This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction In this constantly growing era, the volume of data is increasing rapidly, and tons of data points are produced every second. Now, businesses are looking for different types of datastorage to store and manage their data effectively.
A comparative overview of datawarehouses, data lakes, and data marts to help you make informed decisions on datastorage solutions for your data architecture.
Datastorage has been evolving, from databases to datawarehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
dbt Core is an open-source framework that helps you organise datawarehouse SQL transformation. dbt was born out of the analysis that more and more companies were switching from on-premise Hadoop data infrastructure to cloud datawarehouses. This switch has been lead by modern data stack vision.
However, this is still not common in the DataWarehouse (DWH) field. In my recent blog, I researched OLAP technologies, for this post I chose some open-source technologies and used them together to build a full data architecture for a DataWarehouse system. Why is this?
In this post, we will be particularly interested in the impact that cloud computing left on the modern datawarehouse. We will explore the different options for data warehousing and how you can leverage this information to make the right decisions for your organization. Understanding the Basics What is a DataWarehouse?
With instant elasticity, high-performance, and secure data sharing across multiple clouds , Snowflake has become highly in-demand for its cloud-based datawarehouse offering. As organizations adopt Snowflake for business-critical workloads, they also need to look for a modern data integration approach.
This article looks at the options available for storing and processing big data, which is too large for conventional databases to handle. There are two main options available, a data lake and a datawarehouse. What is a DataWarehouse? What is a Data Lake?
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Though basic and easy to use, traditional table storage formats struggle to keep up. Track data files within the table along with their column statistics.
Two popular approaches that have emerged in recent years are datawarehouse and big data. While both deal with large datasets, but when it comes to datawarehouse vs big data, they have different focuses and offer distinct advantages.
There are dozens of data engineering tools available on the market, so familiarity with a wide variety of these can increase your attractiveness as an AI data engineering candidate. DataStorage Solutions As we all know, data can be stored in a variety of ways.
Snowflake was founded in 2012 around its datawarehouse product, which is still its core offering, and Databricks was founded in 2013 from academia with Spark co-creator researchers, becoming Apache Spark in 2014. Databricks is focusing on simplification (serverless, auto BI 2 , improved PySpark) while evolving into a datawarehouse.
A brief history of datastorage The value of data has been apparent for as long as people have been writing things down. Data volume and velocity, governance, structure, and regulatory requirements have all evolved and continue to. The datawarehouse concept dates back to data marts in the 1970s.
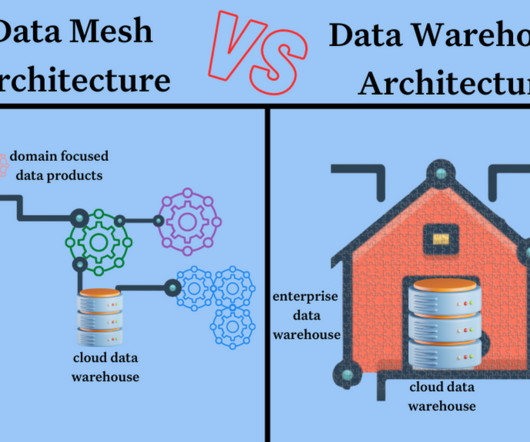
Data mesh vs datawarehouse is an interesting framing because it is not necessarily a binary choice depending on what exactly you mean by datawarehouse (more on that later). Despite their differences, however, both approaches require high-quality, reliable data in order to function. What is a Data Mesh?
That’s why it’s essential for teams to choose the right architecture for the storage layer of their data stack. But, the options for datastorage are evolving quickly. So let’s get to the bottom of the big question: what kind of datastorage layer will provide the strongest foundation for your data platform?
“Data Lake vs DataWarehouse = Load First, Think Later vs Think First, Load Later” The terms data lake and datawarehouse are frequently stumbled upon when it comes to storing large volumes of data. DataWarehouse Architecture What is a Data lake?
I'll speak about "How to build the data dream team" Let's jump onto the news. Ingredients of a DataWarehouse Going back to basics. Kovid wrote an article that tries to explain what are the ingredients of a datawarehouse. And he does it well. In the post Kovid details every idea.
[link] Get Your Guide: From Snowflake to Databricks: Our cost-effective journey to a unified datawarehouse. GetYourGuide discusses migrating its Business Intelligence (BI) data source from Snowflake to Databricks, achieving a 20% cost reduction.
Each of these technologies has its own strengths and weaknesses, but all of them can be used to gain insights from large data sets. As organizations continue to generate more and more data, big data technologies will become increasingly essential. Let's explore the technologies available for big data.
In this blog, we’ll explore the significance of schema evolution using real-world examples with CSV, Parquet, and JSON data formats. Schema evolution allows for the automatic adjustment of the schema in the datawarehouse as new data is ingested, ensuring data integrity and avoiding pipeline failures.
Striim, for instance, facilitates the seamless integration of real-time streaming data from various sources, ensuring that it is continuously captured and delivered to big datastorage targets. This method is advantageous when dealing with structured data that requires pre-processing before storage.
