This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
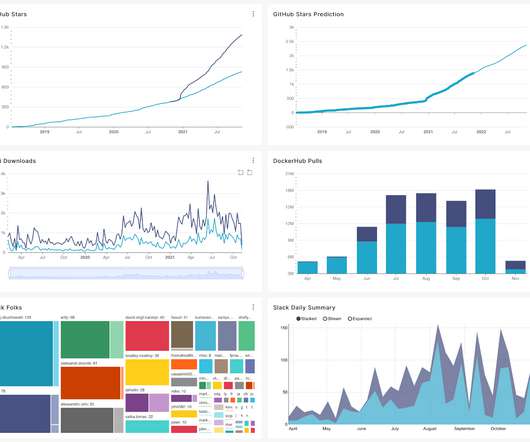
In the previous blog posts in this series, we introduced the N etflix M edia D ata B ase ( NMDB ) and its salient “Media Document” data model. In this post we will provide details of the NMDB system architecture beginning with the system requirements?—?these key value stores generally allow storing any data under a key).
When Glue receives a trigger, it collects the data, transforms it using code that Glue generates automatically, and then loads it into Amazon S3 or Amazon Redshift. Then, Glue writes the job's metadata into the embedded AWS Glue Data Catalog. You can produce code, discover the dataschema, and modify it.
BigQuery also offers native support for nested and repeated dataschema[4][5]. We take advantage of this feature in our ad bidding systems, maintaining consistent data views from our Account Specialists’ spreadsheets, to our Data Scientists’ notebooks, to our bidding system’s in-memory data.
The data warehouse is not designed to serve point requests from microservices with low latency. Therefore, we must efficiently move data from the data warehouse to a global, low-latency and highly-reliable key-value store. Users only need to specify the data source and the destination cluster information in a YAML file.
The Data Lake architecture was proposed in a period of great growth in the data volume, especially in non-structured and semi-structured data, when traditional Data Warehouse systems start to become incapable of dealing with this demand. The data became useless. Legend says, that this didn’t go well.
the Media Timeline Data Model In the previous post in this series, we described some important Netflix business needs as well as traits of the media datasystem?—?called The curious reader might have noticed that a majority of these characteristics relate to properties of the data managed by NMDB.
After launching our partnership with Databricks last year, Monte Carlo has aggressively expanded our native Databricks and Apache Spark™ integrations to extend data observability into the Delta Lake and Unity Catalog, and in the process, drive even more value for Databricks customers.
Second, if the partition number is increased after the system goes live, the default Kafka partitioner will return different numbers evenly if you provide the same key, which means messages with the same key as before will be in a different partition from the previous one. . > Schema Management. > Minutes.
Parquet vs ORC vs Avro vs Delta Lake Photo by Viktor Talashuk on Unsplash The big data world is full of various storage systems, heavily influenced by different file formats. These are key in nearly all data pipelines, allowing for efficient data storage and easier querying and information extraction.
The StructType and StructField classes in PySpark are used to define the schema to the DataFrame and create complex columns such as nested struct, array, and map columns. StructType is a collection of StructField objects that determines column name, column data type, field nullability, and metadata. appName('ProjectPro').getOrCreate()
machine learning , allowing for analyzing the knowledge contained in the source data and generating new knowledge. The logical basis of RDF is extended by related standards RDFS (RDF Schema) and OWL (Web Ontology Language). Knowledge graphs for organizing data over the internet. Recommender systems in entertainment.
A data catalog is a constantly updated inventory of the universe of data assets within an organization. It uses metadata to create a picture of the data, as well as the relationships between data assets of diverse sources, and the processing that takes place as data moves through systems.
This could just as easily have been Snowflake or Redshift, but I chose BigQuery because one of my data sources is already there as a public dataset. dbt seeds data from offline sources and performs necessary transformations on data after it's been loaded into BigQuery. I spun up an instance using its docker/up.sh
This framework opens the door for various optimization techniques from the existing data stream management system (DSMS) and data stream processing literature. addSink(" SinkProcessor" , "output" , "MappingProcessor" ); System. build(properties); System. With the release of Apache Kafka ® 2.1.0, println(builder.
