This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts. Let’s dive into the tools necessary to become an AI data engineer. Let’s examine a few.
In this episode Davit Buniatyan, founder and CEO of Activeloop, explains why he is spending his time and energy on building a platform to simplify the work of getting your unstructureddata ready for machine learning. Satori has built the first DataSecOps Platform that streamlines data access and security.
In today’s data-driven world, organizations amass vast amounts of information that can unlock significant insights and inform decision-making. A staggering 80 percent of this digital treasure trove is unstructureddata, which lacks a pre-defined format or organization. What is unstructureddata?
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Though basic and easy to use, traditional table storage formats struggle to keep up. Track data files within the table along with their column statistics. Contact phData Today!
Prior to data powering valuable data products like machine learning models and real-time marketing applications, data warehouses were mainly used to create charts in binders that sat off to the side of board meetings. In other words, the four ways data + AI products break: in the data, system, code, or model.
Organizations have continued to accumulate large quantities of unstructureddata, ranging from text documents to multimedia content to machine and sensor data. Comprehending and understanding how to leverage unstructureddata has remained challenging and costly, requiring technical depth and domain expertise.
In this digital age, data is king, and how we manage, analyze, and harness its power is constantly evolving. Database management, once confined to IT departments, has become a strategic cornerstone for businesses across industries. In this blog, we will talk about the future of database management.
Roles and Responsibilities Finding data sources and automating the data collection process Discovering patterns and trends by analyzing information Performing data pre-processing on both structured and unstructureddata Creating predictive models and machine-learning algorithms Average Salary: USD 81,361 (1-3 years) / INR 10,00,000 per annum 3.
NoSQL databases are the new-age solutions to distributed unstructureddatastorage and processing. The speed, scalability, and fail-over safety offered by NoSQL databases are needed in the current times in the wake of Big Data Analytics and Data Science technologies.
Given LLMs’ capacity to understand and extract insights from unstructureddata, businesses are finding value in summarizing, analyzing, searching, and surfacing insights from large amounts of internal information. Let’s explore how a few key sectors are putting gen AI to use.
Database applications have become vital in current business environments because they enable effective data management, integration, privacy, collaboration, analysis, and reporting. Database applications also help in data-driven decision-making by providing data analysis and reporting tools.
Recently, the advent of stream processing has unlocked the door for a new era in database technology. As a result, we can now analyze big chunks of data in real time, offering valuable opportunities and insights to make well-informed decisions. According to recent studies, the global database market will grow from USD 63.4
The ingestion layer supports multiple data types and formats, including: Batch Data: Data collected and processed in discrete chunks, typically from static sources such as databases or logs. DatastorageDatastorage follows. Historically, batch processing was sufficient for many use cases.
These programs and technologies include, among other things, servers, databases, networking, and datastorage. Cloud-based storage enables you to store files in a remote database as opposed to a local or proprietary hard drive. Introduction Cloud computing enables the delivery of many services over the Internet.
This is where database management systems come in handy. A database management system (DBMS) is a software system that helps organize, store and manage information efficiently. If you want to learn more about databases, check out Knowledgehut Database course. So, let's look at some top database project ideas.
They offer a high memory-to-CPU ratio, with configurations providing up to 1 Terabyte of memory, making them ideal for in-memory databases, big data analytics, and real-time processing. These instances are ideal for workloads that require high-speed local storage, such as caching, databases, and containerized applications.
They also have platforms where data scientists can share their knowledge. So, working here can give you experience in different fields of Data Science. Maintaining a massive number of databases for the landlords and the renters requires a team that is highly skilled and ready for experimentation.
Back when I studied Computer Science in the early 2000s, databases like MS Access and Oracle ruled. The rise of big data and NoSQL changed the game. Systems evolved from simple to complex, and we had to split how we find data from where we store it. What Is a Database? Now, it's different. Let’s begin!
Comparison of Snowflake Copilot and Cortex Analyst Cortex Search: Deliver efficient and accurate enterprise-grade document search and chatbots Cortex Search is a fully managed search solution that offers a rich set of capabilities to index and query unstructureddata and documents.
A trend often seen in organizations around the world is the adoption of Apache Kafka ® as the backbone for datastorage and delivery. This trend has the amazing effect of decreasing the number of SQL databases necessary to run a business, as well as creates an infrastructure capable of dealing with problems that SQL databases cannot.
In this post, we'll discuss some key data engineering concepts that data scientists should be familiar with, in order to be more effective in their roles. These concepts include concepts like data pipelines, datastorage and retrieval, data orchestrators or infrastructure-as-code.
Statistics are used by data scientists to collect, assess, analyze, and derive conclusions from data, as well as to apply quantifiable mathematical models to relevant variables. Microsoft Excel An effective Excel spreadsheet will arrange unstructureddata into a legible format, making it simpler to glean insights that can be used.
This serverless data integration service can automatically and quickly discover structured or unstructured enterprise data when stored in data lakes in Amazon S3, data warehouses in Amazon Redshift, and other databases that are a component of the Amazon Relational Database Service.
Master Nodes control and coordinate two key functions of Hadoop: datastorage and parallel processing of data. Worker or Slave Nodes are the majority of nodes used to store data and run computations according to instructions from a master node. Datastorage options. Data management and monitoring options.
