This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts. DataStorage Solutions As we all know, data can be stored in a variety of ways.
In this episode Davit Buniatyan, founder and CEO of Activeloop, explains why he is spending his time and energy on building a platform to simplify the work of getting your unstructureddata ready for machine learning. Are you bored with writing scripts to move data into SaaS tools like Salesforce, Marketo, or Facebook Ads?
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Though basic and easy to use, traditional table storage formats struggle to keep up. Track data files within the table along with their column statistics.
In today’s data-driven world, organizations amass vast amounts of information that can unlock significant insights and inform decision-making. A staggering 80 percent of this digital treasure trove is unstructureddata, which lacks a pre-defined format or organization. What is unstructureddata?
This article looks at the options available for storing and processing big data, which is too large for conventional databases to handle. There are two main options available, a data lake and a datawarehouse. What is a DataWarehouse? What is a Data Lake?
Two popular approaches that have emerged in recent years are datawarehouse and big data. While both deal with large datasets, but when it comes to datawarehouse vs big data, they have different focuses and offer distinct advantages.
A brief history of datastorage The value of data has been apparent for as long as people have been writing things down. Data volume and velocity, governance, structure, and regulatory requirements have all evolved and continue to. The datawarehouse concept dates back to data marts in the 1970s.
This centralized model mirrors early monolithic datawarehouse systems like Teradata, Oracle Exadata, and IBM Netezza. These systems provided centralized datastorage and processing at the cost of agility. Data engineering followed a similar path.
Prior to data powering valuable data products like machine learning models and real-time marketing applications, datawarehouses were mainly used to create charts in binders that sat off to the side of board meetings. In other words, the four ways data + AI products break: in the data, system, code, or model.
That’s why it’s essential for teams to choose the right architecture for the storage layer of their data stack. But, the options for datastorage are evolving quickly. So let’s get to the bottom of the big question: what kind of datastorage layer will provide the strongest foundation for your data platform?
Striim, for instance, facilitates the seamless integration of real-time streaming data from various sources, ensuring that it is continuously captured and delivered to big datastorage targets. This method is advantageous when dealing with structured data that requires pre-processing before storage.
“Data Lake vs DataWarehouse = Load First, Think Later vs Think First, Load Later” The terms data lake and datawarehouse are frequently stumbled upon when it comes to storing large volumes of data. DataWarehouse Architecture What is a Data lake?
Roles and Responsibilities Finding data sources and automating the data collection process Discovering patterns and trends by analyzing information Performing data pre-processing on both structured and unstructureddata Creating predictive models and machine-learning algorithms Average Salary: USD 81,361 (1-3 years) / INR 10,00,000 per annum 3.
When it comes to the question of building or buying your data stack, there’s never a one-size-fits-all solution for every data team—or every component of your data stack. Datastorage and compute are very much the foundation of your data platform. Let’s jump in!
The Awards showcase IT vendor offerings that provide significant technology advances – and partner growth opportunities – across technology categories including AI and AI infrastructure, cloud management tools, IT infrastructure and monitoring, networking, datastorage, and cybersecurity.
In our previous post, The Pros and Cons of Leading Data Management and Storage Solutions , we untangled the differences among data lakes, datawarehouses, data lakehouses, data hubs, and data operating systems. Does not have the resources to implement robust data governance and management.
In our previous post, The Pros and Cons of Leading Data Management and Storage Solutions , we untangled the differences among data lakes, datawarehouses, data lakehouses, data hubs, and data operating systems. Does not have the resources to implement robust data governance and management.
In our previous post, The Pros and Cons of Leading Data Management and Storage Solutions , we untangled the differences among data lakes, datawarehouses, data lakehouses, data hubs, and data operating systems. Does not have the resources to implement robust data governance and management.
In this post, we'll discuss some key data engineering concepts that data scientists should be familiar with, in order to be more effective in their roles. These concepts include concepts like data pipelines, datastorage and retrieval, data orchestrators or infrastructure-as-code.
IBM is one of the best companies to work for in Data Science. The platform allows not only datastorage but also deep data processing by making use of Apache Hadoop. The CDP private cloud is a scalable datastorage solution that can handle analytical and machine learning workloads.
Data lakes, datawarehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing. However, datawarehouses can experience limitations and scalability challenges.
Data lakes, datawarehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing. However, datawarehouses can experience limitations and scalability challenges.
