This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction HDFS (Hadoop Distributed File System) is not a traditional database but a distributed file system designed to store and process big data. It provides high-throughput access to data and is optimized for […] The post A Dive into the Basics of Big DataStorage with HDFS appeared first on Analytics Vidhya.
The complexity of information storage technologies increases exponentially with the growth of data. From physical hard drives to cloud computing, unravel the captivating world of datastorage and recognize its ever-evolving role in our […] The post What is DataStorage and How is it Used?
From Oracle, to NoSQL databases, and beyond, read about data management solutions from the early days of the RBDMS to those supporting AI applications.
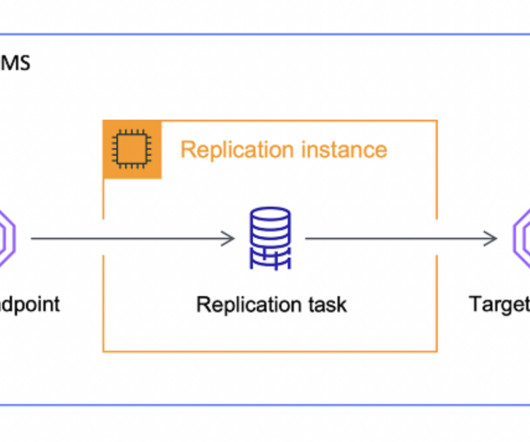
Whether it was moving data from a local database instance to S3 or some other datastorage layer. As… Read more The post What Is AWS DMS And Why You Shouldn’t Use It As An ELT appeared first on Seattle Data Guy. It was interesting to see AWS DMS used in this manner.
Datastorage has been evolving, from databases to data warehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
What is Cloudera Operational Database (COD)? Operational Database is a relational and non-relational database built on Apache HBase and is designed to support OLTP applications, which use big data. The operational database in Cloudera Data Platform has the following components: . Select Operational Database.
Summary The Cassandra database is one of the first open source options for globally scalable storage systems. The community recently released a new major version that marks a milestone in its maturity and stability as a project and database. Since its introduction in 2008 it has been powering systems at every scale.
Python is used extensively among Data Engineers and Data Scientists to solve all sorts of problems from ETL/ELT pipelines to building machine learning models. Apache HBase is an effective datastorage system for many workflows but accessing this data specifically through Python can be a struggle.
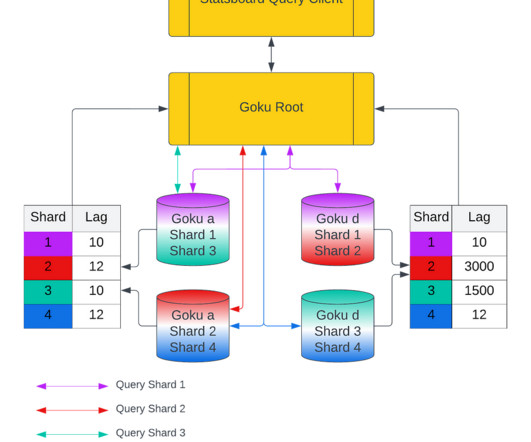
Goku is our in-house time series database providing cost efficient and low latency storage for metrics data. Goku Long Term Storage Architecture Summary and Challenges Figure 9: Flow of data from GokuS to GokuL. short, RocksDB is a key value store that uses a log structure DB engine for storage and retrieval.
Due to its lack of POSIX conformance, some believe it to be datastorage instead. Introduction The Hadoop Distributed File System (HDFS) is a Java-based file system that is Distributed, Scalable, and Portable. HDFS and […] The post Top 10 Hadoop Interview Questions You Must Know appeared first on Analytics Vidhya.
Introduction Apache Flume is a tool/service/data ingestion mechanism for gathering, aggregating, and delivering huge amounts of streaming data from diverse sources, such as log files, events, and so on, to centralized datastorage. Flume is a tool that is very dependable, distributed, and customizable.
The CDP Operational Database ( COD ) builds on the foundation of existing operational database capabilities that were available with Apache HBase and/or Apache Phoenix in legacy CDH and HDP deployments. Cloudera Machine Learning or Cloudera Data Warehouse), to deliver fast data and analytics to downstream components.
These use cases are typically the first and easiest behavior shift for data teams once they enter the cloud. They are: Moving from ETL to ELT to accelerate time-to-insight You can’t just load anything into your on-premise database– especially not if you want a query to return before you hit the weekend.
Introduction In this constantly growing era, the volume of data is increasing rapidly, and tons of data points are produced every second. Now, businesses are looking for different types of datastorage to store and manage their data effectively.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Though basic and easy to use, traditional table storage formats struggle to keep up. Track data files within the table along with their column statistics. Contact phData Today!
Agoda co-locates in all data centers, leasing space for its racks and the largest data center consumes about 1 MW of power. It uses Spark for the data platform. For transactional databases, it’s mostly the Microsoft SQL Server, but also other databases like PostgreSQL, ScyllaDB and Couchbase.
The foundational skills are similar between traditional data engineers and AI data engineers are similar, with AI data engineers more heavily focused on machine learning data infrastructure, AI-specific tools, vector databases, and LLM pipelines. Let’s dive into the tools necessary to become an AI data engineer.
A streaming ETL for Snowflake approach loads data to Snowflake from diverse sources such as transactional databases, security systems logs, and IoT sensors/devices in real time , while simultaneously meeting scalability, latency, security, and reliability requirements.
Think of a database as a smart, organized library that stores and manages information efficiently. On the other hand, data structures are like the tools that help organize and arrange data within a computer program. What is a Database? SQL, or structured query language, is widely used for writing and querying data.