Also, it was based on Zalando's "Mosaic" system architecture, which was being phased out in favour of the newer Interface Framework. Interface Framework - To integrate the tool with Zalando's new architecture and design system, to leverage its capabilities and scale with it. However, it had many limitations affecting scalability.
For example, a global media company struggled because they were juggling different tools like Fivetran for bringing in data, dbt for transforming it, Airflow for coordinating everything, Monte Carlo for monitoring and scanning for troubled data, and Hightouch for getting data out to other systems.
Key features Hadoop RDBMS Overview Hadoop is an open-source software collection that links several computers to solve problems requiring large quantities of data and processing. RDBMS is a part of system software used to create and manage databases based on the relational model. RDBMS stores structured data.
It can be challenging when a team is expected to take full responsibility for a key data product when there are no guarantees around the upstream data quality. Without clear management of each transformation step stretching back to source systems, teams may be unwilling to bear the responsibility of contracts.
Otherwise you may produce more data anomalies than you prevent. Data Contracts Image courtesy of Andrew Jones. You can think of data contracts as circuit breakers, but for dataschemas instead of the data itself. Write clear SQL statements Let’s face it, some of the SQL formatting debates are silly.
Since they share most parts of the user journey, it was natural to explore if the Apps could benefit from a system based on Entities and Renderers, too. We want to avoid unwanted data coupling and allow Renderers to be reused in other contexts with minimal risks. We knew it would be too much of a stretch for Mosaic fragments.
Hadoop vs RDBMS Criteria Hadoop RDBMS Datatypes Processes semi-structured and unstructured data. Processes structured data. SchemaSchema on Read Schema on Write Best Fit for Applications Data discovery and Massive Storage/Processing of Unstructured data. are all examples of unstructured data.
It can generate a lot of data, which means you need robust storage and processing capabilities. Making sense of all those events can be complex – you might need to invest in stream processing technologies or complex event processing systems to really leverage the power of this approach.
Pig vs Hive Criteria Pig Hive Type of Data Apache Pig is usually used for semi structured data. Used for Structured DataSchemaSchema is optional. Hive requires a well-defined Schema. Language It is a procedural data flow language. Hcatalog can be used to share data structures with external systems.
In data-driven organizations, to fulfill its charter to democratize data and provide on-demand, quality computing services in a secure, compliant environment, IT must replace legacy approaches and update technologies. There needs to emerge data-first, self-service replacement for these old systems. billion dollars.’.
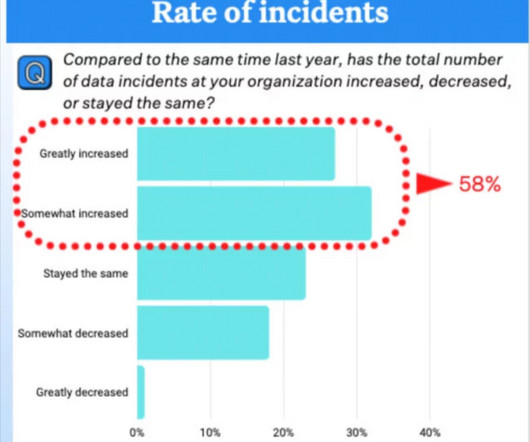
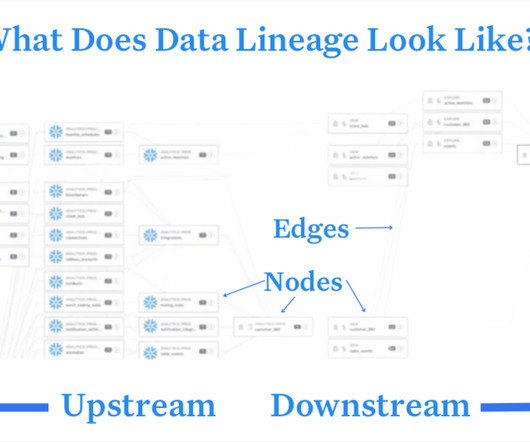
What are the data lineage use cases and best practices that will drive value for the business? Here is a list of 17 valuable data lineage use cases that can help improve data quality, incident management, democratization, system modernization, and compliance. We’re glad you asked.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content