This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Co-authors: Max Kanat-Alexander and Grant Jenks Today we are open-sourcing the LinkedIn Developer Productivity & Happiness Framework (DPH Framework) - a collection of documents that describe the systems, processes, metrics, and feedback systems we use to understand our developers and their needs internally at LinkedIn.
Read Time: 6 Minute, 6 Second In modern data pipelines, handling data in various formats such as CSV, Parquet, and JSON is essential to ensure smooth data processing. However, one of the most common challenges faced by data engineers is the evolution of schemas as new data comes in.
Below are the Power BI requirements for the system. Supported operating system: Power BI program can be installed in a device with the following operations systems. Windows Server 2019 Data Centre, server 2019 standard, server 2016 standard, server 2016 datacenter.
BigQuery also offers native support for nested and repeated dataschema[4][5]. We take advantage of this feature in our ad bidding systems, maintaining consistent data views from our Account Specialists’ spreadsheets, to our Data Scientists’ notebooks, to our bidding system’s in-memory data.
In the previous blog posts in this series, we introduced the N etflix M edia D ata B ase ( NMDB ) and its salient “Media Document” data model. In this post we will provide details of the NMDB system architecture beginning with the system requirements?—?these key value stores generally allow storing any data under a key).
Sharvit deconstructs the elements of complexity that sometimes seems inevitable with OOP and summarizes the main principles of DOP that helps us make the system more manageable. As its name suggests, DOP puts data first and foremost. The existence of dataschema at a class level makes it easy to discover the expected data shape.
Modeling is often lead by the dimensional modeling but you can also do 3NF or data vault. When it comes to storage it's mainly a row-based vs. a column-based discussion, which in the end will impact how the engine will process data.
After an employee confirms that the transaction is, in fact, fraudulent, that employee can let the system know that the model made a correct prediction which then can be used as additional training data to improve the underlying model. . Training Data in HBase and HDFS. In order to view the web application, go to [link].
This data pipeline is a great example of a use case for Apache Kafka ®. Observational astronomers study many different types of objects, from asteroids in our own solar system to galaxies that are billions of lightyears away. The technology underlying the ZTF system should be a prototype that reliably scales to LSST needs.
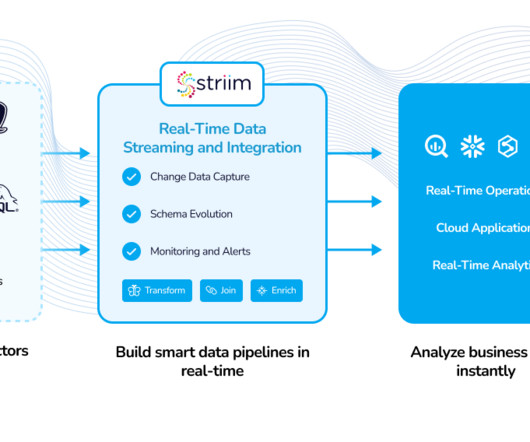
It simplifies the process of extracting, transforming, and loading (ETL) data by providing connectors for a wide range of data sources and destinations. Whether you need to integrate data from databases, APIs, cloud services, or other systems, Airbyte provides the tools to make it easier and more efficient.
They have built an easy to use platform that lets you leverage your company’s single sign on for your data platform. Go to dataengineeringpodcast.com/strongdm today to find out how you can simplify your systems. How does the concept of a data slice play into the overall architecture of your platform?
You can produce code, discover the dataschema, and modify it. Smooth Integration with other AWS tools AWS Glue is relatively simple to integrate with data sources and targets like Amazon Kinesis, Amazon Redshift, Amazon S3, and Amazon MSK. AWS Glue automates several processes as well. Establish a crawler schedule.
It is better to be careful about which applications should be run on the shared Spark Connect server, as resource-intensive applications may cause problems for the entire system. amazonaws.com", // and others. ) def createStandaloneSessionCatalog(): (SessionCatalog, Configuration) = { val sparkConf = new SparkConf().setAll(sessionCatalogConfig)
It continuously experiments and analyzes data from the airline’s AI Data Cloud to customize post-purchase offers, such as seat upgrades, excursions or trip insurance. The system dynamically selects the best offers, channels and timing for each customer, ensuring maximum impact and engagement.