This allows users to interact with their data without interruption, regardless of system scale. This article highlights the performance optimizations implemented to initialize Atlas, our in-house Graph database, in less than two minutes. What is metadata? What is Atlas?
This switch has been lead by modern data stack vision. In terms of paradigms before 2012 we were doing ETL because storage was expensive, so it became a requirement to transform data before the datastorage—mainly a data warehouse, to have the most optimised data for querying.
And so we are thrilled to introduce our latest applied ML prototype (AMP) — a large language model (LLM) chatbot customized with website data using Meta’s Llama2 LLM and Pinecone’s vector database. High-level overview of real-time data ingest with Cloudera DataFlow to Pinecone vector database.
Kovid wrote an article that tries to explain what are the ingredients of a data warehouse. A data warehouse is a piece of technology that acts on 3 ideas: the data modeling, the datastorage and processing engine. Slowly, years after years, graph databases time is coming up. And he does it well.
Each of these technologies has its own strengths and weaknesses, but all of them can be used to gain insights from large data sets. As organizations continue to generate more and more data, big data technologies will become increasingly essential. Let's explore the technologies available for big data.
Do you want a database system that can scale quickly and manage heavy workloads? Should that be the case, Azure SQL Database might be your best bet. Microsoft SQL Server's functionalities are fully included in Azure SQL Database, a cloud-based database service that also offers greater flexibility and scalability.
Back when I studied Computer Science in the early 2000s, databases like MS Access and Oracle ruled. The rise of big data and NoSQL changed the game. Systems evolved from simple to complex, and we had to split how we find data from where we store it. What Is a Database? Now, it's different. Let’s begin!
As new data comes in on day 2, we may have additional columns like PHONE and EMAIL. Handling Parquet Data with Schema Evolution Let’s now look at how schema evolution works with Parquet files. Parquet is a columnar storage format, often used for its efficient datastorage and retrieval.
Ensure the provider supports the infrastructure necessary for your data needs, such as managed databases, storage, and data pipeline services. Utilize Cloud-Native Tools: Leverage cloud-native data pipeline tools like Ascend to build and orchestrate scalable workflows.
In between the Hadoop era, the modern data stack and the machine learning revolution everyone—but me—waits for. But, funny, in the end we are still copying data from database to database by using CSVs, like 40 years ago. Don't be surprised if no ones uses data catalogs.
Report data findings to management Monitor data collection. Data Analyst Data analysts’ job is to create and maintain data systems and databases. Statistical tools are used to interpret data by the data analyst. Roles and Responsibilities Develop, design, and create data models.
Mainly Motherduck is the company providing DuckDB as a Cloud product but they are not developing DuckDB, their product is quite young but works like expected: with a simple string you can get an analytical cloud database that just works and that can be instantly replaced by a local one if needed. Providing more control over datastorage.
Mainly Motherduck is the company providing DuckDB as a Cloud product but they are not developing DuckDB, their product is quite young but works like expected: with a simple string you can get an analytical cloud database that just works and that can be instantly replaced by a local one if needed. Providing more control over datastorage.
The ingestion layer supports multiple data types and formats, including: Batch Data: Data collected and processed in discrete chunks, typically from static sources such as databases or logs. DatastorageDatastorage follows. How will we connect to the data sources?
Summary Most databases are designed to work with textual data, with some special purpose engines that support domain specific formats. TileDB is a data engine that was built to support every type of data by using multi-dimensional arrays as the foundational primitive. How is the built in data versioning implemented?
AWS provides more than 200 fully featured services which include storage, database, and computing. Some prominent cloud services offered by Alibaba Cloud include databasestorage, large-scale computing, network visualization, elastic computing, big data analytics, and management services.
Both companies have added Data and AI to their slogan, Snowflake used to be The Data Cloud and now they're The AI Data Cloud. Native CDC for Postgres and MySQL — Snowflake will be able to connect to Postgres and MySQL to natively move data from your databases to the warehouse.
The ultimate SQL guide — After the last canva on data interviews, here's a canva to learn SQL. From databases introduction to SQL writing. It covers simple SELECT and advanced concepts. This is neat. Malloy's Near Term Roadmap — I've shared recently Malloy demo , which was awesome. but I missed it).
If you’re a data engineering podcast listener, you get credits worth $3000 on an annual subscription TimescaleDB, from your friends at Timescale, is the leading open-source relational database with support for time-series data. Time-series data is time stamped so you can measure how a system is changing.
This requires a new class of datastorage which can accomodate that demand without having to rearchitect your system at each level of growth. YugabyteDB is an open source database designed to support planet scale workloads with high data density and full ACID compliance. A growing trend in database engines (e.g.
Are you spending too much of your engineering resources on creating database views, configuring database permissions, and manually granting and revoking access to sensitive data? Satori has built the first DataSecOps Platform that streamlines data access and security.
Here are some things that you should learn: Recursion Bubble sort Selection sort Binary Search Insertion Sort Databases and Cache To build a high-performance system, programmers need to rely on the cache. In addition, it is required in a database to keep track of the users' responses. to manage DBMS.
Goku is our in-house time series database that provides cost efficient and low latency storage for metrics data. The Observability team has a tool that uses this data, applies some heuristics on top (not in the scope of this document), and determines metrics which should beblocked.
Nowadays, the term is used for petabytes or even exabytes of data (1024 Petabytes), close to trillions of records from billions of people. In this fast-moving landscape, the key to making a difference is picking up the correct datastorage solution for your business. […]
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content