This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The complexity of information storage technologies increases exponentially with the growth of data. From physical hard drives to cloud computing, unravel the captivating world of datastorage and recognize its ever-evolving role in our […] The post What is DataStorage and How is it Used?
It provides high-throughput access to data and is optimized for […] The post A Dive into the Basics of Big DataStorage with HDFS appeared first on Analytics Vidhya. It is a core component of the Apache Hadoop ecosystem and allows for storing and processing large datasets across multiple commodity servers.
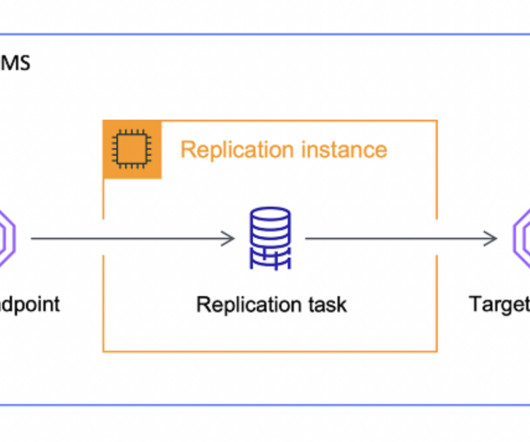
Whether it was moving data from a local database instance to S3 or some other datastorage layer. As… Read more The post What Is AWS DMS And Why You Shouldn’t Use It As An ELT appeared first on Seattle Data Guy. It was interesting to see AWS DMS used in this manner. But it’s not what DMS was built for.
In this article we are discussing that HDF5 is one of the most popular and reliable formats for non-tabular, numerical data. This article suggests what kind of ML native data format should be to truly serve the needs of modern data scientists. But this format is not optimized for deep learning work.
From Oracle, to NoSQL databases, and beyond, read about data management solutions from the early days of the RBDMS to those supporting AI applications.
Due to its lack of POSIX conformance, some believe it to be datastorage instead. Introduction The Hadoop Distributed File System (HDFS) is a Java-based file system that is Distributed, Scalable, and Portable. HDFS and […] The post Top 10 Hadoop Interview Questions You Must Know appeared first on Analytics Vidhya.
You know, for all the hoards of content, books, and videos produced in the “Data Space” over the last few years, famous or others, it seems I find there are volumes of information on the pieces and parts of working in Data. appeared first on Confessions of a Data Guy.
Introduction Apache Flume is a tool/service/data ingestion mechanism for gathering, aggregating, and delivering huge amounts of streaming data from diverse sources, such as log files, events, and so on, to centralized datastorage. Flume is a tool that is very dependable, distributed, and customizable.
Introduction In this constantly growing era, the volume of data is increasing rapidly, and tons of data points are produced every second. Now, businesses are looking for different types of datastorage to store and manage their data effectively.
When you click on a show in Netflix, you’re setting off a chain of data-driven processes behind the scenes to create a personalized and smooth viewing experience. As soon as you click, data about your choice flows into a global Kafka queue, which Flink then uses to help power Netflix’s recommendation engine.
Imagine you’ve been building houses with a hammer and nails for most of your career, and I gave you a nail gun. But instead of pressing it to the wood and pulling the trigger, you turn it sideways and hit the nail with the gun as if it were a hammer.
Datastorage has been evolving, from databases to data warehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
A comparative overview of data warehouses, data lakes, and data marts to help you make informed decisions on datastorage solutions for your data architecture.
Key parts of data systems: 2.1. Data flow design 2.3. Data processing design 2.5. Datastorage design 2.7. Introduction If you are trying to break into (or land a new) data engineering job, you will inevitably encounter a slew of data engineering tools. Introduction 2. Requirements 2.2. Conclusion 1.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Though basic and easy to use, traditional table storage formats struggle to keep up. Track data files within the table along with their column statistics. Contact phData Today!
In my recent blog, I researched OLAP technologies, for this post I chose some open-source technologies and used them together to build a full data architecture for a Data Warehouse system. I went with Apache Druid for datastorage, Apache Superset for querying and Apache Airflow as a task orchestrator.
The focus has also been hugely centred on compute rather than datastorage and analysis. In reality, enterprises need their data and compute to occur in multiple locations, and to be used across multiple time frames — from real time closed-loop actions, to analysis of long-term archived data.
For full-stack data science mastery, you must understand data management along with all the bells and whistles of machine learning. This high-level overview is a road map for the history and current state of the expansive options for datastorage and infrastructure solutions.