Today’s platform owners, business owners, data developers, analysts, and engineers create new apps on the Cloudera Data Platform and they must decide where and how to store that data. Structured data (such as name, date, ID, and so on) will be stored in regular SQL databases like Hive or Impala databases.
Given LLMs’ capacity to understand and extract insights from unstructureddata, businesses are finding value in summarizing, analyzing, searching, and surfacing insights from large amounts of internal information. Let’s explore how a few key sectors are putting gen AI to use.
According to the World Economic Forum, the amount of data generated per day will reach 463 exabytes (1 exabyte = 10 9 gigabytes) globally by the year 2025. They should know SQL queries, SQL Server Reporting Services (SSRS), and SQL Server Integration Services (SSIS) and a background in Data Mining and Data Warehouse Design.
A growing number of companies now use this data to uncover meaningful insights and improve their decision-making, but they can’t store and process it by the means of traditional datastorage and processing units. Key Big Data characteristics. And most of this data has to be handled in real-time or near real-time.
You can swiftly provision infrastructure services like computation, storage, and databases, as well as machine learning, the internet of things, data lakes and analytics, and much more. Every day, enormous amounts of data are collected from business endpoints, cloud apps, and the people who engage with them.
Big Data NoSQL databases were pioneered by top internet companies like Amazon, Google, LinkedIn and Facebook to overcome the drawbacks of RDBMS. RDBMS is not always the best solution for all situations as it cannot meet the increasing growth of unstructureddata.
Ensuring all relevant data inputs are accounted for is crucial for a comprehensive ingestion process. In batch processing, this occurs at scheduled intervals, whereas real-time processing involves continuous loading, maintaining up-to-date data availability. Used for identifying and cataloging data sources.
Data Engineers are skilled professionals who lay the foundation of databases and architecture. Using database tools, they create a robust architecture and later implement the process to develop the database from zero. Data engineers who focus on databases work with data warehouses and develop different table schemas.
When it comes to storing large volumes of data, a simple database will be impractical due to the processing and throughput inefficiencies that emerge when managing and accessing big data. This article looks at the options available for storing and processing big data, which is too large for conventional databases to handle.
Data engineering is a new and ever-evolving field that can withstand the test of time and computing developments. Companies frequently hire certified Azure Data Engineers to convert unstructureddata into useful, structured data that data analysts and data scientists can use.
This architecture format consists of several key layers that are essential to helping an organization run fast analytics on structured and unstructureddata. Data lakehouse architecture is an increasingly popular choice for many businesses because it supports interoperability between data lake formats.
This architecture format consists of several key layers that are essential to helping an organization run fast analytics on structured and unstructureddata. Data lakehouse architecture is an increasingly popular choice for many businesses because it supports interoperability between data lake formats.
Also called datastorage areas , they help users to understand the essential insights about the information they represent. Machine Learning without data sets will not exist because ML depends on data sets to bring out relevant insights and solve real-world problems.
An ETL approach in the DW is considered slow, as it ships data in portions (batches.) The structure of data is usually predefined before it is loaded into a warehouse, since the DW is a relational database that uses a single data model for everything it stores. Data lake vs data hub. FoundationDB.
It is designed to support business intelligence (BI) and reporting activities, providing a consolidated and consistent view of enterprise data. Data warehouses are typically built using traditional relational database systems, employing techniques like Extract, Transform, Load (ETL) to integrate and organize data.
A Beginner’s Guide [SQ] Niv Sluzki July 19, 2023 ELT is a data processing method that involves extracting data from its source, loading it into a database or data warehouse, and then later transforming it into a format that suits business needs. In this phase, data is collected from various sources.
That’s why it’s essential for teams to choose the right architecture for the storage layer of their data stack. But, the options for datastorage are evolving quickly. So let’s get to the bottom of the big question: what kind of datastorage layer will provide the strongest foundation for your data platform?
In the present-day world, almost all industries are generating humongous amounts of data, which are highly crucial for the future decisions that an organization has to make. This massive amount of data is referred to as “big data,” which comprises large amounts of data, including structured and unstructureddata that has to be processed.
Data engineering is a new and evolving field that will withstand the test of time and computing advances. Certified Azure Data Engineers are frequently hired by businesses to convert unstructureddata into useful, structured data that data analysts and data scientists can use.
The need for efficient and agile data management products is higher than ever before, given the ongoing landscape of data science changes. MongoDB is a NoSQL database that’s been making rounds in the data science community. Let us see where MongoDB for Data Science can help you.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











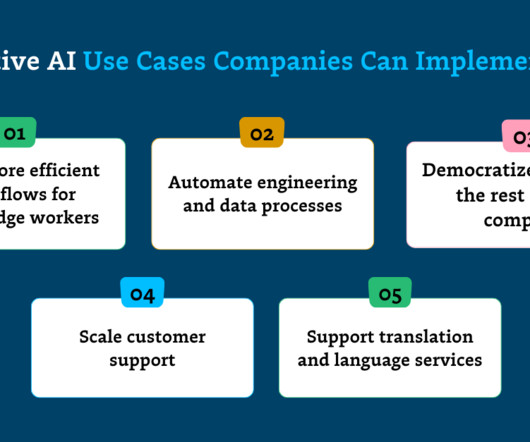






































Let's personalize your content