are stored in Kafka for better performance and schema evolution. Cloudera Schema Registry is designed to store and manage dataschemas across services. NiFi data flows can refer to the schemas in the Registry instead of hard coding. . > Minutes.
The Media Document Model The Media Document model is intended to be a flexible framework that can be used to represent static as well as dynamic (varying with time and space) metadata for various media modalities. Timing Model We use the Media Document model to represent timed metadata for our media assets.
BigQuery also offers native support for nested and repeated dataschema[4][5]. We take advantage of this feature in our ad bidding systems, maintaining consistent data views from our Account Specialists’ spreadsheets, to our Data Scientists’ notebooks, to our bidding system’s in-memory data.
After launching our partnership with Databricks last year, Monte Carlo has aggressively expanded our native Databricks and Apache Spark™ integrations to extend data observability into the Delta Lake and Unity Catalog, and in the process, drive even more value for Databricks customers.
Delta Lake also refuses writes with wrongly formatted data (schema enforcement) and allows for schema evolution. It contains a detailed description of each operation performed, including all the metadata about the operation. show() The history object is a Spark Data Frame. delta_table.history().select("version",
The StructType and StructField classes in PySpark are used to define the schema to the DataFrame and create complex columns such as nested struct, array, and map columns. StructType is a collection of StructField objects that determines column name, column data type, field nullability, and metadata. appName('ProjectPro').getOrCreate()
In the “assumptions” field, we see how the SQL AI Assistant looked over our data model; compared to what we’re looking for, it was able to find the right tables, columns, and joins needed to provide a query that will give us the list we’re looking for. And as a bonus, we even get the query written for us, saving us even more time!
spark.sql.catalog.spark_catalog: Sets the Spark catalog to Delta Lake’s catalog, allowing table management and metadata operations to be handled by Delta Lake. One of its neat features is the ability to store data in a compressed format, with snappy compression being the go-to choice.
This could just as easily have been Snowflake or Redshift, but I chose BigQuery because one of my data sources is already there as a public dataset. dbt seeds data from offline sources and performs necessary transformations on data after it's been loaded into BigQuery. I spun up an instance using its docker/up.sh
The logical basis of RDF is extended by related standards RDFS (RDF Schema) and OWL (Web Ontology Language). They allow for representing various types of data and content (dataschema, taxonomies, vocabularies, and metadata) and making them understandable for computing systems.
In addition, it can be challenging to keep a strong control of costs and to know where your data resides in an effort to serve your business well. Shared Data Experience (SDX), a shared persistent layer of access models, lineage-audit trace, and all metadata, is the key to the Cloudera data lake implementation.
For this specific case, when the StreamBuilder#build() method is called, Streams will “push up” the repartitioning phase of the logical plan based on the captured metadata before compiling it to the processor topology. With the topology optimization framework added to the Streams DSL layer in Kafka 2.1,
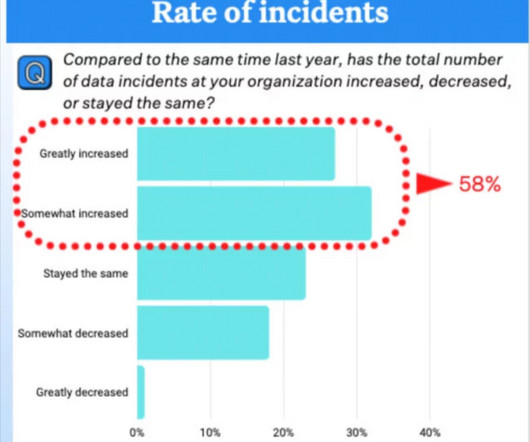
The holistic approach of the post-modern data stack translates into numerous benefits: First, it accelerates pinpointing and troubleshooting pipeline hotspots with a single console that observes the entire data pipeline and all its processes. Change Enablement In the world of data, change is as inevitable as the rising sun.
All of these options allow you to define the schema of the contract, describe the data, and store relevant metadata like semantics, ownership, and constraints. We can specify the fields of the contract in addition to metadata like ownership, SLA, and where the table is located. Consistency in your tech stack.
System architecture context relevant for the Landing Page stack Content Data Model The actual content of a landing page is managed within Contentful as "entries"; each entry-type having its own dataschema definition, validation rules and a content-upload UI for the content editors. The main entry is the landing page itself.
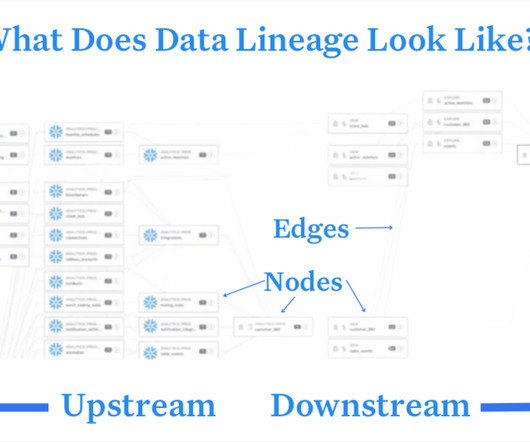
I can surface ownership metadata and alert the relevant owners to make sure the appropriate changes are made so these breakages never happen. A few tips for a safe migration using data lineage: Document current dataschema and lineage. Analyze your current schema and lineage.
Why is HDFS only suitable for large data sets and not the correct tool for many small files? NameNode is often given a large space to contain metadata for large-scale files. The metadata should come from a single file for optimal space use and economic benefit. And storing these metadata in RAM will become problematic.
We want to avoid unwanted data coupling and allow Renderers to be reused in other contexts with minimal risks. Renderers have access to Zalando’s GraphQL Mutation APIs which allows remote data to be modified. Rendering Engine Rendering Engine is the framework powering the Renderers. The page rendering always starts with an Entity.
Hadoop vs RDBMS Criteria Hadoop RDBMS Datatypes Processes semi-structured and unstructured data. Processes structured data. SchemaSchema on Read Schema on Write Best Fit for Applications Data discovery and Massive Storage/Processing of Unstructured data. are all examples of unstructured data.
A data catalog is a constantly updated inventory of the universe of data assets within an organization. It uses metadata to create a picture of the data, as well as the relationships between data assets of diverse sources, and the processing that takes place as data moves through systems.
Pig vs Hive Criteria Pig Hive Type of Data Apache Pig is usually used for semi structured data. Used for Structured DataSchemaSchema is optional. Hive requires a well-defined Schema. Language It is a procedural data flow language. Hive stores the metadata in RDBMS rather than HDFS.
A data catalog is a detailed inventory of all the customer data assets within your organization, including datasets, databases, APIs, and even reports and dashboards. It’s like having a detailed card catalog for your customer data library. Those days are gone!
Otherwise you may produce more data anomalies than you prevent. Data Contracts Image courtesy of Andrew Jones. You can think of data contracts as circuit breakers, but for dataschemas instead of the data itself.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content