This centralized model mirrors early monolithic datawarehouse systems like Teradata, Oracle Exadata, and IBM Netezza. These systems provided centralized datastorage and processing at the cost of agility. Data engineering followed a similar path.
A guide to the Snowflake results cache — Cache is a critical piece to every datawarehouse either for reusing data between runs or between stages in the same run. I'd say that Iceberg (or table formats) are probably one of the technology that will incrementally change for the better the way we write data pipelines.
A guide to the Snowflake results cache — Cache is a critical piece to every datawarehouse either for reusing data between runs or between stages in the same run. I'd say that Iceberg (or table formats) are probably one of the technology that will incrementally change for the better the way we write data pipelines.
Data engineering inherits from years of data practices in US big companies. Hadoop initially led the way with Big Data and distributed computing on-premise to finally land on Modern Data Stack — in the cloud — with a datawarehouse at the center. Picking the right format for your datastorage.
This approach is fantastic when you’re not quite sure how you’ll need to use the data later, or when different teams might need to transform it in different ways. It’s more flexible than ETL and works great with the low cost of modern datastorage.
Cloudera and Accenture demonstrate strength in their relationship with an accelerator called the Smart Data Transition Toolkit for migration of legacy datawarehouses into Cloudera Data Platform. Accenture’s Smart Data Transition Toolkit . Are you looking for your datawarehouse to support the hybrid multi-cloud?
After having rebuilt their datawarehouse, I decided to take a little bit more of a pointed role, and I joined Oracle as a database performance engineer. I spent eight years in the real-world performance group where I specialized in high visibility and high impact data warehousing competes and benchmarks.
When it comes to the question of building or buying your data stack, there’s never a one-size-fits-all solution for every data team—or every component of your data stack. Datastorage and compute are very much the foundation of your data platform. Let’s jump in!
Cloudera customers run some of the biggest data lakes on earth. These lakes power mission-critical, large-scale data analytics and AI use cases—including enterprise datawarehouses. This scalability ensures the data lakehouse remains responsive and performant, even as data complexity and usage patterns change over time.
While cloud-native, point-solution datawarehouse services may serve your immediate business needs, there are dangers to the corporation as a whole when you do your own IT this way. Cloudera DataWarehouse (CDW) is here to save the day! CDW is an integrated datawarehouse service within Cloudera Data Platform (CDP).
Snowflake and Azure Synapse offer powerful data warehousing solutions that simplify data integration and analysis by providing elastic scaling and optimized query performance. These techniques minimize the amount of data that needs to be processed at any given time, leading to significant cost savings.
Why data consumers do not trust your reporting — It is a good illustration of the data journey manifesto. Stakeholders often notice data issues before the data team does. Datawarehouses are mutable, this is one of the many root causes proposed by Lucas. Data Documentation 101: Why?
You work hard to make sure that your data is clean, reliable, and reproducible throughout the ingestion pipeline, but what happens when it gets to the datawarehouse? Dataform picks up where your ETL jobs leave off, turning raw data into reliable analytics.
[link] Piethein Strengholt: Integrating Azure Databricks and Microsoft Fabric Databricks buying Tabluar certainly triggers interesting patterns in the data infrastructure. Databricks and Snowflake offer a datawarehouse on top of cloud providers like AWS, Google Cloud, and Azure. Will they co-exist or fight with each other?
Prior to data powering valuable data products like machine learning models and real-time marketing applications, datawarehouses were mainly used to create charts in binders that sat off to the side of board meetings. This pattern is repeating with AI. 2023 was the year of GPUs. 2024 was the year of foundational models.
This tool automates ELT (Extract, Load, Transform) process, integrating your data from the source system of Google Calendar to our Snowflake datawarehouse. Storage — Snowflake Snowflake, a cloud-based datawarehouse tailored for analytical needs, will serve as our datastorage solution.
Nowadays, the term is used for petabytes or even exabytes of data (1024 Petabytes), close to trillions of records from billions of people. In this fast-moving landscape, the key to making a difference is picking up the correct datastorage solution for your business. […]
With the vast amount of data being collected today for various purposes, there is an increasing need to find the proper datastorage, which also heavily depends on your specific analytical objectives. This […]
Concepts, theory, and functionalities of this modern datastorage framework Photo by Nick Fewings on Unsplash Introduction I think it’s now perfectly clear to everybody the value data can have. To use a hyped example, models like ChatGPT could only be built on a huge mountain of data, produced and collected over years.
Are you bored with writing scripts to move data into SaaS tools like Salesforce, Marketo, or Facebook Ads? Hightouch is the easiest way to sync data into the platforms that your business teams rely on. The data you’re looking for is already in your datawarehouse and BI tools. No more scripts, just SQL.
Revisiting The Current State of Data Infrastructure Let’s revisit the current state of the data infrastructure before discussing the S3 Express. There are two critical properties of datawarehouse access patterns. Data freshness matters a lot—the more recent the data, the more frequently it is accessed.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content