Once an architectural luxury, data governance has become a necessity for the modern enterprise across the entire stack. For Kafka, all producers and consumers are required to agree on those dataschemas to serialize and deserialize messages. Schema Validation lays the foundation for data governance in Confluent Platform.
As a result, data forensics capabilities such as data lineage, ad-hoc queries and standardized reports on databases that store data changes and dataschema evolution history are a key requirement of modern data platforms.
The data warehouse is not designed to serve point requests from microservices with low latency. Therefore, we must efficiently move data from the data warehouse to a global, low-latency and highly-reliable key-value store. Users only need to specify the data source and the destination cluster information in a YAML file.
Here are six key components that are fundamental to building and maintaining an effective data pipeline. Data sources The first component of a modern data pipeline is the data source, which is the origin of the data your business leverages. Are we going to be enriching the data with specific attributes?
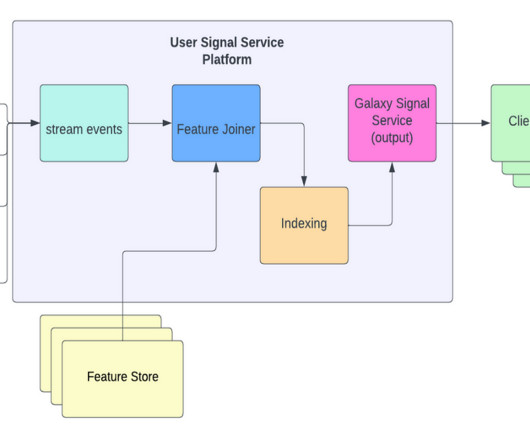
So our user sequence real-time indexing pipeline is composed of a Flink job that reads the relevant events as they come into our Kafka streams, fetches the desired features for each event from our feature services, and stores the enriched events into our KV store system. The first module retrieves key-value data from the storage system.
The Data Lake architecture was proposed in a period of great growth in the data volume, especially in non-structured and semi-structured data, when traditional Data Warehouse systems start to become incapable of dealing with this demand. The data became useless. Legend says, that this didn’t go well.
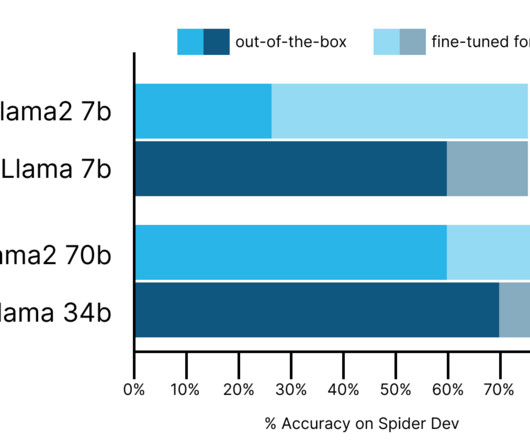
For prompting Code Llama, we simplified this prompt, removing the system component. The full system and few-shot prompts, including multiple example schemas, are included in the appendix. For prompting Llama2 chat versions, we used a version recommended here (see example below).
The Five Use Cases in Data Observability: Effective Data Anomaly Monitoring (#2) Introduction Ensuring the accuracy and timeliness of data ingestion is a cornerstone for maintaining the integrity of datasystems. Have all the source files/data arrived on time? Is the source data of expected quality?
Modern datasystems often append new columns to accommodate additional information, necessitating downstream tables to adjust accordingly. Data pipeline should be robust enough that it should read the multiple file structure at run time and ingest them in a same table.
Mistake #2: Creating separate Schema Registry instances within a company. Separate schema registries may not stay separated forever. Over time, organizations restructure, project scopes change, and an end system that was used by one application may now be used by multiple applications.