Data lakes, datawarehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing. However, datawarehouses can experience limitations and scalability challenges.
ELT: When to Transform Your Data ETL (Extract, Transform, Load) ELT (Extract, Load, Transform) Which One Should You Choose? Batch vs. Stream Processing: How to Move Your Data Batch Processing Stream Processing Which One Should You Choose? Data Lakes vs. DataWarehouses: Where Should Your Data Live?
Data lakehouse architecture combines the benefits of datawarehouses and data lakes, bringing together the structure and performance of a datawarehouse with the flexibility of a data lake. Table of Contents What is data lakehouse architecture? The 5 key layers of data lakehouse architecture 1.
Data lakehouse architecture combines the benefits of datawarehouses and data lakes, bringing together the structure and performance of a datawarehouse with the flexibility of a data lake. Table of Contents What is data lakehouse architecture? The 5 key layers of data lakehouse architecture 1.
A Beginner’s Guide [SQ] Niv Sluzki July 19, 2023 ELT is a data processing method that involves extracting data from its source, loading it into a database or datawarehouse, and then later transforming it into a format that suits business needs. The data is loaded as-is, without any transformation.
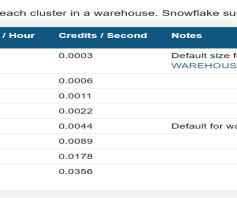
Two different data modeling approaches—dimensional data modeling and Data Vault—each have their own pros and cons. Modernizing a datawarehouse with Snowflake Data Cloud is a smart investment that can provide significant benefits to businesses of all sizes, today more than ever as data models become ever more complex.
In 2010, a transformative concept took root in the realm of datastorage and analytics — a data lake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data.
One of the innovative ways to address this problem is to build a data hub — a platform that unites all your information sources under a single umbrella. This article explains the main concepts of a data hub, its architecture, and how it differs from datawarehouses and data lakes. What is Data Hub?
Now let’s think of sweets as the data required for your company’s daily operations. Instead of combing through the vast amounts of all organizational data stored in a datawarehouse, you can use a data mart — a repository that makes specific pieces of data available quickly to any given business unit.
It offers users a data integration tool that organizes data from many sources, formats it, and stores it in a single repository, such as data lakes, datawarehouses, etc., Glue uses ETL jobs for extracting data from various AWS cloud services and integrating it into datawarehouses and lakes.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructureddata. What is a Data Lake? Consistency of data throughout the data lake.
Data lakes are useful, flexible datastorage repositories that enable many types of data to be stored in its rawest state. Traditionally, after being stored in a data lake, raw data was then often moved to various destinations like a datawarehouse for further processing, analysis, and consumption.
Data Transformation : Clean, format, and convert extracted data to ensure consistency and usability for both batch and real-time processing. Data Loading : Load transformed data into the target system, such as a datawarehouse or data lake. Used for identifying and cataloging data sources.
A growing number of companies now use this data to uncover meaningful insights and improve their decision-making, but they can’t store and process it by the means of traditional datastorage and processing units. Key Big Data characteristics. Datastorage and processing.
Enterprise datawarehouses (EDWs) became necessary in the 1980s when organizations shifted from using data for operational decisions to using data to fuel critical business decisions. Datawarehouses are popular because they help break down data silos and ensure data consistency.
With a plethora of new technology tools on the market, data engineers should update their skill set with continuous learning and data engineer certification programs. What do Data Engineers Do? Big resources still manage file data hierarchically using Hadoop's open-source ecosystem.
Azure Data Engineering is a rapidly growing field that involves designing, building, and maintaining data processing systems using Microsoft Azure technologies. As a certified Azure Data Engineer, you have the skills and expertise to design, implement and manage complex datastorage and processing solutions on the Azure cloud platform.
Job Role 1: Azure Data Engineer Azure Data Engineers develop, deploy, and manage data solutions with Microsoft Azure data services. They use many datastorage, computation, and analytics technologies to develop scalable and robust data pipelines.
In this post, we will help you quickly level up your overall knowledge of data pipeline architecture by reviewing: Table of Contents What is data pipeline architecture? Why is data pipeline architecture important? These pipelines differ from traditional ELT pipelines by doing the data cleaning and normalization prior to load.
Data engineering is a new and ever-evolving field that can withstand the test of time and computing developments. Companies frequently hire certified Azure Data Engineers to convert unstructureddata into useful, structured data that data analysts and data scientists can use.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content