This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data warehouses are typically built using traditional relationaldatabase systems, employing techniques like Extract, Transform, Load (ETL) to integrate and organize data. Data warehousing offers several advantages. By structuringdata in a predefined schema, data warehouses ensure data consistency and accuracy.
In an ETL-based architecture, data is first extracted from source systems, then transformed into a structured format, and finally loaded into data stores, typically data warehouses. This method is advantageous when dealing with structureddata that requires pre-processing before storage.
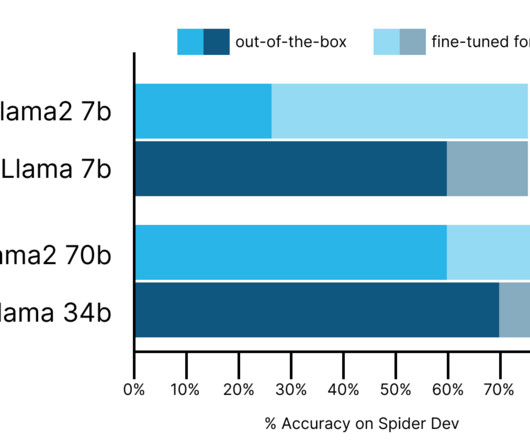
SQL—the standard programming language of relationaldatabases—was not included in these benchmarks. As part of our vision to bring generative AI and LLMs to the data , we are evaluating a variety of foundational models that could serve as the baseline for text-to-SQL capabilities in the Data Cloud.
data access semantics that guarantee repeatable data read behavior for client applications. System Requirements Support for StructuredData The growth of NoSQL databases has broadly been accompanied with the trend of data “schemalessness” (e.g., However unlike the media dataschema, MID schema is immutable.
Big Data is a collection of large and complex semi-structured and unstructured data sets that have the potential to deliver actionable insights using traditional data management tools. Big data operations require specialized tools and techniques since a relationaldatabase cannot manage such a large amount of data.
show(truncate=False) #Drop duplicates on selected columns dropDisDF = df.dropDuplicates(["department","salary"]) print("Distinct count of department salary : "+str(dropDisDF.count())) dropDisDF.show(truncate=False) } Get FREE Access to Data Analytics Example Codes for Data Cleaning, Data Munging, and Data Visualization Q6.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












Let's personalize your content