Parquet vs ORC vs Avro vs Delta Lake Photo by Viktor Talashuk on Unsplash The big data world is full of various storage systems, heavily influenced by different file formats. These are key in nearly all data pipelines, allowing for efficient data storage and easier querying and information extraction.
release of Grouparoo is a huge step forward for data engineers using Grouparoo to reliably sync a variety of types of data to operational tools. Models enable Grouparoo to work with multiple dataschemas at once. Each profile mapped to a person in the system. Here are the key features of the release.
Data lakes, data warehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing.
Data lakes, data warehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing.
Data lakes, data warehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing.
As the name suggests, a DevOps professional is responsible not only for developing systems but also for securing, scaling, and maintaining them. There were a couple of challenges because it’s easy to break this type of pipeline and an analyst would work for quite a while to find the data he’s looking for.”
machine learning , allowing for analyzing the knowledge contained in the source data and generating new knowledge. The logical basis of RDF is extended by related standards RDFS (RDF Schema) and OWL (Web Ontology Language). Knowledge graphs for organizing data over the internet. Recommender systems in entertainment.
And what separates the winning businesses on the other side of this pandemic will be how intelligently they use that data to increase user engagement. These are systems of intelligence that Jerry Chen, partner at Greylock describes. What is a system of intelligence and why is it so defensible?
ELT offers a solution to this challenge by allowing companies to extract data from various sources, load it into a central location, and then transform it for analysis. The ELT process relies heavily on the power and scalability of modern data storage systems. The data is loaded as-is, without any transformation.
This framework opens the door for various optimization techniques from the existing data stream management system (DSMS) and data stream processing literature. addSink(" SinkProcessor" , "output" , "MappingProcessor" ); System. build(properties); System. With the release of Apache Kafka ® 2.1.0, println(builder.
After launching our partnership with Databricks last year, Monte Carlo has aggressively expanded our native Databricks and Apache Spark™ integrations to extend data observability into the Delta Lake and Unity Catalog, and in the process, drive even more value for Databricks customers.
In data-driven organizations, to fulfill its charter to democratize data and provide on-demand, quality computing services in a secure, compliant environment, IT must replace legacy approaches and update technologies. There needs to emerge data-first, self-service replacement for these old systems. billion dollars.’.
show(truncate=False) #Drop duplicates on selected columns dropDisDF = df.dropDuplicates(["department","salary"]) print("Distinct count of department salary : "+str(dropDisDF.count())) dropDisDF.show(truncate=False) } Get FREE Access to Data Analytics Example Codes for Data Cleaning, Data Munging, and Data Visualization Q6.
Second, if the partition number is increased after the system goes live, the default Kafka partitioner will return different numbers evenly if you provide the same key, which means messages with the same key as before will be in a different partition from the previous one. . > Schema Management. > Minutes.
It is designed to support business intelligence (BI) and reporting activities, providing a consolidated and consistent view of enterprise data. Data warehouses are typically built using traditional relational database systems, employing techniques like Extract, Transform, Load (ETL) to integrate and organize data.
The Data Mesh architecture is based on four core principles: scalability, resilience, elasticity, and autonomy. Data mesh technology also employs event-driven architectures and APIs to facilitate the exchange of data between different systems.
A software development environment (SDE) is an operating setup or system framework applied in easing, writing, testing, and deployment of applications in a quick manner. It can also leverage other tools, including version control systems and software testing applications, to maintain the quality and efficiency of the developed software.
Also, it was based on Zalando's "Mosaic" system architecture, which was being phased out in favour of the newer Interface Framework. Interface Framework - To integrate the tool with Zalando's new architecture and design system, to leverage its capabilities and scale with it. However, it had many limitations affecting scalability.
Long gone are the days when employees would use old school ERP systems to reorder supplies. No, these days all of the coffee beans, cups, and pastries are tracked and reordered constantly through a fully automated system harvesting sales from the cash registers as soon as they are rung up. Destination: Data Apps and Microservices.
What does a data engineer do – details The architecture that a data engineer will be working on can include many components. The architecture can include relational or non-relational data sources, as well as proprietary systems and processing tools. Earlier we mentioned ETL or extract, transform, load.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content