There are dozens of data engineering tools available on the market, so familiarity with a wide variety of these can increase your attractiveness as an AI data engineering candidate. DataStorage Solutions As we all know, data can be stored in a variety of ways.
This switch has been lead by modern data stack vision. In terms of paradigms before 2012 we were doing ETL because storage was expensive, so it became a requirement to transform data before the datastorage—mainly a data warehouse, to have the most optimised data for querying.
Storage We need efficient data-storage solutions to store the vast amounts of data used in model training. This involves investing in high-capacity and high-speed storage technologies and developing new data-storage solutions for specific workloads.
For example, the datastorage systems and processing pipelines that capture information from genomic sequencing instruments are very different from those that capture the clinical characteristics of a patient from a site. A conceptual architecture illustrating this is shown in Figure 3.
Prior to making a decision, an organization must consider the Total Cost of Ownership (TCO) for each potential data warehousing solution. On the other hand, cloud data warehouses can scale seamlessly. Vertical scaling refers to the increase in capability of existing computational resources, including CPU, RAM, or storage capacity.
[link] Sneha Ghantasala: Slow Reads for S3 Files in Pandas & How to Optimize it DeepSeek’s Fire-Flyer File System (3FS) re-triggers the importance of an optimized file system for efficient data processing.
Sustainable Data Practices These services could then make it possible for a more environmentally friendly way of handling data to be created and spread, leading to more environmentally friendly data practices.
StorageStorage plays an important role in AI training, and yet is one of the least talked-about aspects. As the GenAI training jobs become more multimodal over time, consuming large amounts of image, video, and text data, the need for datastorage grows rapidly.
Each of these technologies has its own strengths and weaknesses, but all of them can be used to gain insights from large data sets. As organizations continue to generate more and more data, big data technologies will become increasingly essential. Let's explore the technologies available for big data.
Handling Parquet Data with Schema Evolution Let’s now look at how schema evolution works with Parquet files. Parquet is a columnar storage format, often used for its efficient datastorage and retrieval. We create a table Accessory_parquet and load data from the Parquet file Accessory_day1.parquet
In-flight transformation also enables a simplified and scalable data architecture that has many related benefits including: Minimizing ETL workloads by performing transformations while data is in motion Optimizing datastorage by filtering out unnecessary data Enabling end-to-end recoverability and full resiliency without needing to handle many different (..)
Such a status has yet to be granted and without which, data transfers between the UK and the EU will not be lawfully permitted post-December 31st 2020. Without an agreed legislative route to allow datastorage and processing in the US and EU, the UK Government will be left with one option; storage and processing within the UK only.
I'd say that Iceberg (or table formats) are probably one of the technology that will incrementally change for the better the way we write data pipelines. Providing more control over datastorage. Yet I think Iceberg is not yet ready to be widely used ( Python write support still missing, you need Spark).
I'd say that Iceberg (or table formats) are probably one of the technology that will incrementally change for the better the way we write data pipelines. Providing more control over datastorage. Yet I think Iceberg is not yet ready to be widely used ( Python write support still missing, you need Spark).
This approach is fantastic when you’re not quite sure how you’ll need to use the data later, or when different teams might need to transform it in different ways. It’s more flexible than ETL and works great with the low cost of modern datastorage.
It stores all the metadata created within a ThoughtSpot instance to enable efficient querying, retrieval, and management of data objects. While Atlas operates as an in-memory graph database for speed and performance, it uses PostgreSQL as its persistent storage layer to ensure durability and long-term datastorage.
Cloud providers can offer you access to the infrastructures such as database services, servers, networks, data management , and datastorage. It includes resources such as software, servers, databases, datastorage, and networking. Software Cloud service providers offer ready-to-use applications to businesses.
Hybrid Horses for Courses: The Right Cloud for AI from Pilot to Production at Scale Later, on May 14 at 12:40 pm BST , hear from Mark Samson, one of Cloudera’s solutions engineering directors, on whether a data center or cloud deployment is best for your organization’s data platform and architecture.
The CDC approach addresses challenges like time travel, data validation, performance, and cost by replicating operational data to an AWS S3-based Iceberg Data Lake. The new system automates validation, reduces operational costs by 6x, decreases datastorage needs by 1024x, and improves data pipeline performance by 40%.
Managing the data that represents organizational knowledge is easy for any developer and does not require exhaustive cycles of data science work. Utilizing Pinecone for vector datastorage over an in-house open-source vector store can be a prudent choice for organizations.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content